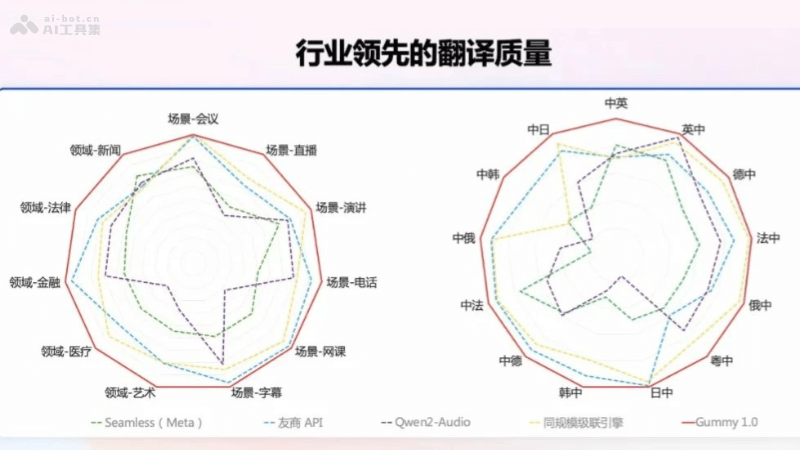
ImageBind是Meta公司推出的开源多模态AI模型,将文本、音频、视觉、温度和运动数据等六种不同类型的信息整合到一个统一的嵌入空间中。模型通过图像模态作为桥梁,实现其他模态数据的隐式对齐,无需直接的模态间配对数据。ImageBind在跨模态检索、零样本分类等任务中展现出色的性能,为创建沉浸式、多感官的AI体验提供新的可能性。
 ImageBind的主要功能多模态数据整合:将图像、文本、音频、深度信息、热成像和IMU数据等六种不同模态的数据整合到一个统一的嵌入空间中。跨模态检索:基于联合嵌入空间实现不同模态之间的信息检索,例如,根据文本描述检索相关图像或音频。零样本学习:在没有显式监督的情况下,模型对新的模态或任务进行学习,在少样本或无样本的情况下特别有用。模态对齐:通过图像模态,将其他模态的数据进行隐式对齐,使不同模态之间的信息可以相互理解和转换。生成任务:ImageBind用于生成任务,如根据文本描述生成图像,或根据音频生成图像等。ImageBind的技术原理多模态联合嵌入(Multimodal Joint Embedding):ImageBind通过训练模型来学习联合嵌入空间,联合嵌入空间将不同模态的数据(如图像、文本、音频等)映射到同一个向量空间中,使不同模态之间的信息可以相互关联和比较。模态对齐(Modality Alignment):用图像作为枢纽,将其他模态的数据与图像数据对齐。即使某些模态之间没有直接的配对数据,也能通过它们与图像的关联来实现有效的对齐。自监督学习(Self-Supervised Learning):ImageBind采用自监督学习方法,依赖于数据本身的结构和模式,而不依赖于大量的人工标注。对比学习(Contrastive Learning):对比学习是ImageBind中的核心技术之一,通过优化正样本对的相似度和负样本对的不相似度,模型能学习到区分不同数据样本的特征。ImageBind的项目地址项目官网:imagebind.metademolab.comGitHub仓库:https://github.com/facebookresearch/ImageBindarXiv技术论文:https://arxiv.org/pdf/2305.05665ImageBind的应用场景增强现实(AR)和虚拟现实(VR):在虚拟环境中,ImageBind生成与用户互动的多感官体验,比如根据用户的动作或语音指令生成相应的视觉和音频反馈。内容推荐系统:分析用户的多模态行为数据(如观看视频时的语音评论、文本评论和观看时长),ImageBind提供更个性化的内容推荐。自动标注和元数据生成:为图像、视频和音频内容自动生成描述性标签,帮助组织和检索多媒体资料库。辅助残障人士的技术:为视觉或听力受损的人士提供辅助,例如,将图像内容转换为音频描述,或将音频内容转换为可视化表示。语言学习应用:将文本、音频和图像结合起来,帮助用户在语言学习中获得更丰富的上下文信息。
ImageBind的主要功能多模态数据整合:将图像、文本、音频、深度信息、热成像和IMU数据等六种不同模态的数据整合到一个统一的嵌入空间中。跨模态检索:基于联合嵌入空间实现不同模态之间的信息检索,例如,根据文本描述检索相关图像或音频。零样本学习:在没有显式监督的情况下,模型对新的模态或任务进行学习,在少样本或无样本的情况下特别有用。模态对齐:通过图像模态,将其他模态的数据进行隐式对齐,使不同模态之间的信息可以相互理解和转换。生成任务:ImageBind用于生成任务,如根据文本描述生成图像,或根据音频生成图像等。ImageBind的技术原理多模态联合嵌入(Multimodal Joint Embedding):ImageBind通过训练模型来学习联合嵌入空间,联合嵌入空间将不同模态的数据(如图像、文本、音频等)映射到同一个向量空间中,使不同模态之间的信息可以相互关联和比较。模态对齐(Modality Alignment):用图像作为枢纽,将其他模态的数据与图像数据对齐。即使某些模态之间没有直接的配对数据,也能通过它们与图像的关联来实现有效的对齐。自监督学习(Self-Supervised Learning):ImageBind采用自监督学习方法,依赖于数据本身的结构和模式,而不依赖于大量的人工标注。对比学习(Contrastive Learning):对比学习是ImageBind中的核心技术之一,通过优化正样本对的相似度和负样本对的不相似度,模型能学习到区分不同数据样本的特征。ImageBind的项目地址项目官网:imagebind.metademolab.comGitHub仓库:https://github.com/facebookresearch/ImageBindarXiv技术论文:https://arxiv.org/pdf/2305.05665ImageBind的应用场景增强现实(AR)和虚拟现实(VR):在虚拟环境中,ImageBind生成与用户互动的多感官体验,比如根据用户的动作或语音指令生成相应的视觉和音频反馈。内容推荐系统:分析用户的多模态行为数据(如观看视频时的语音评论、文本评论和观看时长),ImageBind提供更个性化的内容推荐。自动标注和元数据生成:为图像、视频和音频内容自动生成描述性标签,帮助组织和检索多媒体资料库。辅助残障人士的技术:为视觉或听力受损的人士提供辅助,例如,将图像内容转换为音频描述,或将音频内容转换为可视化表示。语言学习应用:将文本、音频和图像结合起来,帮助用户在语言学习中获得更丰富的上下文信息。