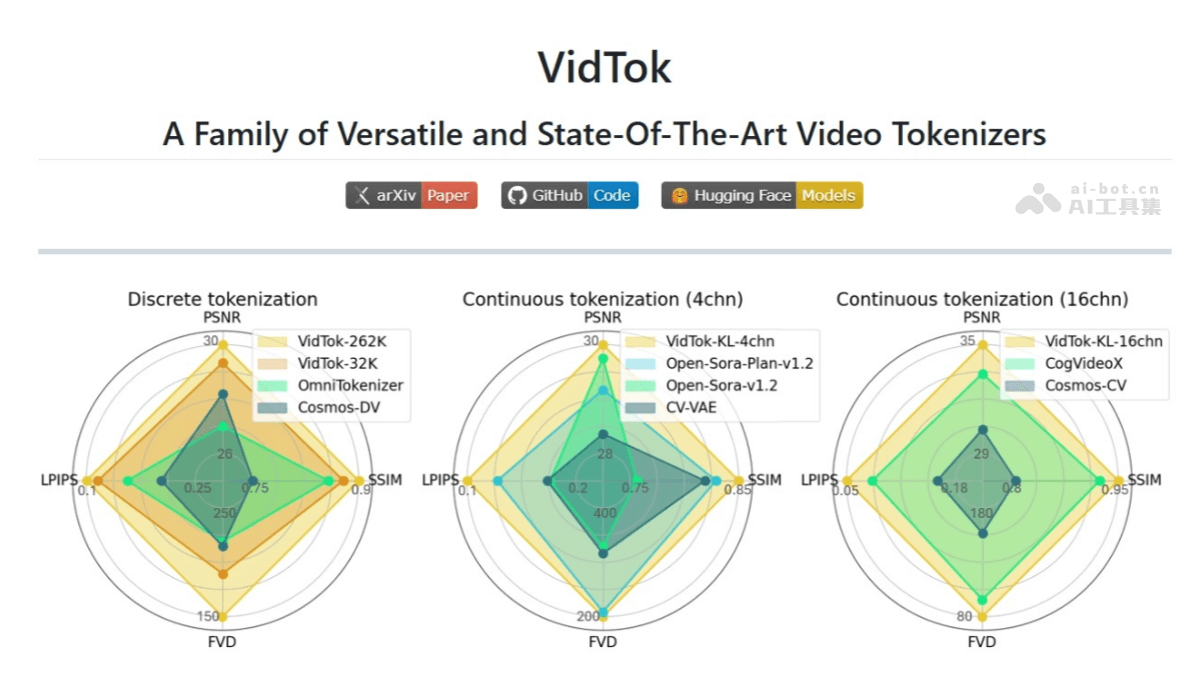
FlagEvalMM是北京智源人工智能研究院开源的多模态模型评测框架,能全面评估处理文本、图像、视频等多种模态的模型,支持多种任务和指标。框架采用评测与模型推理解耦的设计,统一视觉语言模型、文生图、文生视频和图文检索等多种模型的评测流程,提升评测效率,便于快速适配新任务和模型。
 FlagEvalMM的主要功能多模态模型支持:支持评估多种类型的多模态模型,包括视觉问答(VQA)、图像检索、文本到图像生成等。全面的基准测试和指标:支持新的和常用的基准测试和评估指标,全面衡量模型性能。模型库集成:提供模型库(model_zoo),支持多种流行多模态模型的推理,如QWenVL和LLaVA,并与基于API的模型如GPT、Claude、HuanYuan等集成。多后端支持:支持多种后端引擎进行推理,如VLLM、SGLang等,适应不同的模型和需求。FlagEvalMM的技术原理评测与模型推理解耦:FlagEvalMM将评测逻辑与模型推理逻辑分离,让评测框架独立于模型更新,提高框架的灵活性和可维护性。统一的评测架构:基于统一的架构处理不同类型的多模态模型评测,减少重复代码,提高代码的复用性。插件化设计:框架采用插件化设计,支持用户添加新的插件扩展支持的模型、任务和评估指标。后端引擎适配:框架支持多种后端引擎,基于适配层处理不同后端引擎的接口差异,让用户在不同的引擎之间无缝切换。FlagEvalMM的项目地址GitHub仓库:https://github.com/flageval-baai/FlagEvalMMFlagEvalMM的应用场景学术研究:研究人员评估和比较不同多模态模型在视觉问答、图像检索等任务上的性能,发表学术论文。工业应用:企业测试和优化自家的多模态产品,比如智能客服系统,提升用户体验。模型开发:开发者在开发新的多模态模型时,进行模型评估,确保模型在实际应用中的表现符合预期。教育领域:教育机构评估教学辅助系统中的多模态交互模型,提高教学效果。内容创作:内容创作者评估和选择适合生成图文内容的模型,提高内容创作的效率和质量。
FlagEvalMM的主要功能多模态模型支持:支持评估多种类型的多模态模型,包括视觉问答(VQA)、图像检索、文本到图像生成等。全面的基准测试和指标:支持新的和常用的基准测试和评估指标,全面衡量模型性能。模型库集成:提供模型库(model_zoo),支持多种流行多模态模型的推理,如QWenVL和LLaVA,并与基于API的模型如GPT、Claude、HuanYuan等集成。多后端支持:支持多种后端引擎进行推理,如VLLM、SGLang等,适应不同的模型和需求。FlagEvalMM的技术原理评测与模型推理解耦:FlagEvalMM将评测逻辑与模型推理逻辑分离,让评测框架独立于模型更新,提高框架的灵活性和可维护性。统一的评测架构:基于统一的架构处理不同类型的多模态模型评测,减少重复代码,提高代码的复用性。插件化设计:框架采用插件化设计,支持用户添加新的插件扩展支持的模型、任务和评估指标。后端引擎适配:框架支持多种后端引擎,基于适配层处理不同后端引擎的接口差异,让用户在不同的引擎之间无缝切换。FlagEvalMM的项目地址GitHub仓库:https://github.com/flageval-baai/FlagEvalMMFlagEvalMM的应用场景学术研究:研究人员评估和比较不同多模态模型在视觉问答、图像检索等任务上的性能,发表学术论文。工业应用:企业测试和优化自家的多模态产品,比如智能客服系统,提升用户体验。模型开发:开发者在开发新的多模态模型时,进行模型评估,确保模型在实际应用中的表现符合预期。教育领域:教育机构评估教学辅助系统中的多模态交互模型,提高教学效果。内容创作:内容创作者评估和选择适合生成图文内容的模型,提高内容创作的效率和质量。