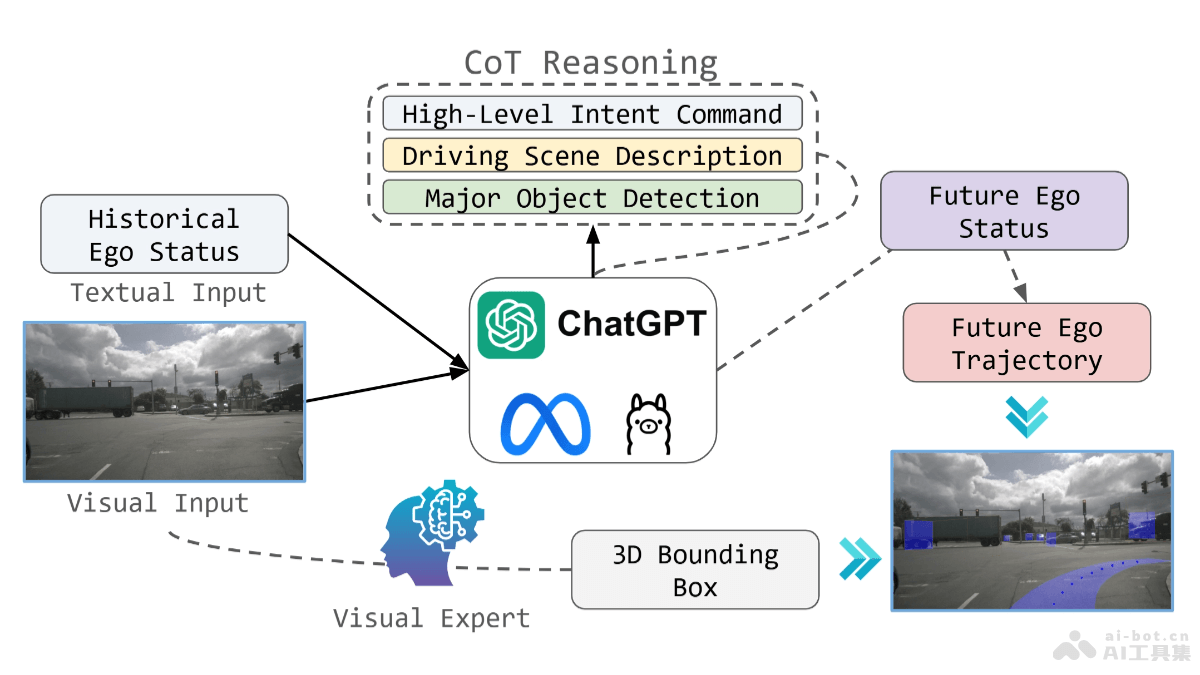
ConFiner 是一个创新的视频生成框架,由多所大学和研究机构共同推出。结合多个现成的扩散模型专家,无需额外训练可生成高质量且连贯的视频内容。框架将视频生成任务分解为结构控制、空间细化和时间细化三个子任务,每个子任务由专门的专家处理,提高生成效率和视频质量。ConFiner 引入协调去噪技术和 ConFiner-Long 框架,支持长视频的生成,制作长达600帧的连贯视频,为电影制作、动画创作和视频编辑等领域提供新的创作可能性。
 ConFiner的主要功能结构控制:负责生成视频的整体结构和情节,为后续的空间和时间细化提供基础。空间细化:确保每一帧具有足够的清晰度和高审美评分,同时保持帧与帧之间的连贯性和一致性。时间细化:进一步细化视频的时间维度,增强视频的流畅性和动态效果。协调去噪:一种新的去噪方法,支持在单次采样过程中同时使用空间和时间专家的知识,提高视频生成的精细度与一致性。长视频生成:ConFiner-Long 框架能生成长达600帧的连贯视频,通过片段一致性初始化、一致性引导和交错细化策略,确保视频片段之间的平滑过渡和连贯性。ConFiner的技术原理创新性解耦策略:ConFiner 将视频生成任务分解为三个独立的子任务:结构控制、空间细化和时间细化。每个子任务由专门的扩散模型专家处理,专家在各自领域内具有优势,降低模型的计算负担,提升了生成的质量与速度。协调去噪技术:在视频生成过程中,ConFiner 引入协作机制,使用不同噪声调度器的空间和时间专家实现逐步协作。有效提升视频生成的精细度与一致性。长视频生成突破:ConFiner-Long 框架在 ConFiner 的基础上,通过片段一致性初始化、一致性引导和交错细化三种策略,实现高质量、连贯的长视频生成。ConFiner-Long框架能生成长达600帧的连贯视频,推动长视频生成技术的发展。控制阶段与细化阶段:在控制阶段,ConFiner 用一个高度可控的文本到视频模型作为控制专家,生成包含粗略空间-时间信息的视频结构。在细化阶段,空间专家和时间专家基于视频结构来细化空间和时间细节,采用协调去噪方法,使两个专家能在不同的噪声调度器下协同工作。ConFiner的项目地址GitHub仓库:https://github.com/Confiner2025/Confiner2025arXiv技术论文:https://arxiv.org/pdf/2408.13423ConFiner的应用场景电影制作:ConFiner 生成电影的视觉草图或特效场景,帮助导演和制作团队快速预览和迭代创意,提高前期制作的效率。视频编辑:在视频编辑过程中,ConFiner 快速生成视频内容,例如添加特效或过渡,提高编辑效率并丰富最终的视频效果。动画生产:动画师用 ConFiner 生成动画序列,减少创作时间,特别是在制作动画预览或概念验证时。广告创作:广告行业用 ConFiner 生成吸引人的广告视频,快速将创意转化为视觉内容,吸引观众的注意力。社交媒体内容制作:社交媒体用户和内容创作者用 ConFiner 生产高质量的视频内容,用于平台分享,增加互动性和观看率。
ConFiner的主要功能结构控制:负责生成视频的整体结构和情节,为后续的空间和时间细化提供基础。空间细化:确保每一帧具有足够的清晰度和高审美评分,同时保持帧与帧之间的连贯性和一致性。时间细化:进一步细化视频的时间维度,增强视频的流畅性和动态效果。协调去噪:一种新的去噪方法,支持在单次采样过程中同时使用空间和时间专家的知识,提高视频生成的精细度与一致性。长视频生成:ConFiner-Long 框架能生成长达600帧的连贯视频,通过片段一致性初始化、一致性引导和交错细化策略,确保视频片段之间的平滑过渡和连贯性。ConFiner的技术原理创新性解耦策略:ConFiner 将视频生成任务分解为三个独立的子任务:结构控制、空间细化和时间细化。每个子任务由专门的扩散模型专家处理,专家在各自领域内具有优势,降低模型的计算负担,提升了生成的质量与速度。协调去噪技术:在视频生成过程中,ConFiner 引入协作机制,使用不同噪声调度器的空间和时间专家实现逐步协作。有效提升视频生成的精细度与一致性。长视频生成突破:ConFiner-Long 框架在 ConFiner 的基础上,通过片段一致性初始化、一致性引导和交错细化三种策略,实现高质量、连贯的长视频生成。ConFiner-Long框架能生成长达600帧的连贯视频,推动长视频生成技术的发展。控制阶段与细化阶段:在控制阶段,ConFiner 用一个高度可控的文本到视频模型作为控制专家,生成包含粗略空间-时间信息的视频结构。在细化阶段,空间专家和时间专家基于视频结构来细化空间和时间细节,采用协调去噪方法,使两个专家能在不同的噪声调度器下协同工作。ConFiner的项目地址GitHub仓库:https://github.com/Confiner2025/Confiner2025arXiv技术论文:https://arxiv.org/pdf/2408.13423ConFiner的应用场景电影制作:ConFiner 生成电影的视觉草图或特效场景,帮助导演和制作团队快速预览和迭代创意,提高前期制作的效率。视频编辑:在视频编辑过程中,ConFiner 快速生成视频内容,例如添加特效或过渡,提高编辑效率并丰富最终的视频效果。动画生产:动画师用 ConFiner 生成动画序列,减少创作时间,特别是在制作动画预览或概念验证时。广告创作:广告行业用 ConFiner 生成吸引人的广告视频,快速将创意转化为视觉内容,吸引观众的注意力。社交媒体内容制作:社交媒体用户和内容创作者用 ConFiner 生产高质量的视频内容,用于平台分享,增加互动性和观看率。