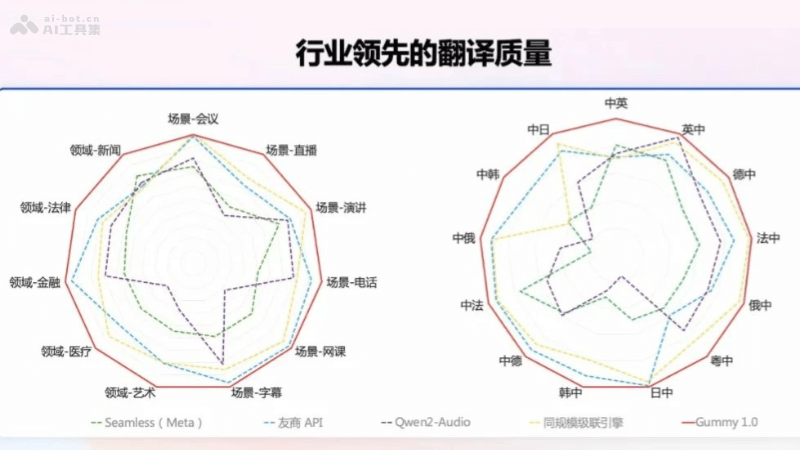
Qwen2.5 是阿里Qwen团队研发的最新一代大型语言模型系列,具有多种参数规模的模型,包括 0.5B、1.5B、3B、7B、14B、32B 和 72B。模型在预训练时使用了最新的大规模数据集,包含多达 18 万亿个 tokens,使Qwen2.5 在自然语言理解、文本生成、编程能力、数学能力等方面都有显著提升。Qwen2.5 支持长文本处理,能生成长文本(超过 8K tokens),增强对系统提示的适应性,提升角色扮演和聊天机器人的背景设置能力。Qwen2.5 还支持多达 29 种语言,包括中文、英文、法文、西班牙文、葡萄牙文、德文等。Qwen2.5-Coder 和 Qwen2.5-Math 是针对编程和数学问题的专门模型,在专业领域内展现了强大的性能。
 Qwen2.5的功能特色多样化模型规模:Qwen2.5 提供了从 0.5B 到 72B 不同参数规模的模型,满足不同应用场景的需求。预训练数据集扩展:Qwen2.5 的预训练数据集规模从 7T tokens 扩展到了 18T tokens,使模型在知识储备上有了显著提升。增强的多语言支持:Qwen2.5 支持包括中文、英文在内的超过 29 种语言,保持了对多语言的广泛支持。提升的编程和数学能力:Qwen2.5-Coder 和 Qwen2.5-Math 分别针对编程和数学问题进行了优化,提供了更专业的性能。长文本处理能力:Qwen2.5 支持高达 128K tokens 的上下文长度,能生成最多 8K tokens 的内容,增强了长文本处理的能力。结构化数据处理:新模型在理解结构化数据(例如表格)以及生成结构化输出(尤其是 JSON)方面取得了显著改进。系统提示适应性:Qwen2.5 对各种 system prompt 更具适应性,增强了角色扮演实现和聊天机器人的条件设置功能。Qwen2.5模型系列的具体参数模型及性能指标
Qwen2.5的功能特色多样化模型规模:Qwen2.5 提供了从 0.5B 到 72B 不同参数规模的模型,满足不同应用场景的需求。预训练数据集扩展:Qwen2.5 的预训练数据集规模从 7T tokens 扩展到了 18T tokens,使模型在知识储备上有了显著提升。增强的多语言支持:Qwen2.5 支持包括中文、英文在内的超过 29 种语言,保持了对多语言的广泛支持。提升的编程和数学能力:Qwen2.5-Coder 和 Qwen2.5-Math 分别针对编程和数学问题进行了优化,提供了更专业的性能。长文本处理能力:Qwen2.5 支持高达 128K tokens 的上下文长度,能生成最多 8K tokens 的内容,增强了长文本处理的能力。结构化数据处理:新模型在理解结构化数据(例如表格)以及生成结构化输出(尤其是 JSON)方面取得了显著改进。系统提示适应性:Qwen2.5 对各种 system prompt 更具适应性,增强了角色扮演实现和聊天机器人的条件设置功能。Qwen2.5模型系列的具体参数模型及性能指标Qwen2.5 模型在 MMLU-rudex 基准(考察通用知识)、MBPP 基准(考察代码能力)和 MATH 基准(考察数学能力)上的得分分别高达 86.8、88.2、83.1。
Qwen2.5:包括 0.5B、1.5B、3B、7B、14B、32B 和 72B 参数规模的模型。包含多达 18 万亿个 tokens,相比 Qwen2,整体性能提升了 18% 以上。支持高达 128K tokens 的上下文长度,能生成最多 8K tokens 的内容。支持超过 29 种语言,包括中文、英文等。Qwen2.5-Coder:专注于编程任务的模型,包括 1.5B 和 7B 参数规模。以及即将推出的 32B 版本。在多达 5.5 万亿 tokens 的编程相关数据上进行了训练。覆盖 92 种编程语言、支持 128K tokens 的上下文长度,能生成最多 8K tokens 的内容。Qwen2.5-Math:专注于数学问题的模型,包括 1.5B、7B 和 72B 参数规模。支持中文和英文,整合多种推理方法,包括思维链(CoT)、程序化思维(PoT)和工具集成推理(TIR)。解决中英双语的数学题方面表现出色 。Qwen2.5的项目地址项目官网:https://qwenlm.github.io/blog/qwen2.5/GitHub仓库:https://github.com/QwenLM/Qwen2.5HuggingFace模型库:https://huggingface.co/collections/Qwen/qwen25-66e81a666513e518adb90d9eQwen2.5的应用场景聊天机器人和虚拟助手:Qwen2.5 可以作为对话系统的核心,提供自然语言理解和文本生成,实现用户交互。内容创作和编辑:能自动生成文章、故事、诗歌或其他文本内容,辅助编辑和写作。教育和学习辅助:辅助学生和教师进行语言学习、作业辅导和知识测试。编程辅助:Qwen2.5-Coder 模型专门针对编程任务进行优化,能提供代码建议和调试帮助。数学问题解决:Qwen2.5-Math 模型支持解决中英双语的数学问题,适用于教育和研究领域。多语言翻译:需要编码器-解码器架构,Qwen2.5 也能用于生成翻译文本。