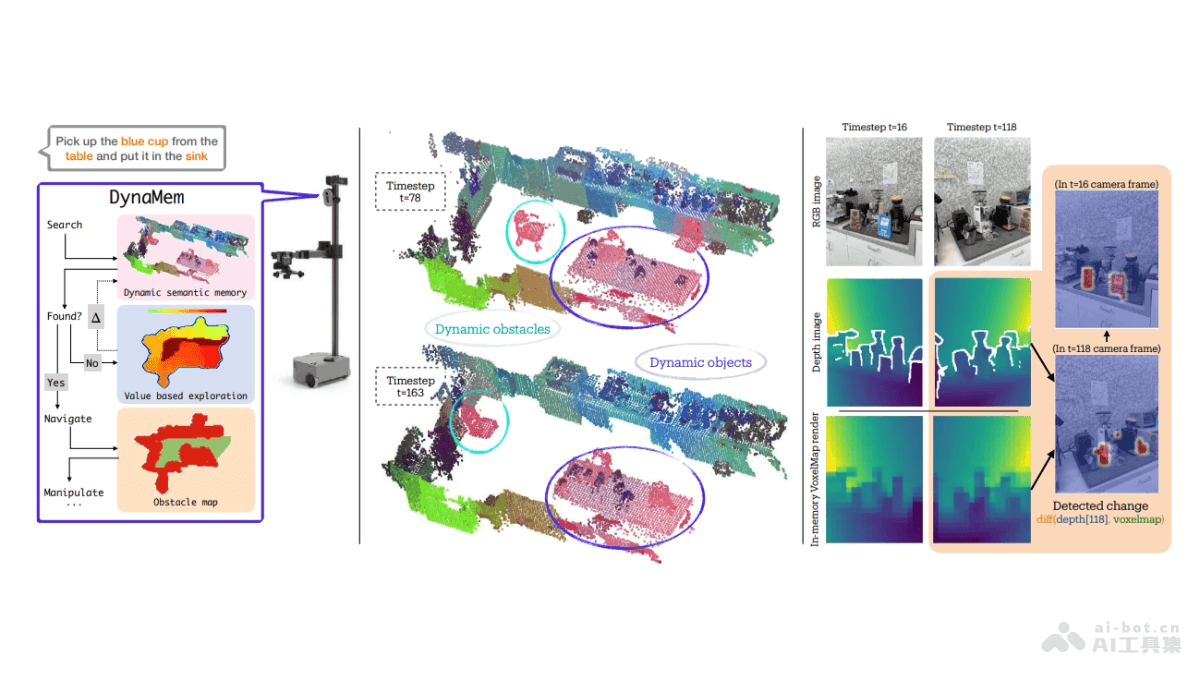
LTXV是Lightricks推出的开源AI视频生成模型,全称为LTX Video。能在4秒内生成5秒的高质量视频,速度超过观看速度。基于2亿参数的DiT架构,确保帧间平滑运动和结构一致性,解决了早期视频生成模型的关键限制。LTXV支持长视频制作,提供灵活性和控制力,适用于多种场景,包括游戏图形升级和电子商务广告变体制作。
 LTXV的主要功能实时视频生成:LTXV能快速生成视频内容,速度可实现实时视频生成,对于需要即时反馈的应用场景非常有用。高质量视频输出:模型能生成高分辨率和高帧率的视频,确保视频内容的清晰度和流畅度。运动一致性:LTXV特别强调视频帧之间的运动一致性,减少了物体变形和运动不连贯的问题,视频看起来更加自然。开源和可扩展性:作为一个开源模型,LTXV支持开发者和研究者自由地访问和修改代码,适应不同的应用需求,可以扩展到更长的视频内容生成。优化的硬件兼容性:LTXV针对广泛使用的GPU进行了优化,能在多种硬件上高效运行,特别是NVIDIA RTX系列显卡。易于集成:LTXV提供了与ComfyUI的原生支持,用户可以直接在ComfyUI Manager中使用LTXV的功能。广泛的应用场景:从游戏图形升级到电子商务广告变体制作,LTXV的应用场景广泛,能满足不同行业的需求。
LTXV的主要功能实时视频生成:LTXV能快速生成视频内容,速度可实现实时视频生成,对于需要即时反馈的应用场景非常有用。高质量视频输出:模型能生成高分辨率和高帧率的视频,确保视频内容的清晰度和流畅度。运动一致性:LTXV特别强调视频帧之间的运动一致性,减少了物体变形和运动不连贯的问题,视频看起来更加自然。开源和可扩展性:作为一个开源模型,LTXV支持开发者和研究者自由地访问和修改代码,适应不同的应用需求,可以扩展到更长的视频内容生成。优化的硬件兼容性:LTXV针对广泛使用的GPU进行了优化,能在多种硬件上高效运行,特别是NVIDIA RTX系列显卡。易于集成:LTXV提供了与ComfyUI的原生支持,用户可以直接在ComfyUI Manager中使用LTXV的功能。广泛的应用场景:从游戏图形升级到电子商务广告变体制作,LTXV的应用场景广泛,能满足不同行业的需求。创新的扩散Transformer架构:LTXV采用了扩散Transformer架构,一种新型的深度学习架构,专为视频生成任务设计,提高生成效率和质量。
LTXV的技术原理文本编码器(Text Encoder):LTXV使用文本编码器将输入的文本描述转换为高维的语义向量表示,这些向量用于指导视频生成过程。DiT(Diffusion Transformer)模型:LTXV基于DiT架构生成每一帧或多帧视频的潜在表示。DiT结合了扩散模型和Transformer架构的优势,通过模拟从噪声到数据的扩散过程,能生成高质量、逼真的视频内容。3D VAE(Variational Autoencoder):LTXV通过3D VAE解码整个视频的潜在表示,生成时空一致的视频帧序列。3D VAE通过3D卷积网络处理视频数据,增强模型对视频时空信息的处理能力。时序注意力(Temporal Attention):LTXV通过多头自注意力机制增强视频帧之间的连贯性,确保视频的流畅性和时序一致性。扩散过程:LTXV的训练使用引入了噪声的特征向量作为输入,模型的目标是学习如何逆转噪声增加的过程,即从噪声数据恢复出原始数据。视频生成:在模型训练完成后,可以通过输入噪声数据(或随机生成的噪声)到模型中,经过模型的处理后生成新的图像或视频。LTXV的项目地址Github仓库:https://github.com/Lightricks/LTX-VideoHuggingFace模型库:https://huggingface.co/Lightricks/LTX-VideoLTXV的应用场景视频制作:视频制作者可以用LTXV生成高质量的电影预告片,提升作品的视觉冲击力和吸引力。广告制作:广告制作公司可以用LTXV快速制作广告视频,满足紧急的营销活动需求,节省时间和成本。游戏开发:游戏开发者可以用LTXV生成游戏中的动态背景视频,增强游戏的沉浸感和玩家体验。在线视频平台:LTXV提供的高效视频生成能力,可以帮助在线视频平台快速产出视频内容,提高内容更新频率。电影和电视制作:电影和电视制作团队可以用LTXV生成高质量的视频内容,提高作品的质量。