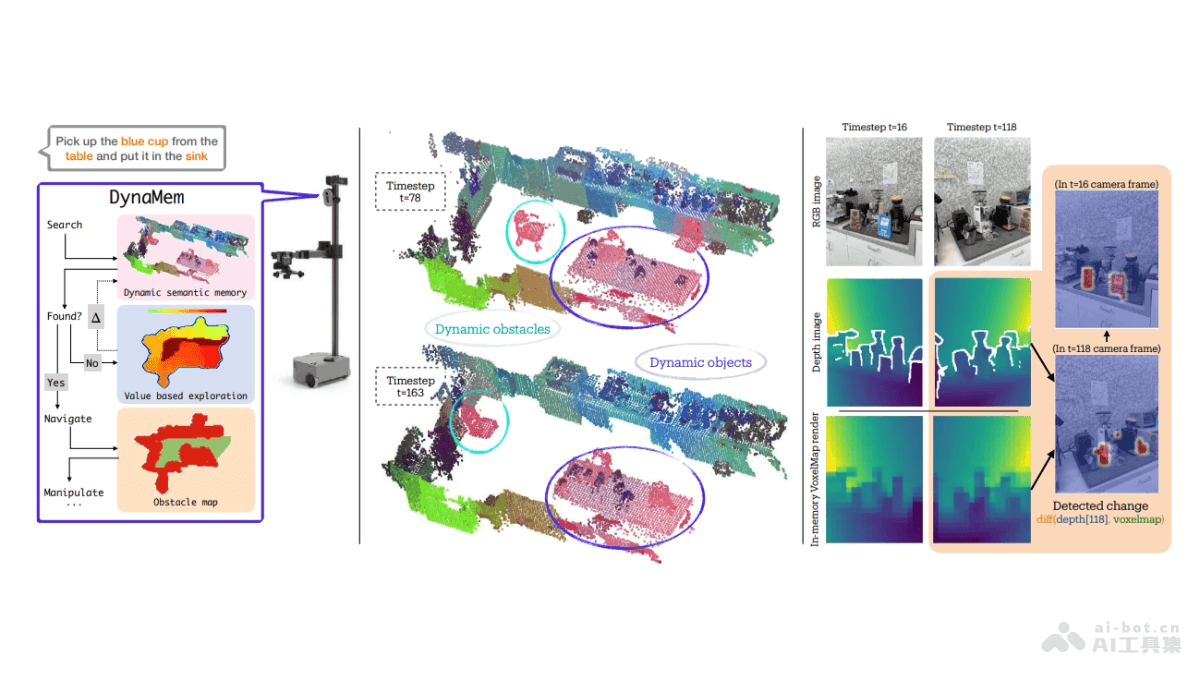
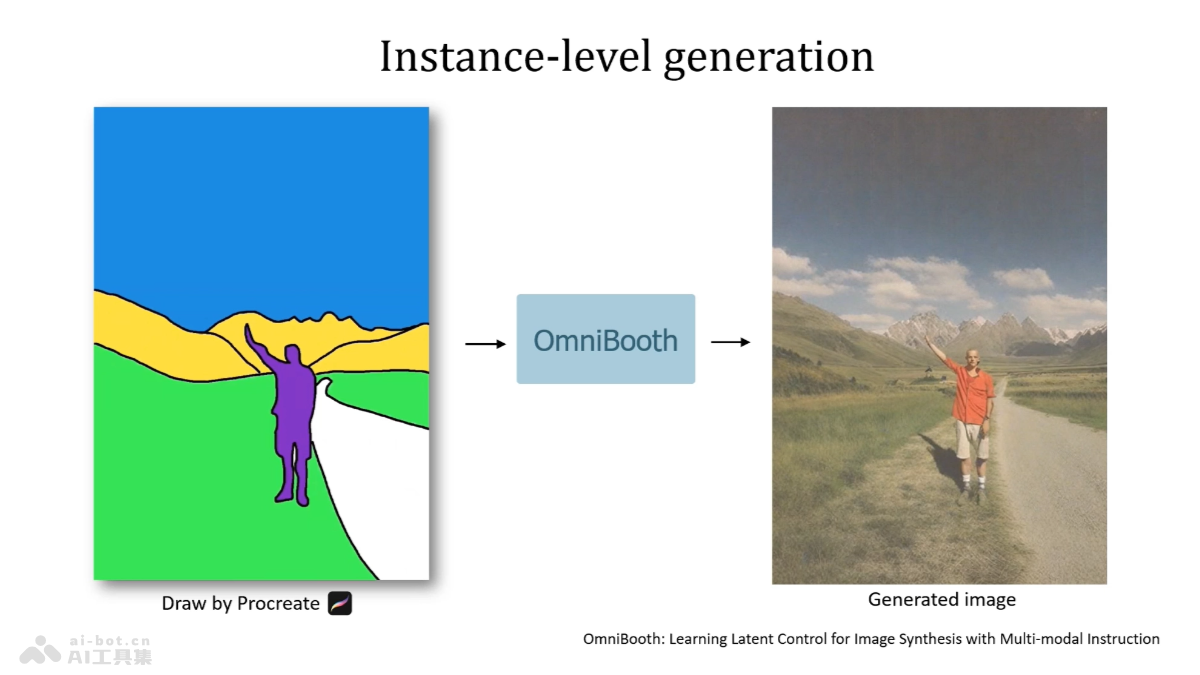
StoryMaker 是小红书开源的一款文本到图像生成工具,专注于帮助创作者在连续图像内容中保持角色的一致性。基于 Stable Diffusion XL 模型和 LoRA 技术,确保生成的图像在面部特征、服装、发型和身体特征上的高度连贯性。StoryMaker 特别适合漫画创作、游戏场景设计、故事插画和广告创意等领域,简化了多角色叙事创作的过程。用户可以通过 GitHub 和 Huggingface 平台获取 StoryMaker 的代码和预训练模型,开始自己的创意项目。
 StoryMaker的主要功能角色一致性:能准确保留每个角色在不同图像中的面部特征、服装、发型和身体特征,确保角色在连续场景中的视觉一致性。多角色处理:支持在同一场景中处理多个角色,使每个角色的特征在不同场景中保持不变,适合复杂叙事场景的创作。叙事创作:通过文本提示,StoryMaker 能生成与故事情节相符的连续图像,增强视觉叙事能力。高保真图像生成:集成了 Stable Diffusion XL 模型和 LoRA 技术,生成高质量且细节丰富的图像。个性化解决方案:提供个性化的图像生成,满足不同创作者对于角色和场景的独特需求。StoryMaker的技术原理文本到图像生成:StoryMaker 使用深度学习模型,特别是基于 Transformer 架构的大型语言模型,来理解文本描述并生成与之匹配的图像。模型通过训练学习将文本特征映射到视觉特征。Stable Diffusion XL模型:是一个先进的图像生成模型,能生成高质量和高分辨率的图像。通过扩散过程逐步优化图像,从噪声开始,逐步引入结构和细节,直到生成清晰的图像。LoRA技术(Low-Rank Adaptation):是一种模型微调技术,通过在预训练的大型模型上添加低秩矩阵来调整模型权重,在不显著增加计算负担的情况下提高模型的特定任务性能。在 StoryMaker 中,LoRA 用于增强生成图像的保真度和细节。面部特征识别与保持:StoryMaker 可能使用了面部识别技术来捕捉和编码面部特征,然后在图像生成过程中保持这些特征的一致性。涉及到复杂的图像处理和模式识别算法。StoryMaker项目地址Github仓库:https://github.com/RedAIGC/StoryMakerHuggingFace模型库:https://huggingface.co/RED-AIGC/StoryMakerarXiv技术论文:https://arxiv.org/pdf/2409.12576v1如何使用StoryMaker获取代码和模型:访问 StoryMaker 的 GitHub 仓库,克隆或下载仓库中的代码到本地环境。安装依赖:根据 GitHub 仓库中的
StoryMaker的主要功能角色一致性:能准确保留每个角色在不同图像中的面部特征、服装、发型和身体特征,确保角色在连续场景中的视觉一致性。多角色处理:支持在同一场景中处理多个角色,使每个角色的特征在不同场景中保持不变,适合复杂叙事场景的创作。叙事创作:通过文本提示,StoryMaker 能生成与故事情节相符的连续图像,增强视觉叙事能力。高保真图像生成:集成了 Stable Diffusion XL 模型和 LoRA 技术,生成高质量且细节丰富的图像。个性化解决方案:提供个性化的图像生成,满足不同创作者对于角色和场景的独特需求。StoryMaker的技术原理文本到图像生成:StoryMaker 使用深度学习模型,特别是基于 Transformer 架构的大型语言模型,来理解文本描述并生成与之匹配的图像。模型通过训练学习将文本特征映射到视觉特征。Stable Diffusion XL模型:是一个先进的图像生成模型,能生成高质量和高分辨率的图像。通过扩散过程逐步优化图像,从噪声开始,逐步引入结构和细节,直到生成清晰的图像。LoRA技术(Low-Rank Adaptation):是一种模型微调技术,通过在预训练的大型模型上添加低秩矩阵来调整模型权重,在不显著增加计算负担的情况下提高模型的特定任务性能。在 StoryMaker 中,LoRA 用于增强生成图像的保真度和细节。面部特征识别与保持:StoryMaker 可能使用了面部识别技术来捕捉和编码面部特征,然后在图像生成过程中保持这些特征的一致性。涉及到复杂的图像处理和模式识别算法。StoryMaker项目地址Github仓库:https://github.com/RedAIGC/StoryMakerHuggingFace模型库:https://huggingface.co/RED-AIGC/StoryMakerarXiv技术论文:https://arxiv.org/pdf/2409.12576v1如何使用StoryMaker获取代码和模型:访问 StoryMaker 的 GitHub 仓库,克隆或下载仓库中的代码到本地环境。安装依赖:根据 GitHub 仓库中的 README 文件或安装指南,安装必要的 Python 库和依赖,例如 transformers、torch、diffusers 等。下载预训练模型:访问 Huggingface 模型库,下载所需的预训练模型,如 Stable Diffusion XL 模型。设置环境:确保计算环境(如 CPU 或 GPU)满足模型运行的要求。配置任何必要的环境变量或路径,确保代码可以正确加载模型和资源。文本输入:准备文本描述,描述将指导模型生成图像。文本应该尽可能详细,帮助模型理解所需的图像内容。生成图像:使用 StoryMaker 提供的脚本或命令行工具,输入文本描述,启动图像生成过程。根据需要调整生成参数,如图像分辨率、样式、多样性等。后处理:生成的图像可能需要一些后处理,如裁剪、调整亮度和对比度,或者应用滤镜来达到理想的视觉效果。StoryMaker的应用场景漫画和插画创作:为漫画家和插画师提供一种快速生成角色和场景图像的方法,保持角色在连续漫画或插画系列中的一致性。游戏开发:游戏设计师可以用 StoryMaker 生成游戏角色的概念艺术,或者创建游戏环境和背景的初步视觉草图。电影和视频制作:在前期制作阶段,可以用来生成故事板和场景概念图,帮助导演和制作团队可视化电影或视频项目。广告和营销:广告创意团队可以用 StoryMaker 生成广告视觉草图,快速迭代创意概念,制作吸引人的广告图像。虚拟时尚和服装设计:设计师可以用 StoryMaker 来展示服装在不同模特身上的效果,或者尝试不同的服装设计和搭配。