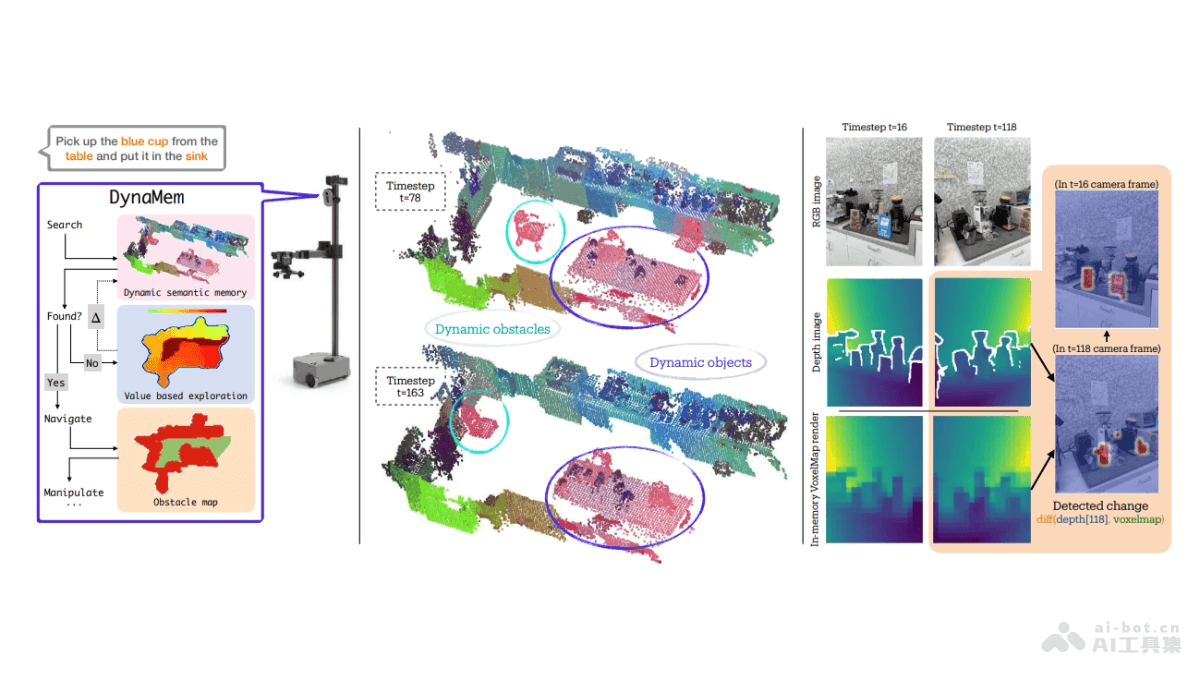
LLaMA-Omni 是中国科学院计算技术研究所和中国科学院大学研究者推出的新型模型架构,用于实现与大型语言模型(LLM)的低延迟、高质量语音交互。通过集成预训练的语音编码器、语音适配器、大型语言模型(LLM)和一个实时语音解码器,直接从语音指令中快速生成文本和语音响应,省略传统的必须先将语音转录为文本的步骤,提高了响应速度。模型基于最新的 LLaMA-3.1-8B-Instruct 模型构建,并使用自建的 InstructS2S-200K 数据集进行训练,快速生成响应,延迟低至 226 毫秒。此外,LLaMA-Omni 的训练效率高,4 个 GPU 训练不到 3 天即可完成,为未来基于最新 LLM 的语音交互模型的高效开发奠定基础。
 LLaMA-Omni的主要功能低延迟语音识别:快速从语音指令中生成响应,减少等待时间。直接语音到文本响应:无需先将语音转录为文本,直接生成文本响应。高质量的语音合成:生成文本响应的同时,能生成对应的语音输出。高效的训练过程:用较少的计算资源(如4个GPU)和较短的时间(不到3天)完成训练。流式语音解码:基于非自回归的流式 Transformer 模型,实现实时语音合成。多模态交互:结合文本和语音两种模式,提供更自然、更人性化的交互体验。LLaMA-Omni的技术原理语音编码器(Speech Encoder):基于预训练的 Whisper-large-v3 模型作为语音编码器。从用户的语音指令中提取特征表示。语音适配器(Speech Adaptor):将语音编码器的输出映射到大型语言模型(LLM)的嵌入空间。通过下采样减少序列长度,使模型处理语音输入。大型语言模型(Large Language Model, LLM):基于 Llama-3.1-8B-Instruct 作为 LLM,具有强大的文本生成能力。直接从语音指令生成文本响应,无需中间的语音到文本转录步骤。流式语音解码器(Streaming Speech Decoder):采用非自回归(NAR)的流式 Transformer 架构。用连接时序分类(CTC)预测与语音响应相对应的离散单元序列。两阶段训练策略:第一阶段:训练模型直接从语音指令生成文本响应。第二阶段:训练模型生成语音响应。数据集构建(InstructS2S-200K):包含 200K 条语音指令及对应的文本和语音响应。基于训练模型适应语音交互场景。LLaMA-Omni的项目地址GitHub仓库:https://github.com/ictnlp/LLaMA-OmniHuggingFace模型库:https://huggingface.co/ICTNLP/Llama-3.1-8B-OmniarXiv技术论文:https://arxiv.org/pdf/2409.06666LLaMA-Omni的应用场景智能助手和虚拟助手:在智能手机、智能家居设备和个人电脑上提供语音交互服务。客户服务:在呼叫中心和客户支持系统中,用于语音识别和响应来处理客户咨询和问题。教育和培训:提供语音交互式的学习体验,包括语言学习、课程讲解和互动式教学。医疗咨询:在远程医疗和健康咨询中,用语音交互提供医疗信息和建议。汽车行业:集成到车载系统中,提供语音控制的导航、娱乐和通信功能。访问性和辅助技术:帮助视障或行动不便的用户用语音交互操作设备和服务。
LLaMA-Omni的主要功能低延迟语音识别:快速从语音指令中生成响应,减少等待时间。直接语音到文本响应:无需先将语音转录为文本,直接生成文本响应。高质量的语音合成:生成文本响应的同时,能生成对应的语音输出。高效的训练过程:用较少的计算资源(如4个GPU)和较短的时间(不到3天)完成训练。流式语音解码:基于非自回归的流式 Transformer 模型,实现实时语音合成。多模态交互:结合文本和语音两种模式,提供更自然、更人性化的交互体验。LLaMA-Omni的技术原理语音编码器(Speech Encoder):基于预训练的 Whisper-large-v3 模型作为语音编码器。从用户的语音指令中提取特征表示。语音适配器(Speech Adaptor):将语音编码器的输出映射到大型语言模型(LLM)的嵌入空间。通过下采样减少序列长度,使模型处理语音输入。大型语言模型(Large Language Model, LLM):基于 Llama-3.1-8B-Instruct 作为 LLM,具有强大的文本生成能力。直接从语音指令生成文本响应,无需中间的语音到文本转录步骤。流式语音解码器(Streaming Speech Decoder):采用非自回归(NAR)的流式 Transformer 架构。用连接时序分类(CTC)预测与语音响应相对应的离散单元序列。两阶段训练策略:第一阶段:训练模型直接从语音指令生成文本响应。第二阶段:训练模型生成语音响应。数据集构建(InstructS2S-200K):包含 200K 条语音指令及对应的文本和语音响应。基于训练模型适应语音交互场景。LLaMA-Omni的项目地址GitHub仓库:https://github.com/ictnlp/LLaMA-OmniHuggingFace模型库:https://huggingface.co/ICTNLP/Llama-3.1-8B-OmniarXiv技术论文:https://arxiv.org/pdf/2409.06666LLaMA-Omni的应用场景智能助手和虚拟助手:在智能手机、智能家居设备和个人电脑上提供语音交互服务。客户服务:在呼叫中心和客户支持系统中,用于语音识别和响应来处理客户咨询和问题。教育和培训:提供语音交互式的学习体验,包括语言学习、课程讲解和互动式教学。医疗咨询:在远程医疗和健康咨询中,用语音交互提供医疗信息和建议。汽车行业:集成到车载系统中,提供语音控制的导航、娱乐和通信功能。访问性和辅助技术:帮助视障或行动不便的用户用语音交互操作设备和服务。