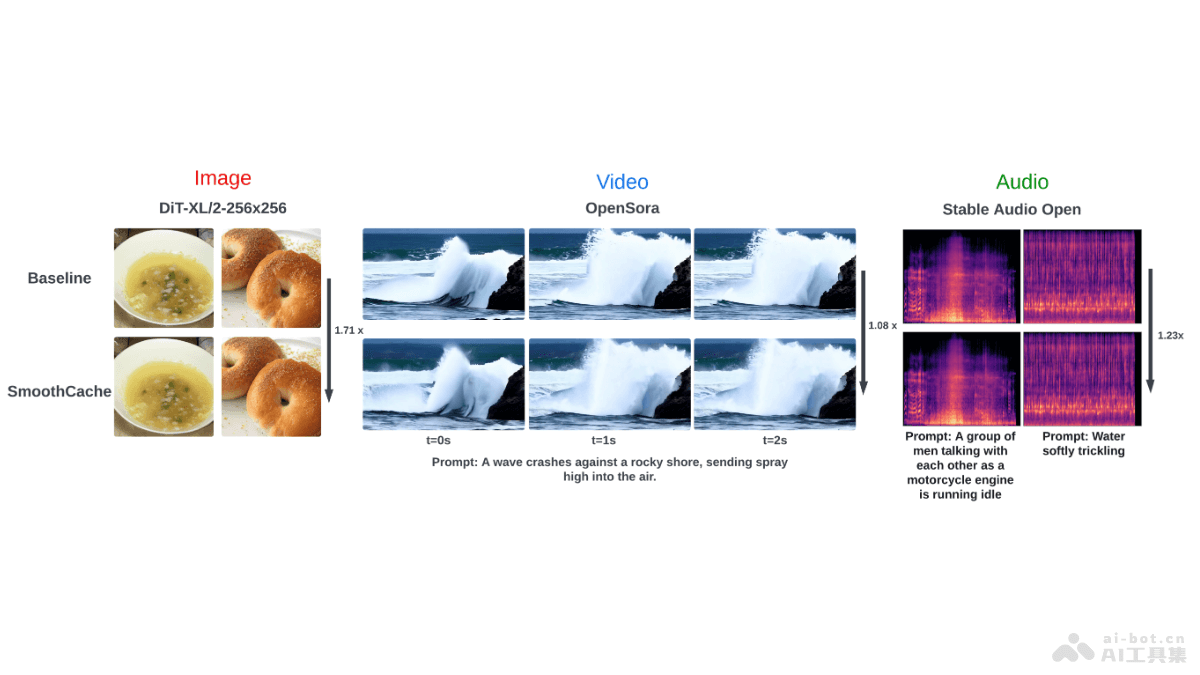
Oryx是由清华大学、腾讯和南洋理工大学联合推出的多模态大型语言模型(MLLM),基于两项核心创新来处理视觉数据,预训练的OryxViT模型和动态压缩模块。OryxViT将任意分辨率的图像编码为适合LLM的视觉表示,动态压缩模块根据需求在1到16倍之间压缩视觉标记。使Oryx能灵活地处理不同分辨率和时长的视觉输入,无论是高清图像还是超长视频。Oryx在多个视觉-语言基准测试中展现卓越的性能,特别是在空间和时间理解方面。
 Oryx的主要功能原生分辨率处理:Oryx能处理任意分辨率的视觉输入,保留图像的全部细节,适用于高精度视觉信息的任务。动态压缩:根据任务需求,Oryx能在1到16倍之间动态压缩视觉数据,处理长视频等大规模数据,提高计算效率。多模态理解:理解和分析图像、视频和3D数据,提供丰富的空间和时间理解能力,适用于多种视觉-语言任务。上下文检索:强化对视频内容的上下文理解,从广泛的上下文中检索特定信息。空间感知:Oryx能准确把握3D空间中物体的位置和关系,增强对三维空间的理解。Oryx的技术原理OryxViT模型:预训练的视觉编码器,将不同分辨率的图像转换为适合大型语言模型处理的视觉表示。自适应位置嵌入:OryxViT使用自适应位置嵌入层,允许模型处理不同大小的图像,而不需要调整到固定分辨率。变长自注意力机制:允许模型并行处理不同尺寸的视觉数据,提高处理效率和灵活性。区域注意力操作:在动态压缩模块中,用区域注意力操作交互高分辨率和低分辨率特征图,减轻下采样的影响。混合数据训练:基于包括图像、视频和3D数据的混合数据集进行训练,提高模型在多模态任务上的性能。Oryx的项目地址项目官网:oryx-mllm.github.ioGitHub仓库:https://github.com/Oryx-mllm/OryxHuggingFace模型库:https://huggingface.co/spaces/THUdyh/OryxarXiv技术论文:https://arxiv.org/pdf/2409.12961Oryx的应用场景智能监控:基于Oryx的视频理解能力,实时监控和分析监控视频中的事件和活动。自动驾驶:在自动驾驶系统中,Oryx帮助解析和理解车辆周围的环境,提供更精准的视觉识别。人机交互:Oryx能理解图像和视频内容,使人机交互更加自然和高效。内容审核:在社交媒体和在线平台上,Oryx帮助自动识别和过滤不当内容。视频编辑和增强:Oryx能自动视频编辑,如视频摘要、高光片段生成等。教育和培训:在教育领域,Oryx提供图像和视频内容的智能分析,辅助教学和学习。
Oryx的主要功能原生分辨率处理:Oryx能处理任意分辨率的视觉输入,保留图像的全部细节,适用于高精度视觉信息的任务。动态压缩:根据任务需求,Oryx能在1到16倍之间动态压缩视觉数据,处理长视频等大规模数据,提高计算效率。多模态理解:理解和分析图像、视频和3D数据,提供丰富的空间和时间理解能力,适用于多种视觉-语言任务。上下文检索:强化对视频内容的上下文理解,从广泛的上下文中检索特定信息。空间感知:Oryx能准确把握3D空间中物体的位置和关系,增强对三维空间的理解。Oryx的技术原理OryxViT模型:预训练的视觉编码器,将不同分辨率的图像转换为适合大型语言模型处理的视觉表示。自适应位置嵌入:OryxViT使用自适应位置嵌入层,允许模型处理不同大小的图像,而不需要调整到固定分辨率。变长自注意力机制:允许模型并行处理不同尺寸的视觉数据,提高处理效率和灵活性。区域注意力操作:在动态压缩模块中,用区域注意力操作交互高分辨率和低分辨率特征图,减轻下采样的影响。混合数据训练:基于包括图像、视频和3D数据的混合数据集进行训练,提高模型在多模态任务上的性能。Oryx的项目地址项目官网:oryx-mllm.github.ioGitHub仓库:https://github.com/Oryx-mllm/OryxHuggingFace模型库:https://huggingface.co/spaces/THUdyh/OryxarXiv技术论文:https://arxiv.org/pdf/2409.12961Oryx的应用场景智能监控:基于Oryx的视频理解能力,实时监控和分析监控视频中的事件和活动。自动驾驶:在自动驾驶系统中,Oryx帮助解析和理解车辆周围的环境,提供更精准的视觉识别。人机交互:Oryx能理解图像和视频内容,使人机交互更加自然和高效。内容审核:在社交媒体和在线平台上,Oryx帮助自动识别和过滤不当内容。视频编辑和增强:Oryx能自动视频编辑,如视频摘要、高光片段生成等。教育和培训:在教育领域,Oryx提供图像和视频内容的智能分析,辅助教学和学习。