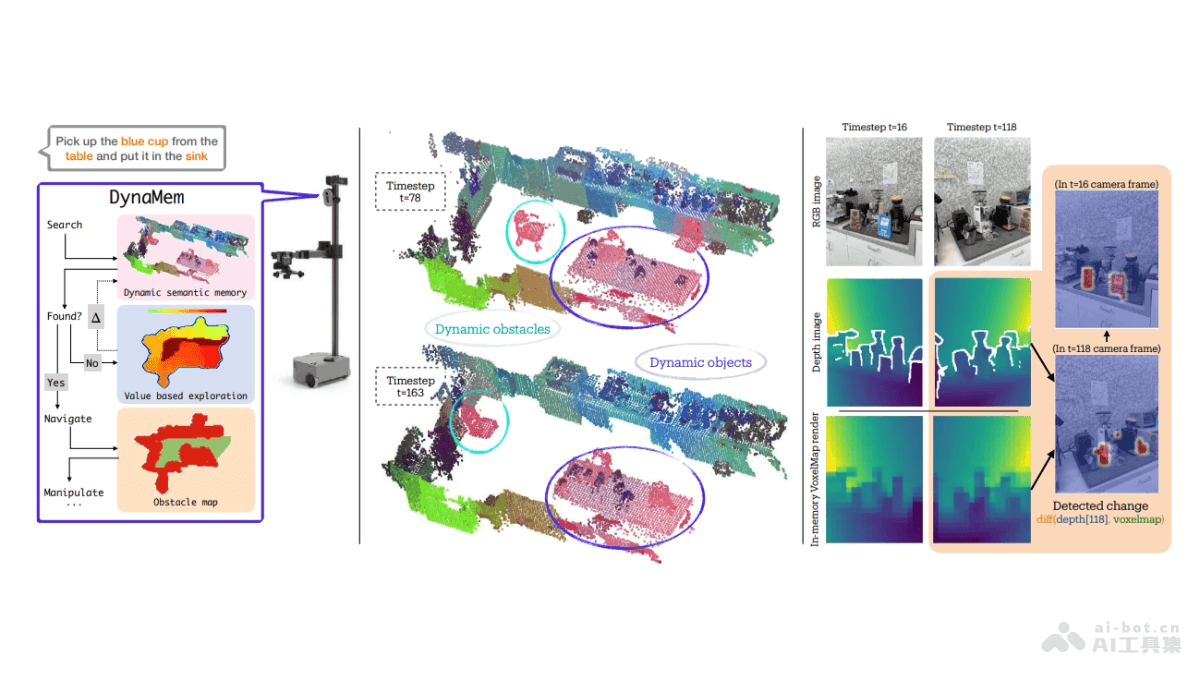
CCI 3.0是智源研究院发布的一个大规模的中文互联网语料库,包含了1000GB的数据集和498GB的高质量子集CCI 3.0-HQ。该版本在数据规模上相较于CCI 2.0扩大了近一倍,数据来源机构增加至20多家,提升了数据的覆盖面和代表性。CCI 3.0收录了超过2.68亿个网页,覆盖了新闻、社交媒体、博客等多个领域。CCI 3.0对原始数据进行了细致的分类和标记,覆盖了语法、句法、教育程度等10多个维度,筛选出高价值数据。
 CCI 3.0的主要功能数据规模和来源:CCI 3.0的数据规模达到了1000GB,包括超过2.68亿个网页,覆盖新闻、社交媒体、博客等多个领域。数据来源机构扩展至20多家,提升了数据的覆盖面和代表性 。精细标注:CCI 3.0对原始数据进行了细致的分类和标记,覆盖语法、句法、教育程度等10多个维度,筛选出高价值数据。高质量子集:CCI 3.0包含了498GB的高质量子集CCI 3.0-HQ,这是基于70B模型自动标注样本后,通过训练小尺寸质量模型得到的,能够更好地满足不同行业和应用场景的需求 。数据处理规则:在构建过程中,CCI 3.0用包括基于规则的过滤(如关键词过滤、垃圾信息过滤等)、基于模型的过滤(如低质量内容过滤)数据去重(包括数据集内部和数据集间去重)等方法,以确保数据的质量和安全性 。CCI 3.0的技术优势显著的训练效果:基于不同的数据集从零开始训练100B数据对比实验表明,CCI 3.0在单独中文语料训练和中英文语料混合训练的效果上优于其他数据集,CCI 3.0 HQ的效果更加突出 。共建共享的理念:CCI 3.0的发布推动数据共建共享,构建大规模高质量高知识密度的中文数据集,为中国人工智能产业的发展做出贡献 。便捷的获取方式:CCI 3.0的数据集可以在Flopsera、Huggingface和Datahub等平台下载,方便研究者和开发者使用 。CCI 3.0的项目地址项目官网:http://open.flopsera.com/flopsera-open/data-details/BAAI-CCI3CCI 3.0的应用场景自然语言处理(NLP)研究:CCI 3.0可以用于各种NLP任务,如文本分类、情感分析、机器翻译、问答系统和文本摘要等。大模型训练:CCI 3.0的大规模数据集适合用来训练大型语言模型,提升模型在中文语境下的表现和准确性。内容推荐系统:基于CCI 3.0中的语料数据,可以训练出更精准的用户行为预测模型,用于个性化内容推荐。知识图谱构建:通过分析CCI 3.0中的大量文本,可以提取关键信息构建知识图谱,用于增强搜索引擎、增强智能助手的知识库等。教育和学术研究:CCI 3.0可以作为学术研究的资源,帮助学者研究中文语言的特点和变化趋势。
CCI 3.0的主要功能数据规模和来源:CCI 3.0的数据规模达到了1000GB,包括超过2.68亿个网页,覆盖新闻、社交媒体、博客等多个领域。数据来源机构扩展至20多家,提升了数据的覆盖面和代表性 。精细标注:CCI 3.0对原始数据进行了细致的分类和标记,覆盖语法、句法、教育程度等10多个维度,筛选出高价值数据。高质量子集:CCI 3.0包含了498GB的高质量子集CCI 3.0-HQ,这是基于70B模型自动标注样本后,通过训练小尺寸质量模型得到的,能够更好地满足不同行业和应用场景的需求 。数据处理规则:在构建过程中,CCI 3.0用包括基于规则的过滤(如关键词过滤、垃圾信息过滤等)、基于模型的过滤(如低质量内容过滤)数据去重(包括数据集内部和数据集间去重)等方法,以确保数据的质量和安全性 。CCI 3.0的技术优势显著的训练效果:基于不同的数据集从零开始训练100B数据对比实验表明,CCI 3.0在单独中文语料训练和中英文语料混合训练的效果上优于其他数据集,CCI 3.0 HQ的效果更加突出 。共建共享的理念:CCI 3.0的发布推动数据共建共享,构建大规模高质量高知识密度的中文数据集,为中国人工智能产业的发展做出贡献 。便捷的获取方式:CCI 3.0的数据集可以在Flopsera、Huggingface和Datahub等平台下载,方便研究者和开发者使用 。CCI 3.0的项目地址项目官网:http://open.flopsera.com/flopsera-open/data-details/BAAI-CCI3CCI 3.0的应用场景自然语言处理(NLP)研究:CCI 3.0可以用于各种NLP任务,如文本分类、情感分析、机器翻译、问答系统和文本摘要等。大模型训练:CCI 3.0的大规模数据集适合用来训练大型语言模型,提升模型在中文语境下的表现和准确性。内容推荐系统:基于CCI 3.0中的语料数据,可以训练出更精准的用户行为预测模型,用于个性化内容推荐。知识图谱构建:通过分析CCI 3.0中的大量文本,可以提取关键信息构建知识图谱,用于增强搜索引擎、增强智能助手的知识库等。教育和学术研究:CCI 3.0可以作为学术研究的资源,帮助学者研究中文语言的特点和变化趋势。