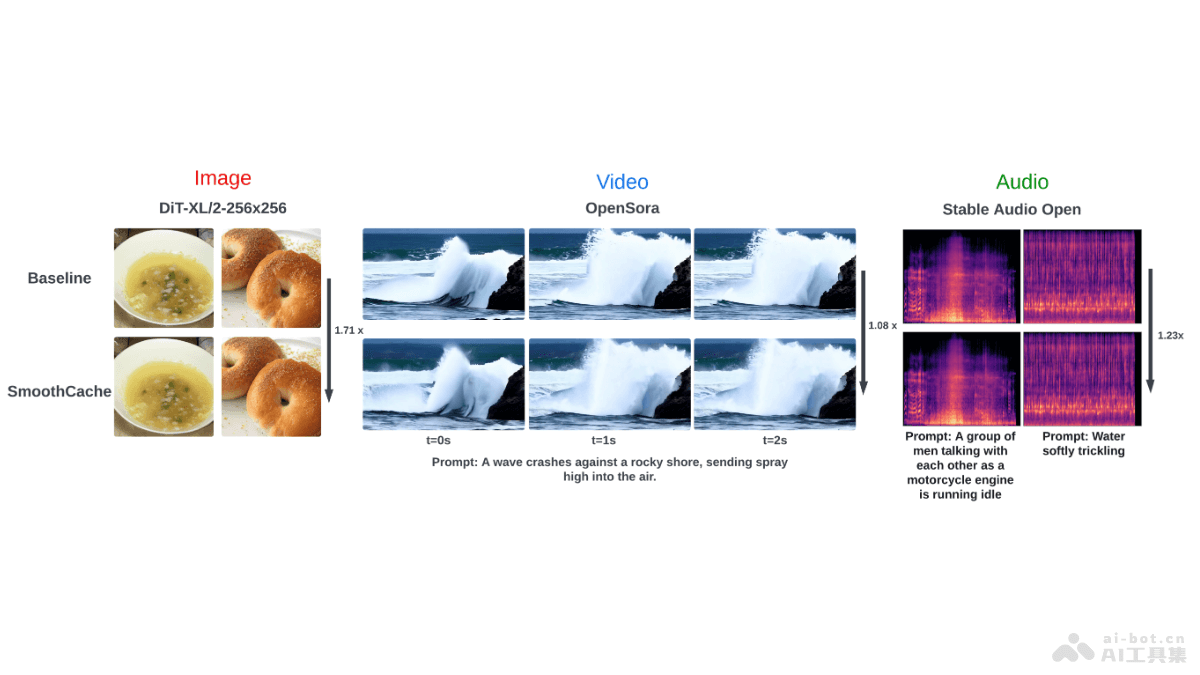
Seed-VC 是一种零样本声音转换技术,基于上下文学习实现高质量的音频输出和音色相似度。用户无需进行特定训练,只需提供1到30秒的参考语音样本,实现声音的克隆和转换。转换技术特别适合声音转换研究、娱乐、媒体制作、语音合成等场景。Seed-VC 支持零样本歌声转换,能将说话声音转换为歌声,同时保持原声音的音色特征。Seed-VC 提供命令行工具和 Gradio Web 界面,用户能轻松地进行声音转换。
 Seed-VC的主要功能零样本声音克隆:无需针对特定声音样本进行训练,即可实现声音的转换。歌声转换:将普通语音转换为歌声,适用于音乐制作和娱乐。高质量音频生成:生成清晰、自然的音频输出。音色保持:在转换过程中保持原始声音的音色特征。实时处理能力:支持实时声音转换,适用于直播和实时通信。用户友好的界面:提供命令行工具和 Web 界面,简化用户操作。Seed-VC的技术原理上下文学习:基于上下文信息理解和模仿声音特征,实现声音的转换。深度学习模型:基于深度神经网络学习和模拟声音的复杂特征。声码器技术:用声码器(如 WaveNet 或 BigVGAN)生成高质量的语音波形。特征提取:从源语音和目标参考语音中提取关键特征,如音高、音色和韵律。声音编码:将提取的声音特征编码为中间表示进行转换。声音合成:将编码后的特征解码成新的语音波形,实现声音的转换。Seed-VC的项目地址项目官网:https://plachtaa.github.io/seed-vc/GitHub仓库:https://github.com/Plachtaa/seed-vc在线体验Demo:https://huggingface.co/spaces/Plachta/Seed-VCSeed-VC的应用场景娱乐和媒体:在电影、动画、视频游戏和广播中,Seed-VC 改变或创造角色的声音,增加创意元素。音乐制作:将普通语音转换为歌声,为音乐制作人提供新的创作工具。语音合成:为文本到语音(TTS)系统提供更自然、更个性化的声音。语音识别和分析:在需要模仿特定声音或创建声音样本进行测试和验证的场景中使用。教育和培训:在语言学习中,模拟不同的声音,帮助学生更好地理解和学习发音。
Seed-VC的主要功能零样本声音克隆:无需针对特定声音样本进行训练,即可实现声音的转换。歌声转换:将普通语音转换为歌声,适用于音乐制作和娱乐。高质量音频生成:生成清晰、自然的音频输出。音色保持:在转换过程中保持原始声音的音色特征。实时处理能力:支持实时声音转换,适用于直播和实时通信。用户友好的界面:提供命令行工具和 Web 界面,简化用户操作。Seed-VC的技术原理上下文学习:基于上下文信息理解和模仿声音特征,实现声音的转换。深度学习模型:基于深度神经网络学习和模拟声音的复杂特征。声码器技术:用声码器(如 WaveNet 或 BigVGAN)生成高质量的语音波形。特征提取:从源语音和目标参考语音中提取关键特征,如音高、音色和韵律。声音编码:将提取的声音特征编码为中间表示进行转换。声音合成:将编码后的特征解码成新的语音波形,实现声音的转换。Seed-VC的项目地址项目官网:https://plachtaa.github.io/seed-vc/GitHub仓库:https://github.com/Plachtaa/seed-vc在线体验Demo:https://huggingface.co/spaces/Plachta/Seed-VCSeed-VC的应用场景娱乐和媒体:在电影、动画、视频游戏和广播中,Seed-VC 改变或创造角色的声音,增加创意元素。音乐制作:将普通语音转换为歌声,为音乐制作人提供新的创作工具。语音合成:为文本到语音(TTS)系统提供更自然、更个性化的声音。语音识别和分析:在需要模仿特定声音或创建声音样本进行测试和验证的场景中使用。教育和培训:在语言学习中,模拟不同的声音,帮助学生更好地理解和学习发音。