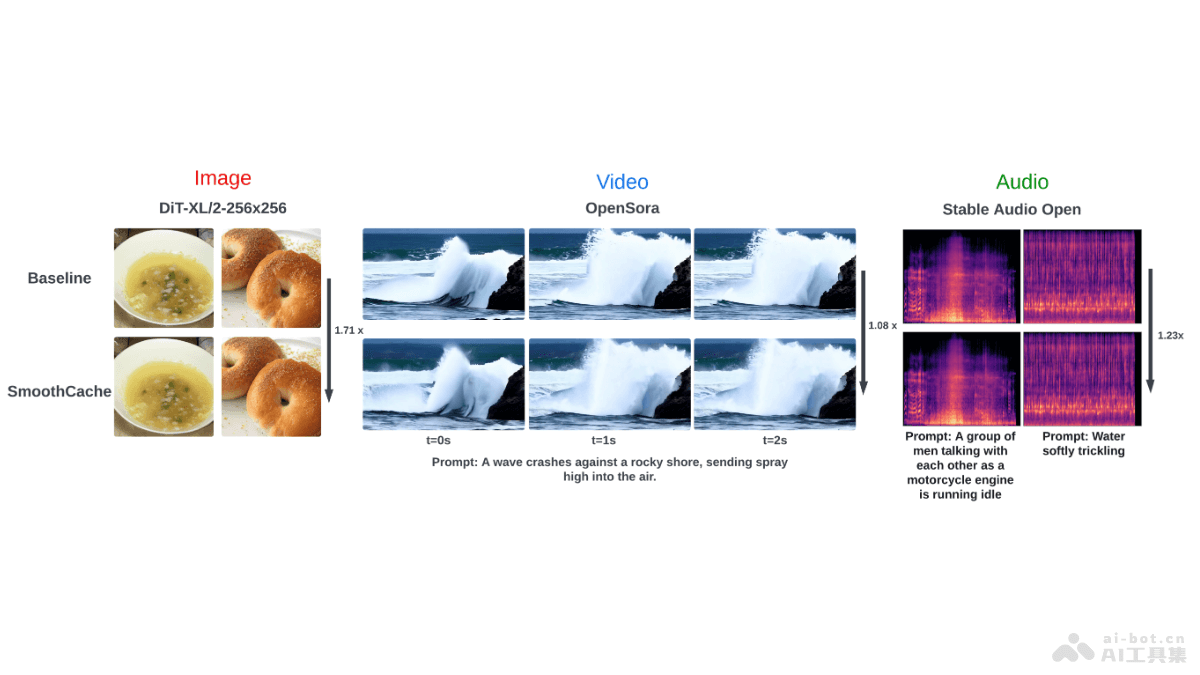
Playground v3(PGv3)是由Playground Research推出的最新文本到图像模型,基于深度融合的大型语言模型(LLM)技术,实现在图形设计任务上超越人类设计师的能力。PGv3拥有240亿参数量,能精确理解和生成复杂的图像内容,包括精确的RGB颜色控制和多语言文本生成。PGv3的模型架构是一个潜扩散模型(LDM),基于变分自编码器(VAE)和经验扩散模型(EDM)进行训练。用DiT风格的模型结构,每个Transformer块与语言模型中的对应块相同,增强提示理解和遵循能力。PGv3在文本提示遵循、复杂推理和文本渲染准确率方面表现出色,尤其在设计应用中,如表情包、海报和logo设计,展现超凡的设计能力。PGv3引入新的基准CapsBench,评估详细的图像描述性能,推动图像描述评估方法的发展。
 Playground v3的主要功能文本到图像生成:根据用户提供的文本描述生成相应的图像内容。图形设计:在设计应用中,如制作表情包、海报和logo设计,展现出超越人类设计师的能力。RGB颜色控制:支持精确的RGB颜色控制,生成具有特定颜色要求的图像。多语言支持:能理解和生成多种语言的文本,满足不同语言用户的需求。Playground v3的技术原理大型语言模型集成:PGv3集成大型语言模型(LLMs),如Llama3-8B,增强文本理解和生成能力。深度融合(Deep-Fusion)架构:基于全新的深度融合架构,用仅解码器的大型语言模型知识进行文本到图像的生成。变分自编码器(VAE):用VAE提高图像质量的上限,增强合成细节的能力。高参数量:240亿参数量使得模型能捕捉和生成更加复杂和细致的图像特征。DiT风格的模型结构:基于与语言模型中对应的Transformer块相同的结构,增强提示理解和遵循能力。U-Net跳跃连接:在Transformer块之间用U-Net跳跃连接,增强特征传递。Playground v3的项目地址HuggingFace模型库:https://huggingface.co/datasets/playgroundai/CapsBencharXiv技术论文:https://arxiv.org/pdf/2409.10695Playground v3的应用场景图形设计:用于创建海报、标志、宣传册、社交媒体图像和其他营销材料。内容创作:帮助内容创作者快速生成文章、博客或社交媒体帖子的定制图像。游戏开发:在游戏设计中,生成概念艺术、环境背景或角色设计。电影和娱乐:生成电影海报、动画背景或视觉效果的概念图。广告行业:设计广告牌、横幅广告和其他广告材料。教育和研究:生成教学材料中的插图,或帮助研究人员可视化复杂的概念。艺术创作:艺术家用PGv3探索新的艺术风格或创作数字艺术作品。
Playground v3的主要功能文本到图像生成:根据用户提供的文本描述生成相应的图像内容。图形设计:在设计应用中,如制作表情包、海报和logo设计,展现出超越人类设计师的能力。RGB颜色控制:支持精确的RGB颜色控制,生成具有特定颜色要求的图像。多语言支持:能理解和生成多种语言的文本,满足不同语言用户的需求。Playground v3的技术原理大型语言模型集成:PGv3集成大型语言模型(LLMs),如Llama3-8B,增强文本理解和生成能力。深度融合(Deep-Fusion)架构:基于全新的深度融合架构,用仅解码器的大型语言模型知识进行文本到图像的生成。变分自编码器(VAE):用VAE提高图像质量的上限,增强合成细节的能力。高参数量:240亿参数量使得模型能捕捉和生成更加复杂和细致的图像特征。DiT风格的模型结构:基于与语言模型中对应的Transformer块相同的结构,增强提示理解和遵循能力。U-Net跳跃连接:在Transformer块之间用U-Net跳跃连接,增强特征传递。Playground v3的项目地址HuggingFace模型库:https://huggingface.co/datasets/playgroundai/CapsBencharXiv技术论文:https://arxiv.org/pdf/2409.10695Playground v3的应用场景图形设计:用于创建海报、标志、宣传册、社交媒体图像和其他营销材料。内容创作:帮助内容创作者快速生成文章、博客或社交媒体帖子的定制图像。游戏开发:在游戏设计中,生成概念艺术、环境背景或角色设计。电影和娱乐:生成电影海报、动画背景或视觉效果的概念图。广告行业:设计广告牌、横幅广告和其他广告材料。教育和研究:生成教学材料中的插图,或帮助研究人员可视化复杂的概念。艺术创作:艺术家用PGv3探索新的艺术风格或创作数字艺术作品。