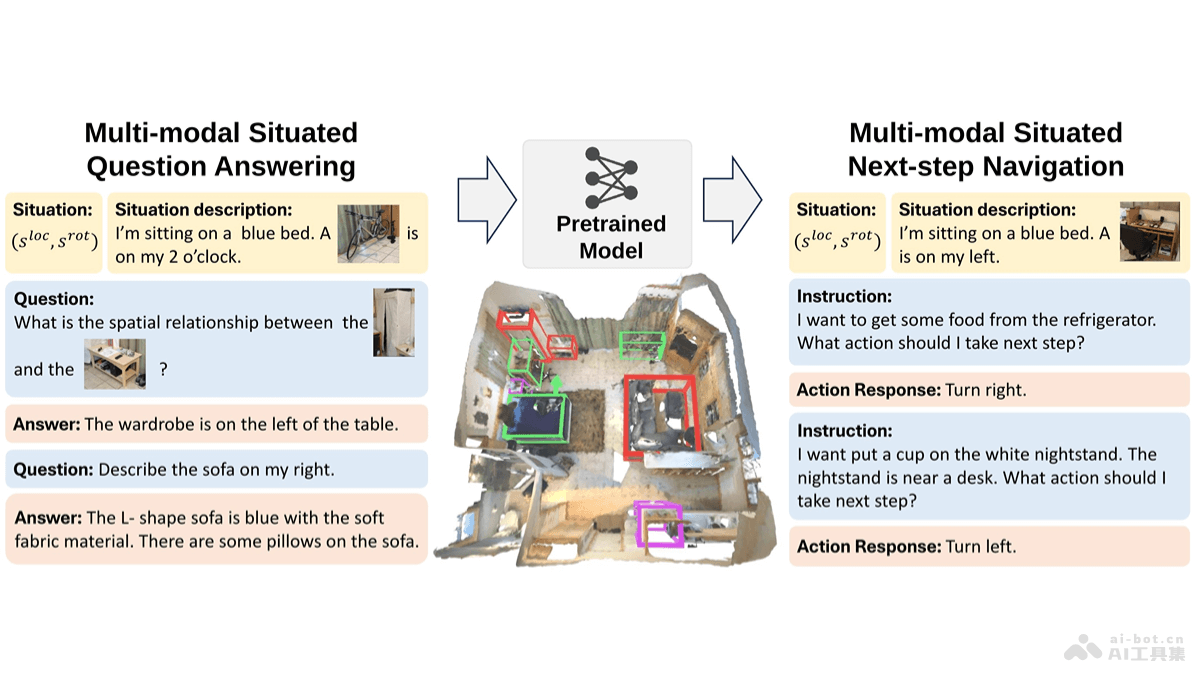
GTA(a benchmark for General Tool Agents)是上海交通大学和上海AI实验室共同推出的基准测试,评估大型语言模型(LLMs)在真实世界场景中调用工具的能力。GTA基于提供真实的用户问题、真实部署的工具和多模态输入输出,建立一个全面、细粒度的评估框架,有效衡量LLMs在复杂场景下的工具使用能力。GTA包含229个人类设计的问题,覆盖感知、操作、逻辑和创造力等多个类别,要求模型推理合适的工具,规划操作步骤,解决现实世界中的复杂任务。
 GTA的主要功能真实用户查询:包含229个人类编写的问题,问题具有简单的现实世界目标,但解决步骤和所需工具是隐含的,要求LLM基于推理选择合适的工具、规划操作步骤。真实部署的工具:GTA提供一个评估平台,部署涵盖感知、操作、逻辑和创造力四大类别的14种工具,评估代理的实际任务执行性能。多模态输入输出:GTA引入空间场景、网页截图、表格、代码片段、手写/打印材料等多模态输入,要求模型处理丰富的上下文信息,给出文本或图像输出。细粒度评估:GTA设计细粒度的评估指标,包括指令遵循准确率(InstAcc)、工具选择准确率(ToolAcc)、参数预测准确率(ArgAcc)和答案总结准确率(SummAcc),及最终答案准确率(AnsAcc)。模型评测:GTA在逐步模式(step-by-step mode)和端到端模式(end-to-end mode)下评估语言模型,提供对模型工具使用能力的全面评估。GTA的技术原理数据集构建:GTA的数据集构建包括问题构建和工具链构建两个步骤。问题由专家设计样例和标注文档,由标注人员基于样例设计更多的问题。工具链由标注人员手动调用部署好的工具构建,确保每个问题都能用提供的工具解决。工具调用:GTA用ReAct风格的提示模板,让LLM用特定的格式调用工具,处理工具返回的结果。模板支持LLM进行推理和规划,决定何时及如何调用工具。多模态处理:GTA要求LLM处理和理解多模态输入,包括图像、文本等,要求模型具备跨模态的理解和推理能力。细粒度评估指标:GTA设计的评估指标覆盖工具调用的整个过程,从LLM的工具调用过程到执行结果,提供对模型性能的全面评估。模型比较:基于比较不同模型在GTA上的表现,揭示现有模型在处理真实世界问题时面临的工具使用瓶颈,为未来的通用工具智能体提供改进方向。GTA的项目地址项目官网:open-compass.github.io/GTAGitHub仓库:https://github.com/open-compass/GTAHuggingFace模型库:https://huggingface.co/datasets/Jize1/GTAarXiv技术论文:https://arxiv.org/pdf/2407.08713GTA的应用场景智能助理开发:GTA评估和训练智能助理,让其更好地理解和执行复杂的用户请求,涉及多步骤和多种工具的调用。多模态交互:在需要处理图像、文本和其他多媒体内容的场景中,GTA帮助模型学习如何结合多种输入类型解决问题。自动化客户服务:GTA用在开发自动解决客户问题的系统,系统需要调用不同的工具和资源提供准确的答案和解决方案。教育和培训:GTA作为教育工具,帮助学生理解如何设计和实现复杂的任务,任务需要多步骤推理和工具使用。研究和开发:研究人员用GTA测试和比较不同的LLMs,探索工具使用能力的新方法,推动AI技术的发展。
GTA的主要功能真实用户查询:包含229个人类编写的问题,问题具有简单的现实世界目标,但解决步骤和所需工具是隐含的,要求LLM基于推理选择合适的工具、规划操作步骤。真实部署的工具:GTA提供一个评估平台,部署涵盖感知、操作、逻辑和创造力四大类别的14种工具,评估代理的实际任务执行性能。多模态输入输出:GTA引入空间场景、网页截图、表格、代码片段、手写/打印材料等多模态输入,要求模型处理丰富的上下文信息,给出文本或图像输出。细粒度评估:GTA设计细粒度的评估指标,包括指令遵循准确率(InstAcc)、工具选择准确率(ToolAcc)、参数预测准确率(ArgAcc)和答案总结准确率(SummAcc),及最终答案准确率(AnsAcc)。模型评测:GTA在逐步模式(step-by-step mode)和端到端模式(end-to-end mode)下评估语言模型,提供对模型工具使用能力的全面评估。GTA的技术原理数据集构建:GTA的数据集构建包括问题构建和工具链构建两个步骤。问题由专家设计样例和标注文档,由标注人员基于样例设计更多的问题。工具链由标注人员手动调用部署好的工具构建,确保每个问题都能用提供的工具解决。工具调用:GTA用ReAct风格的提示模板,让LLM用特定的格式调用工具,处理工具返回的结果。模板支持LLM进行推理和规划,决定何时及如何调用工具。多模态处理:GTA要求LLM处理和理解多模态输入,包括图像、文本等,要求模型具备跨模态的理解和推理能力。细粒度评估指标:GTA设计的评估指标覆盖工具调用的整个过程,从LLM的工具调用过程到执行结果,提供对模型性能的全面评估。模型比较:基于比较不同模型在GTA上的表现,揭示现有模型在处理真实世界问题时面临的工具使用瓶颈,为未来的通用工具智能体提供改进方向。GTA的项目地址项目官网:open-compass.github.io/GTAGitHub仓库:https://github.com/open-compass/GTAHuggingFace模型库:https://huggingface.co/datasets/Jize1/GTAarXiv技术论文:https://arxiv.org/pdf/2407.08713GTA的应用场景智能助理开发:GTA评估和训练智能助理,让其更好地理解和执行复杂的用户请求,涉及多步骤和多种工具的调用。多模态交互:在需要处理图像、文本和其他多媒体内容的场景中,GTA帮助模型学习如何结合多种输入类型解决问题。自动化客户服务:GTA用在开发自动解决客户问题的系统,系统需要调用不同的工具和资源提供准确的答案和解决方案。教育和培训:GTA作为教育工具,帮助学生理解如何设计和实现复杂的任务,任务需要多步骤推理和工具使用。研究和开发:研究人员用GTA测试和比较不同的LLMs,探索工具使用能力的新方法,推动AI技术的发展。