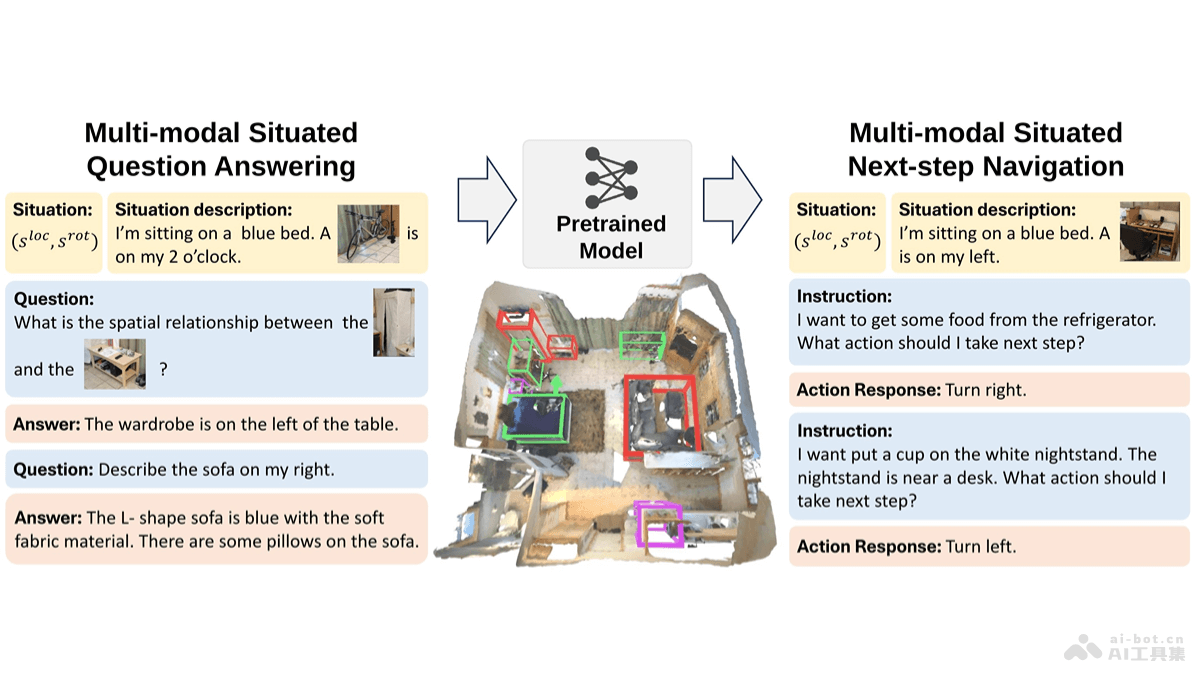
Vision Search Assistant(VSA)是结合视觉语言模型(VLMs)和网络代理的框架,提升模型对未知视觉内容的理解能力。基于互联网检索,使VLMs处理和回答有关未见图像的问题。VSA在开放集和封闭集问答测试中表现出色,显著优于包括LLaVA-1.6-34B、Qwen2-VL-72B和InternVL2-76B在内的其他模型。Vision Search Assistant能广泛应用于现有VLMs,增强处理新图像和事件的能力。
 Vision Search Assistant的主要功能视觉内容表述:识别图像中的关键对象、生成描述,考虑对象之间的相关性,这一过程称为相关表述(Correlated Formulation)。网络知识搜索:基于一个名为“Chain of Search”的迭代算法,生成多个子问题,用网络代理搜索相关信息,获取与用户问题和图像内容相关的网络知识。协作生成:结合原始图像、用户的问题、相关表述及通过网络搜索获得的知识,用VLM生成最终的答案。多模态搜索引擎:将任意VLM转变为能理解和响应视觉内容的多模态自动搜索引擎。实时信息访问:用网络代理的实时信息访问能力,让VLM获取最新的网络数据,提高回答的准确性。开放世界检索增强生成:基于互联网检索,扩展VLMs处理新视觉内容的能力,让其能够处理和回答有关未见过的图像或新概念的问题。Vision Search Assistant的技术原理视觉内容识别与描述:用VLM对输入图像进行分析,识别出图像中的关键对象,生成描述对象的文本。相关性分析:生成单个对象的描述,分析对象之间的相关性,生成一个综合考虑这些关系的文本表示,即相关表述。子问题生成:基于用户的问题和相关表述,VSA用大型语言模型(LLM)生成一系列子问题,子问题引导搜索过程,找到更具体的信息。网络搜索与知识整合:基于网络代理执行子问题搜索,分析搜索引擎返回的网页,提取、总结相关信息,形成网络知识。迭代搜索过程:用“Chain of Search”算法,基于迭代过程逐步细化搜索,获得更丰富、更准确的网络知识。Vision Search Assistant的项目地址项目官网:cnzzx.github.io/VSAGitHub仓库:https://github.com/cnzzx/VSAarXiv技术论文:https://arxiv.org/pdf/2410.21220Vision Search Assistant的应用场景图像识别与搜索:用户上传一张图片,识别图片中的内容并提供相关信息,例如识别历史人物、地标、动植物种类等。新闻事件分析:分析新闻图片,提供事件背景、参与者信息、事件影响等详细报道,帮助用户快速了解新闻事件的全貌。教育与学习:在教育领域,辅助学习,例如解释科学概念、历史事件,或者提供语言学习中的视觉辅助。电子商务:在电商平台,基于图像搜索帮助用户找到他们想要购买的商品,或者提供商品的详细信息和评价。旅游规划:用户上传旅游目的地的图片,获取景点介绍、旅游攻略、文化背景等信息,辅助用户规划行程。
Vision Search Assistant的主要功能视觉内容表述:识别图像中的关键对象、生成描述,考虑对象之间的相关性,这一过程称为相关表述(Correlated Formulation)。网络知识搜索:基于一个名为“Chain of Search”的迭代算法,生成多个子问题,用网络代理搜索相关信息,获取与用户问题和图像内容相关的网络知识。协作生成:结合原始图像、用户的问题、相关表述及通过网络搜索获得的知识,用VLM生成最终的答案。多模态搜索引擎:将任意VLM转变为能理解和响应视觉内容的多模态自动搜索引擎。实时信息访问:用网络代理的实时信息访问能力,让VLM获取最新的网络数据,提高回答的准确性。开放世界检索增强生成:基于互联网检索,扩展VLMs处理新视觉内容的能力,让其能够处理和回答有关未见过的图像或新概念的问题。Vision Search Assistant的技术原理视觉内容识别与描述:用VLM对输入图像进行分析,识别出图像中的关键对象,生成描述对象的文本。相关性分析:生成单个对象的描述,分析对象之间的相关性,生成一个综合考虑这些关系的文本表示,即相关表述。子问题生成:基于用户的问题和相关表述,VSA用大型语言模型(LLM)生成一系列子问题,子问题引导搜索过程,找到更具体的信息。网络搜索与知识整合:基于网络代理执行子问题搜索,分析搜索引擎返回的网页,提取、总结相关信息,形成网络知识。迭代搜索过程:用“Chain of Search”算法,基于迭代过程逐步细化搜索,获得更丰富、更准确的网络知识。Vision Search Assistant的项目地址项目官网:cnzzx.github.io/VSAGitHub仓库:https://github.com/cnzzx/VSAarXiv技术论文:https://arxiv.org/pdf/2410.21220Vision Search Assistant的应用场景图像识别与搜索:用户上传一张图片,识别图片中的内容并提供相关信息,例如识别历史人物、地标、动植物种类等。新闻事件分析:分析新闻图片,提供事件背景、参与者信息、事件影响等详细报道,帮助用户快速了解新闻事件的全貌。教育与学习:在教育领域,辅助学习,例如解释科学概念、历史事件,或者提供语言学习中的视觉辅助。电子商务:在电商平台,基于图像搜索帮助用户找到他们想要购买的商品,或者提供商品的详细信息和评价。旅游规划:用户上传旅游目的地的图片,获取景点介绍、旅游攻略、文化背景等信息,辅助用户规划行程。