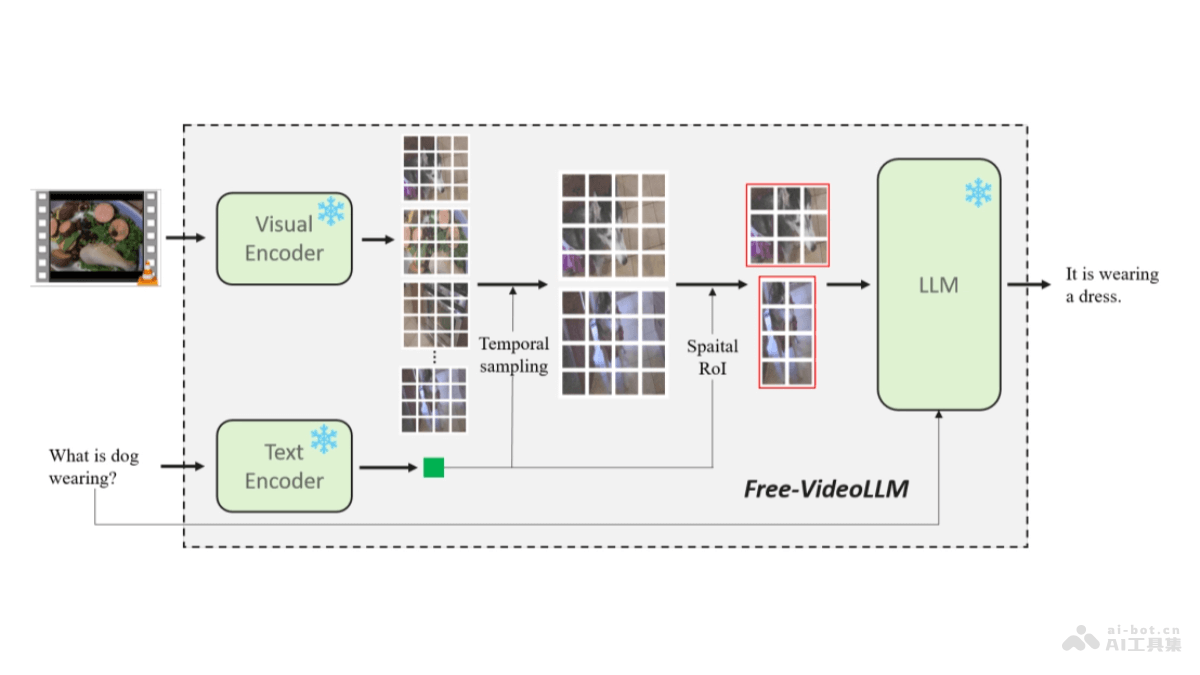
OmniVision是紧凑的多模态模型,拥有968M参数,专为边缘设备优化。OmniVision能处理视觉和文本输入,基于LLaVA架构改进,显著减少图像token数量,降低延迟和计算成本。基于可信数据进行DPO训练,OmniVision提供更可靠的结果,适于视觉问答和图像描述等任务。
 OmniVision的主要功能视觉问答(Visual Question Answering):OmniVision能理解图像内容,针对图像提出的问题给出准确的答案。图像描述(Image Captioning):模型能生成描述图像内容的文本。端到端视觉语言理解:基于整合视觉编码器和语言模型,OmniVision实现从图像到文本的无缝转换,理解图像内容用自然语言进行表达。优化边缘部署:针对边缘设备进行优化,减少计算资源的需求,模型在资源受限的环境中运行。OmniVision的技术原理紧凑的多模态架构:OmniVision结合基础语言模型Qwen2.5-0.5B-Instruct和视觉编码器SigLIP-400M,基于MLP投影层将图像嵌入与文本标记空间对齐,实现端到端的视觉语言理解。高效的Token处理:基于技术创新,OmniVision将图像token数量大幅减少,降低模型的计算成本和延迟,保持模型性能。精准的训练策略:基于三阶段训练流程,包括预训练、监督微调和直接偏好优化,提高模型对视觉和语言的理解和响应的准确性。OmniVision的项目地址项目官网:nexa.ai/blogs/omni-visionHuggingFace模型库:https://huggingface.co/NexaAIDev/omnivision-968MOmniVision的应用场景视觉问答(Visual Question Answering):用户针对图片内容提出问题,OmniVision能理解问题并结合图像内容给出准确的答案。图像描述生成(Image Captioning):模型能自动为图片生成描述性的文本,适于社交媒体、内容管理和图像存档等领域。内容审核:用视觉和文本理解能力,OmniVision能辅助进行图像和文本的内容审核,识别不当内容。辅助视觉搜索:在电商平台或图像数据库中,用户基于描述搜索特定的图像,OmniVision能理解描述并匹配相关图像。智能助手和聊天机器人:集成到聊天机器人中,OmniVision能理解用户发送的图像和文本信息,提供更加丰富和准确的交互体验。
OmniVision的主要功能视觉问答(Visual Question Answering):OmniVision能理解图像内容,针对图像提出的问题给出准确的答案。图像描述(Image Captioning):模型能生成描述图像内容的文本。端到端视觉语言理解:基于整合视觉编码器和语言模型,OmniVision实现从图像到文本的无缝转换,理解图像内容用自然语言进行表达。优化边缘部署:针对边缘设备进行优化,减少计算资源的需求,模型在资源受限的环境中运行。OmniVision的技术原理紧凑的多模态架构:OmniVision结合基础语言模型Qwen2.5-0.5B-Instruct和视觉编码器SigLIP-400M,基于MLP投影层将图像嵌入与文本标记空间对齐,实现端到端的视觉语言理解。高效的Token处理:基于技术创新,OmniVision将图像token数量大幅减少,降低模型的计算成本和延迟,保持模型性能。精准的训练策略:基于三阶段训练流程,包括预训练、监督微调和直接偏好优化,提高模型对视觉和语言的理解和响应的准确性。OmniVision的项目地址项目官网:nexa.ai/blogs/omni-visionHuggingFace模型库:https://huggingface.co/NexaAIDev/omnivision-968MOmniVision的应用场景视觉问答(Visual Question Answering):用户针对图片内容提出问题,OmniVision能理解问题并结合图像内容给出准确的答案。图像描述生成(Image Captioning):模型能自动为图片生成描述性的文本,适于社交媒体、内容管理和图像存档等领域。内容审核:用视觉和文本理解能力,OmniVision能辅助进行图像和文本的内容审核,识别不当内容。辅助视觉搜索:在电商平台或图像数据库中,用户基于描述搜索特定的图像,OmniVision能理解描述并匹配相关图像。智能助手和聊天机器人:集成到聊天机器人中,OmniVision能理解用户发送的图像和文本信息,提供更加丰富和准确的交互体验。