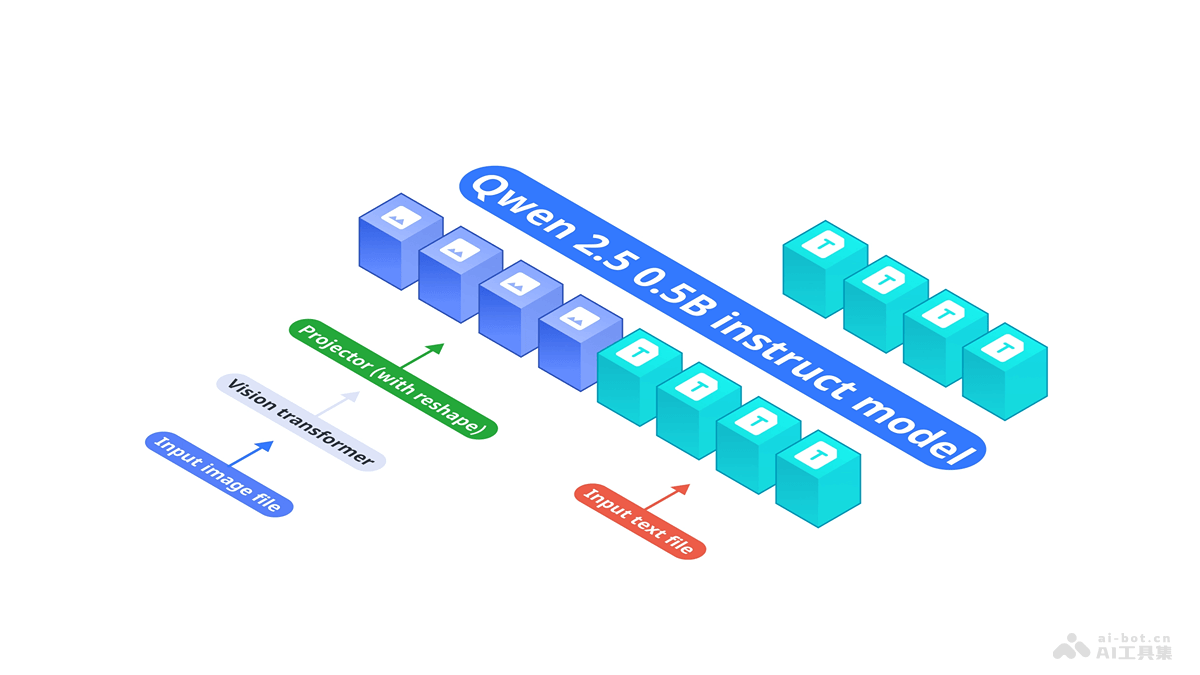
Free Video-LLM是创新的无需训练的高效视频语言模型,基于提示引导的视觉感知技术,实现对视频内容的高效理解。模型用预训练的图像LLMs,无需额外训练即可适应视频任务,减少视频帧生成的视觉标记数量,降低计算成本。Free Video-LLM在多个视频问答基准上展现出与最先进的视频LLMs相媲美的性能,显著减少了视觉标记的使用,为视频理解任务提供准确性与计算效率之间的理想平衡。
 Free Video-LLM的主要功能高效视频理解:Free Video-LLM在不进行额外训练的情况下,直接对视频内容进行理解和推理,适于视频问答等多模态任务。提示引导的视觉感知:基于分析输入提示,模型能识别视频中与任务最相关的时空信息,减少不必要的计算。时空采样优化:模型用时间帧采样和空间感兴趣区域(RoI)裁剪技术,降低模型处理的视频数据量,提高推理效率。保持高性能:虽减少了视觉标记的数量,模型仍在多个视频问答基准测试中保持与现有技术相竞争的性能。Free Video-LLM的技术原理提示引导的时间采样:基于与视觉编码器相匹配的文本编码器提取提示特征。计算视频帧特征与提示特征之间的相似度得分。根据得分对视频帧进行采样,选择与任务最相关的帧。提示引导的空间采样(RoI裁剪):将视频帧的视觉标记重新塑造为空间尺寸。计算每个空间位置的特征向量与提示特征的相似度得分。选择最相关的区域作为RoI,裁剪出这些区域。减少视觉标记:基于时空采样方法,减少模型需要处理的视觉标记数量,降低计算复杂度。保持性能:虽减少了视觉标记,基于精心设计的采样策略,模型能保持或提升视频理解任务的性能。Free Video-LLM的项目地址GitHub仓库:https://github.com/contrastive/FreeVideoLLMarXiv技术论文:https://arxiv.org/pdf/2410.10441Free Video-LLM的应用场景视频问答系统:提供对视频内容的自动问答服务,如教育平台的视频辅导或企业培训视频的理解。视频内容分析:在媒体和娱乐行业,自动提取视频内容的语义信息,便于内容管理和检索。安全监控:在安全领域,对监控视频进行实时分析,识别特定事件或行为。自动驾驶:在自动驾驶汽车中,理解和解释道路状况的视频流,辅助决策制定。智能助理:集成到智能助理中,提供基于视频内容的交互式问答功能。
Free Video-LLM的主要功能高效视频理解:Free Video-LLM在不进行额外训练的情况下,直接对视频内容进行理解和推理,适于视频问答等多模态任务。提示引导的视觉感知:基于分析输入提示,模型能识别视频中与任务最相关的时空信息,减少不必要的计算。时空采样优化:模型用时间帧采样和空间感兴趣区域(RoI)裁剪技术,降低模型处理的视频数据量,提高推理效率。保持高性能:虽减少了视觉标记的数量,模型仍在多个视频问答基准测试中保持与现有技术相竞争的性能。Free Video-LLM的技术原理提示引导的时间采样:基于与视觉编码器相匹配的文本编码器提取提示特征。计算视频帧特征与提示特征之间的相似度得分。根据得分对视频帧进行采样,选择与任务最相关的帧。提示引导的空间采样(RoI裁剪):将视频帧的视觉标记重新塑造为空间尺寸。计算每个空间位置的特征向量与提示特征的相似度得分。选择最相关的区域作为RoI,裁剪出这些区域。减少视觉标记:基于时空采样方法,减少模型需要处理的视觉标记数量,降低计算复杂度。保持性能:虽减少了视觉标记,基于精心设计的采样策略,模型能保持或提升视频理解任务的性能。Free Video-LLM的项目地址GitHub仓库:https://github.com/contrastive/FreeVideoLLMarXiv技术论文:https://arxiv.org/pdf/2410.10441Free Video-LLM的应用场景视频问答系统:提供对视频内容的自动问答服务,如教育平台的视频辅导或企业培训视频的理解。视频内容分析:在媒体和娱乐行业,自动提取视频内容的语义信息,便于内容管理和检索。安全监控:在安全领域,对监控视频进行实时分析,识别特定事件或行为。自动驾驶:在自动驾驶汽车中,理解和解释道路状况的视频流,辅助决策制定。智能助理:集成到智能助理中,提供基于视频内容的交互式问答功能。