
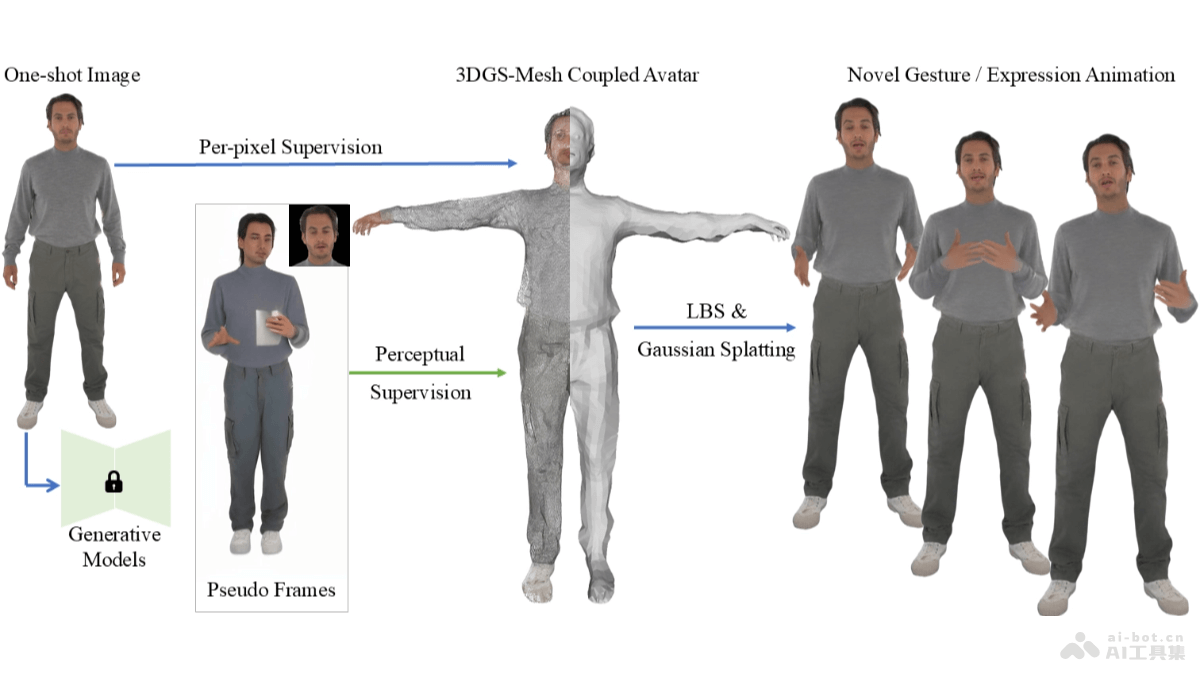
One Shot, One Talk是先进的图像生成技术,能从单张图片中生成具有个性化细节的全身动态说话头像,支持逼真的动画效果,包括自然的表情变化和生动的身体动作。One Shot, One Talk是中国科学技术大学和香...
网站首页 > AI工具 第14页
-
-

Aurora是xAI为AI助手Grok新增的图像生成模型。Aurora擅长创建逼真的图像,擅长人物肖像。Aurora能生成包括公共和版权人物在内的图像(如米老鼠)。Aurora 的可用性因用户等级而异,免费 xAI 用户每天...
-

MEMO(Memory-Guided EMOtionaware diffusion)是Skywork AI、南洋理工大学和新加坡国立大学推出的音频驱动肖像动画框架,用在生成具有身份一致性和表现力的说话视频。MEMO围绕两个核...
-

Clone-voice是开源的声音克隆工具,基于深度学习技术分析和模拟人类声音,实现声音的高质量克隆。工具支持包括中文、英文、日语、韩语等在内的16种语言,能将文本转换为语音或将一种声音风格转换为另一种。用户界面友好,操作简...
-

SNOOPI是创新的文本到图像生成框架,基于增强单步扩散模型的指导提升模型性能和控制力。SNOOPI包括PG-SB(适当指导 - SwiftBrush)和NASA(负向远离转向注意力)两种技术。PG-SB用随机尺度的无分类器...
-

Llama 3.3是Meta AI推出的70B 参数模型,大型多语言预训练语言模型,性能与40B参数的Llama 3.1相当。模型专为多语言对话优化,支持英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。...
-

Fox-1是TensorOpera推出的一系列小型语言模型(SLMs),包括Fox-1-1.6B和Fox-1-1.6B-Instruct-v0.1。Fox-1模型在3万亿个网络抓取的文档数据上预训练,在50亿个指令遵循和多轮...
-

Optimus-1是哈尔滨工业大学(深圳)和鹏城实验室推出的智能体框架,能解决在开放世界环境中完成长期任务的挑战。框架结合结构化知识和多模态经验,让智能体更好地执行复杂任务。...
-

PaliGemma 2是Google DeepMind基于Gemma 2语言模型家族推出的新一代视觉语言模型(VLM),作为PaliGemma模型的升级版。结合SigLIP-So400m视觉编码器和不同规模的Gemma 2模...
-

ClearerVoice-Studio 是阿里巴巴达摩院通义实验室开源的语音处理框架,集成语音增强、分离和音视频说话人提取等功能。框架基于复数域深度学习算法,有效消除背景噪声,保留语音清晰度,且最小化语音失真。...
