
CodeArena是在线平台,基于让多个大型语言模型(LLM)同时构建相同的应用程序,实时显示排名结果,比较LLM生成代码的能力。CodeArena平台主要评估和比较不同LLM的代码生成能力,帮助开发者选择适合的LLM,推动...
网站首页 > AI工具 第10页
-
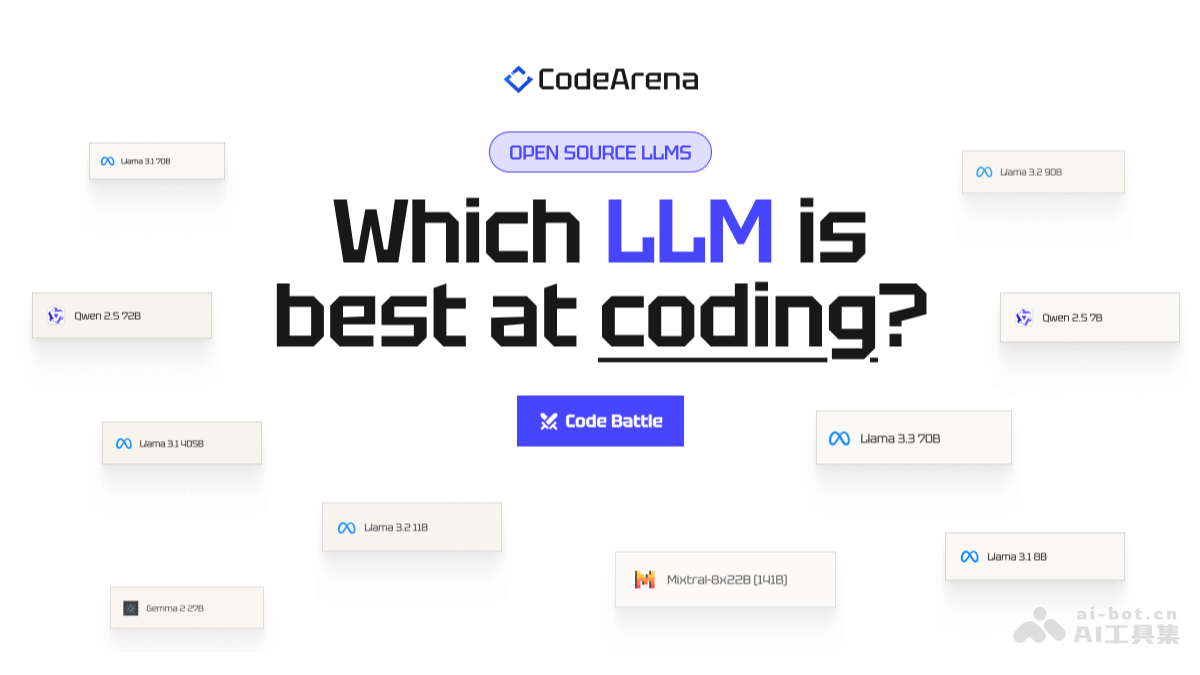
-

Multimodal Live API 是谷歌推出的低延迟、双向交互的AI接口,支持文本、音频和视频输入,用音频和文本形式输出,能帮助开发者构建具有实时音频和视频流功能的应用程序。Multimodal Live API让与A...
-

SwiftEdit是由VinAI Research团队推出的文本引导的图像编辑工具,基于创新的一步扩散技术,能在0.23秒内实现快速且高质量的图像编辑。工具的核心优势在于一步反演框架和掩码引导编辑技术,让编辑过程迅速,且能保...
-

SynCamMaster是浙江大学、快手科技、清华大学和香港中文大学的研究人员共同合作推出的全球首个多视角视频生成模型,能结合6自由度相机姿势,从任意视点生成开放世界视频。SynCamMaster增强了预训练的文本到视频模型...
-
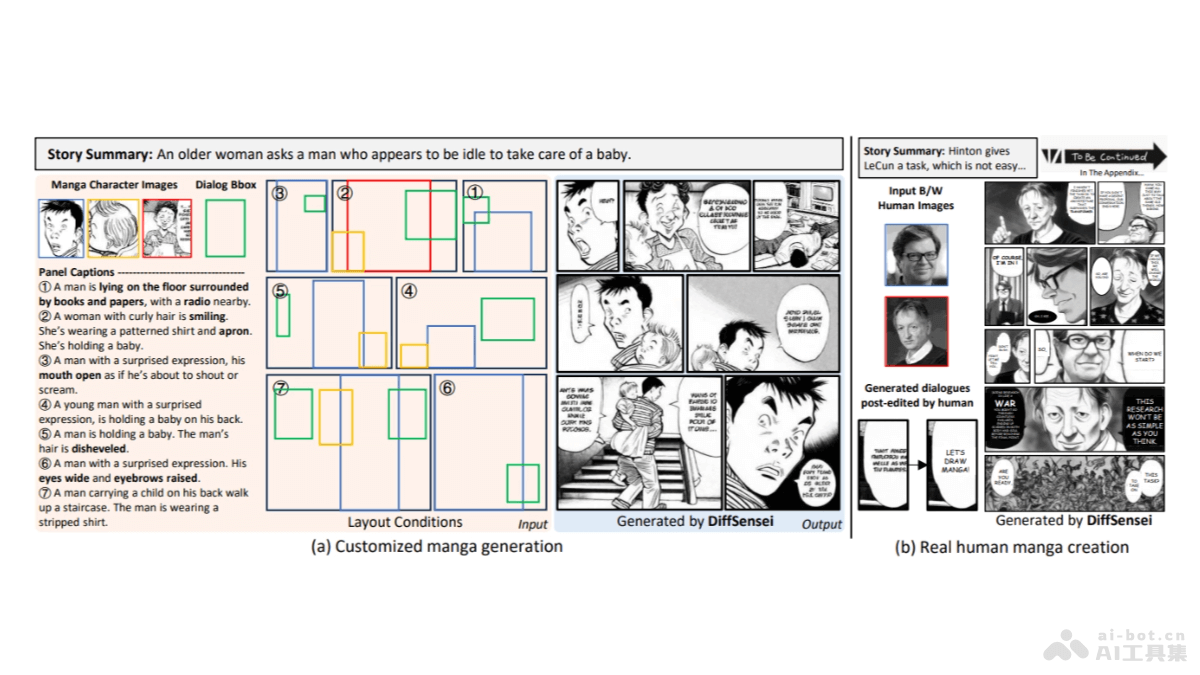
DiffSensei是北京大学、上海AI实验室及南洋理工大学的研究人员共同推出的漫画生成框架,能生成可控的黑白漫画面板。DiffSensei整合基于扩散的图像生成器和多模态大型语言模型(MLLM),实现对漫画中多角色外观和互...
-
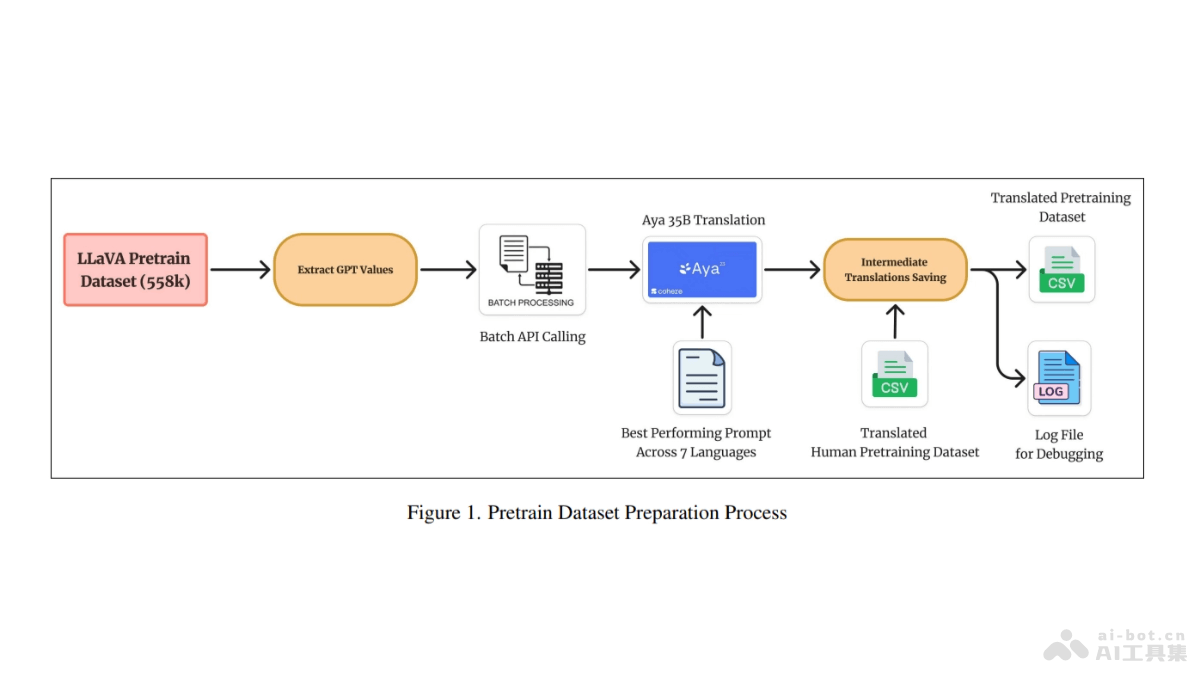
Maya是开源的多语言多模态模型,基于指令微调扩展模型在多种语言和文化背景下的能力。Maya基于LLaVA框架,包含新创建的包含八种语言的预训练数据集,提高视觉-语言任务中的文化和语言理解。Maya基于毒性分析和数据集过滤,...
-

Promptic是轻量级的LLM应用开发框架,提供高效且符合Python风格的开发方式。基于LiteLLM,Promptic支持开发者能轻松切换不同的LLM服务提供商,只需更改一行代码。Promptic支持流式响应、内置对话...
-

千影 QianYing是巨人网络推出的有声游戏生成大模型,包含游戏视频生成大模型YingGame和视频配音大模型YingSound。YingGame面向开放世界游戏,是巨人网络AI Lab与清华大学SATLab联合推出的,能...
-
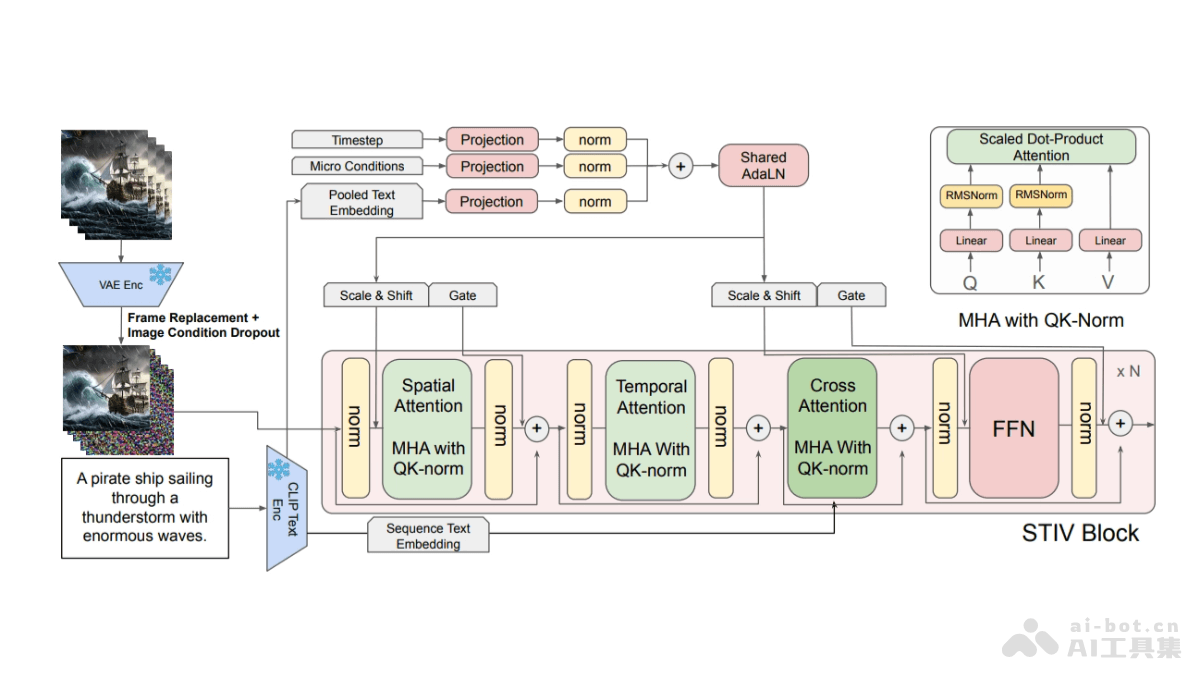
STIV(Scalable Text and Image Conditioned Video Generation)是苹果公司推出的视频生成大模型。STIV拥有8.7亿参数,能处理文本到视频(T2V)和文本图像到视频(TI2...
-

TEN Agent是集成OpenAI Realtime API和RTC技术的开源实时多模态AI代理框架。TEN Agent能实现语音、文本、图像的多模态交互,支持高性能的实时通信,具备低延迟的音视频交互能力。TEN Agen...
