
Qwen2VL-Flux是多模态图像生成模型,结合Qwen2VL的视觉语言理解和FLUX框架,基于文本提示和图像参考生成高质量的图像。模型支持多种生成模式,包括变体生成、图像到图像转换、智能修复及ControlNet引导生成...
网站首页 > AI工具 第22页
-

-
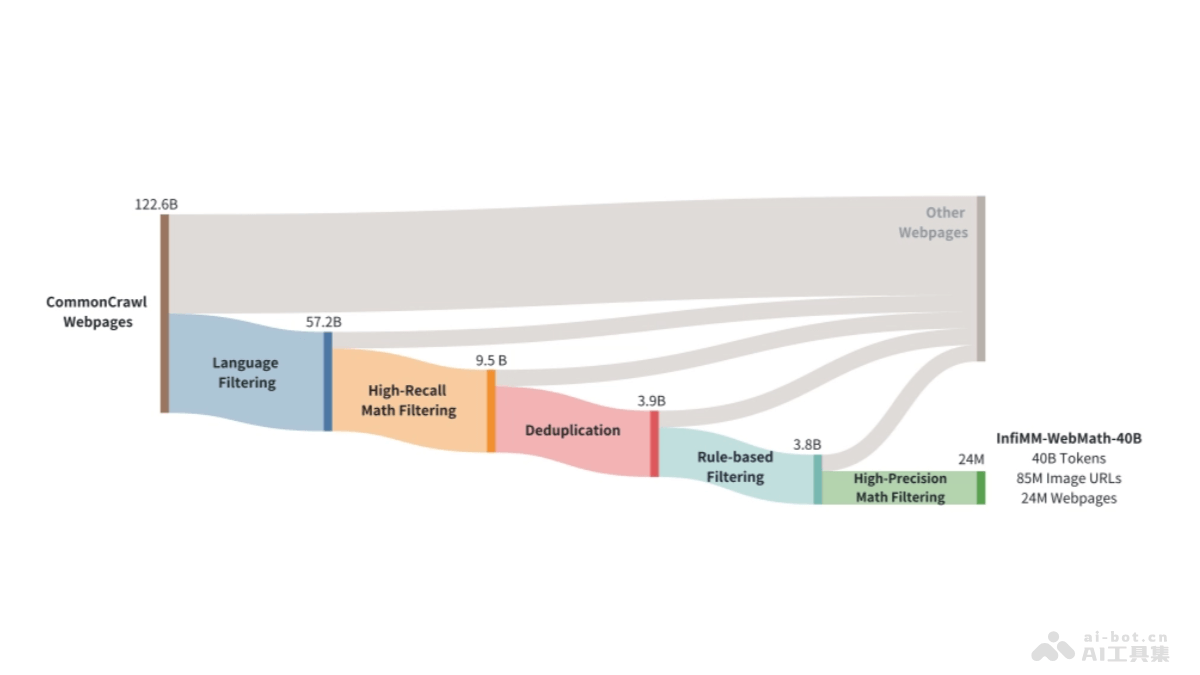
InfiMM-WebMath-40B 是字节跳动和中国科学院联合开源的超大规模多模态数据集,旨在提升多模态模型的图文混合推理能力,在数学领域。数据集从 Common Crawl 中提取,经过严格的筛选、清洗和标注,包含 24...
-

ShowUI是新加坡国立大学Show Lab和微软共同推出的视觉-语言-行动模型,能提升图形用户界面(GUI)助手的工作效率。模型基于UI引导的视觉令牌选择减少计算成本,用交错视觉-语言-行动流统一GUI任务中的多样化需求,...
-
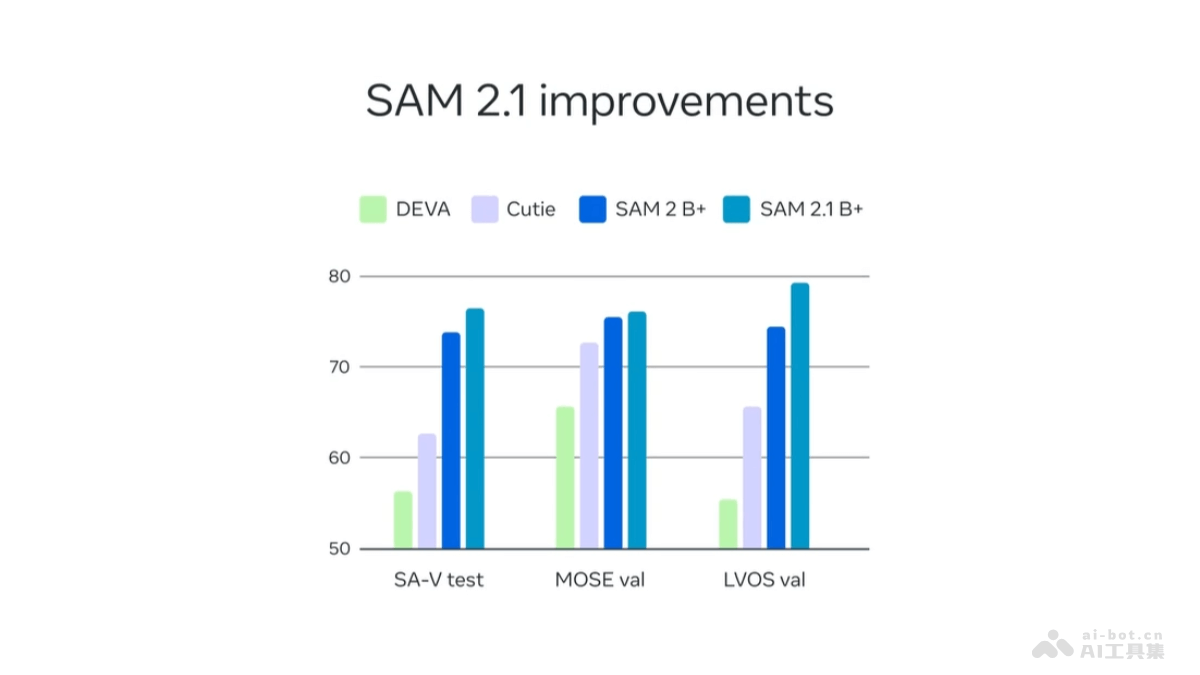
SAM 2.1(全称Segment Anything Model 2.1)是Meta(Facebook的母公司)推出的先进视觉分割模型,用于图像和视频。基于简单的Transformer架构和流式记忆设计,实现实时视频处理。S...
-

QwQ-32B-Preview(QwQ-32B)是阿里推出的开源AI推理模型,在数学和编程领域表现卓越。QwQ-32B-Preview包含325亿参数,能处理长达32000个tokens的提示词。在多个基准测试中,包括GPQ...
-
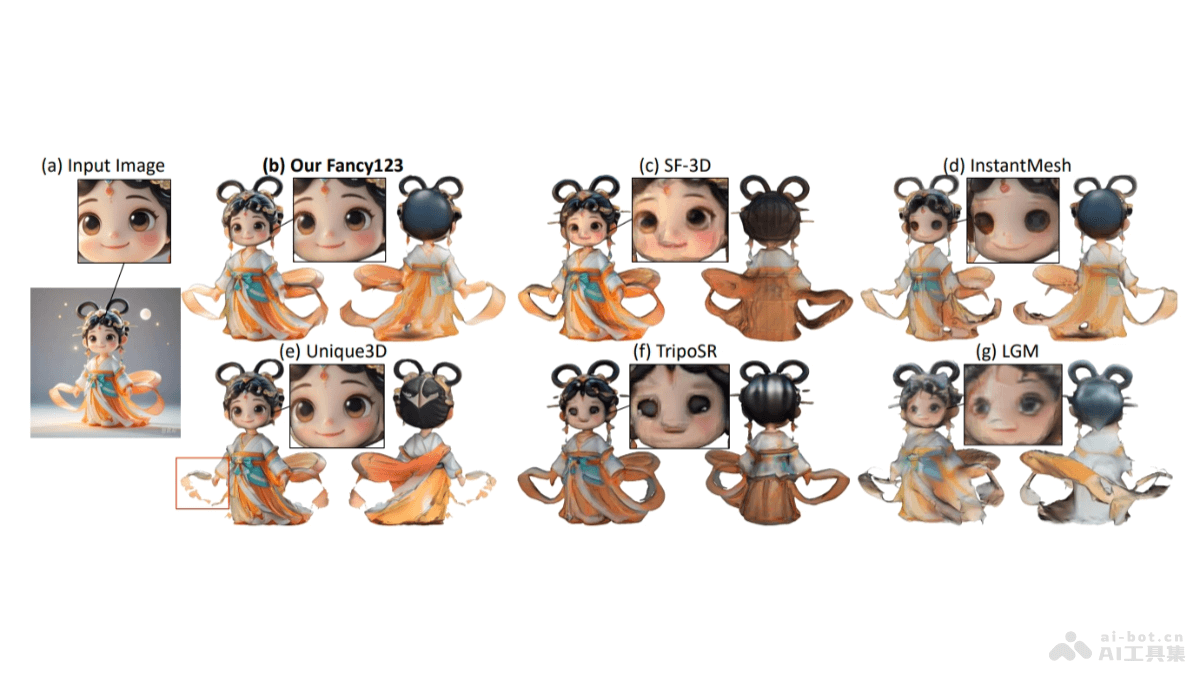
Fancy123是华中科技大学和华南理工大学推出的3D网格生成技术,基于即插即用的变形技术从单张图片生成高质量的3D网格。该方法包含两个增强模块和反投影操作,分别解决多视图图像的局部不一致性、提高网格对输入图像的保真度及确保...
-
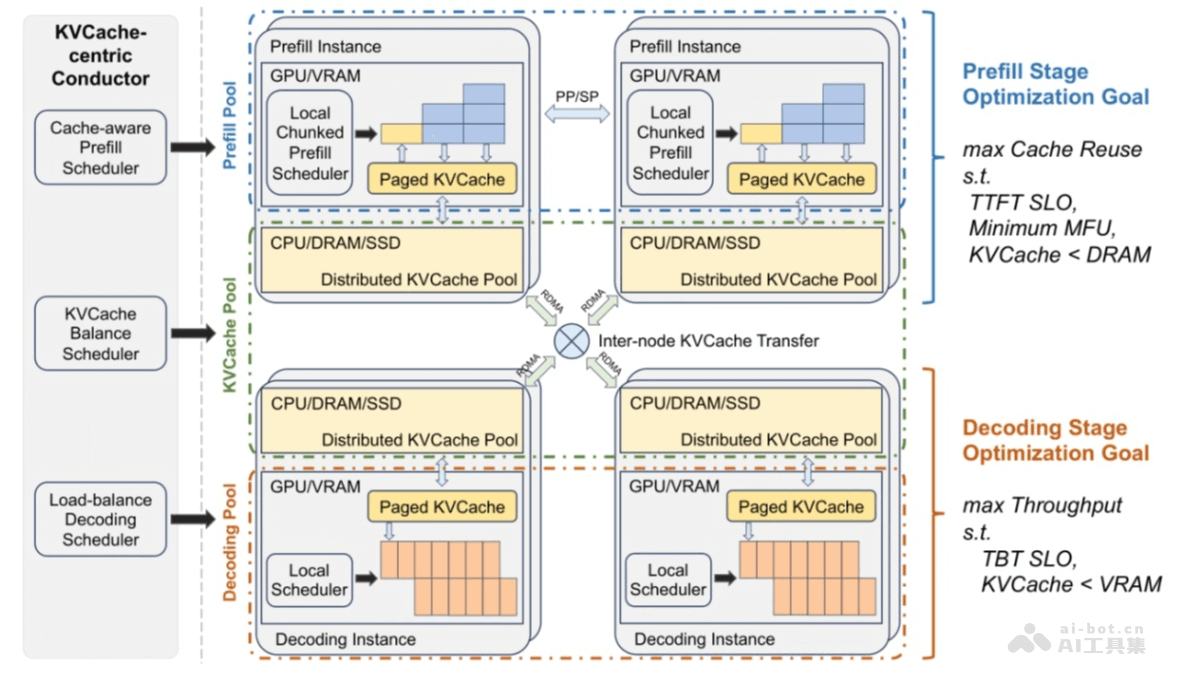
Mooncake是月之暗面Kimi联合清华大学等机构共同开源的大模型推理架构。采用以KVCache为中心的分布式架构,通过分离预填充和解码集群,充分利用GPU集群中未充分利用的CPU、DRAM和SSD资源,实现高效的KVCa...
-

Sketch2Lineart是基于人工智能的绘画工具,能将简单的手绘草图转换成清晰的线条画。通过自动生成草图描述并据此绘制线条画,支持调整细节适应不同风格。用户只需上传草图,可在线预览下载转换后的线条画。...
-
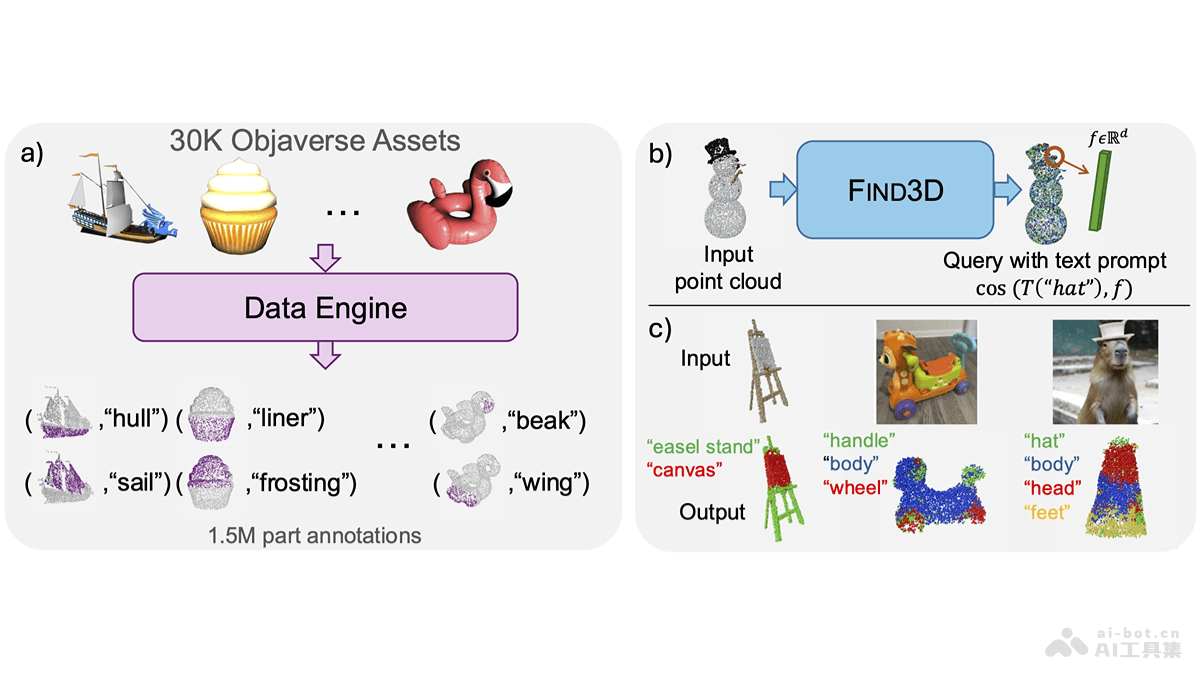
Find3D是加州理工学院推出的3D部件分割模型,能根据任意文本查询分割任意对象的任何部分。Find3D用一个强大的数据引擎自动从互联网上的3D资产生成训练数据,并用对比训练方法训练一个可扩展的3D模型。...
-
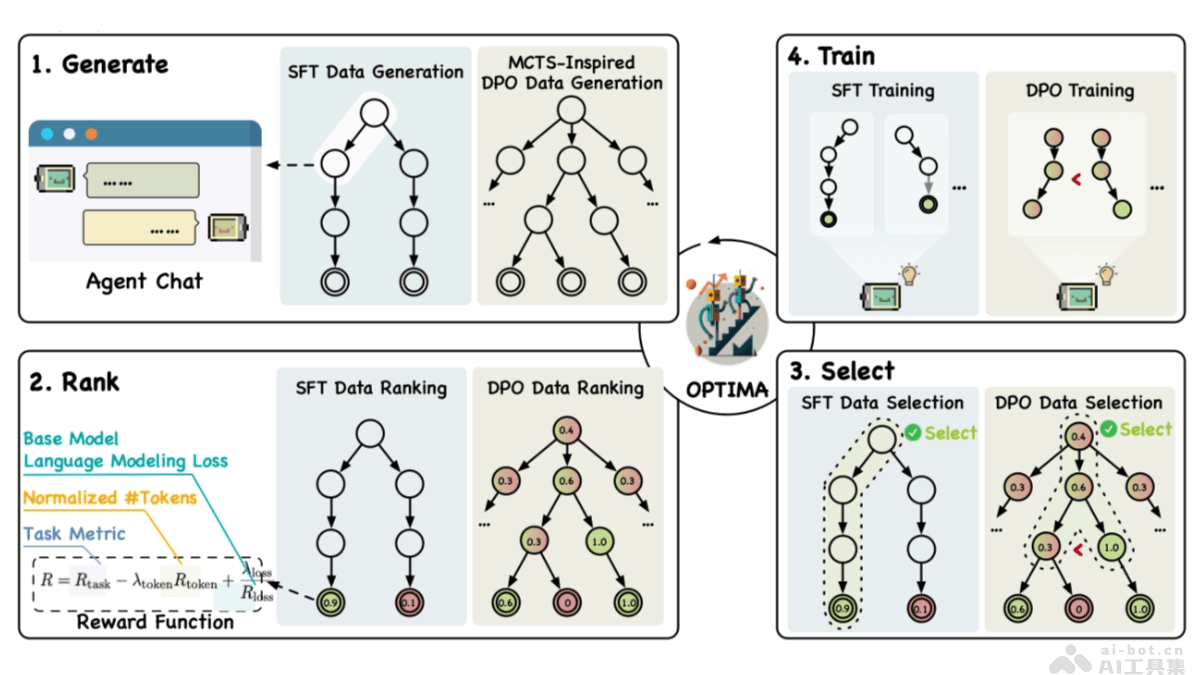
Optima是清华大学推出的优化基于大型语言模型(LLM)的多智能体系统(MAS)的框架。基于一个迭代的生成、排名、选择和训练范式,显著提高通信效率和任务效果。Optima平衡了任务性能、令牌效率和通信可读性,探索了多种强化...
