
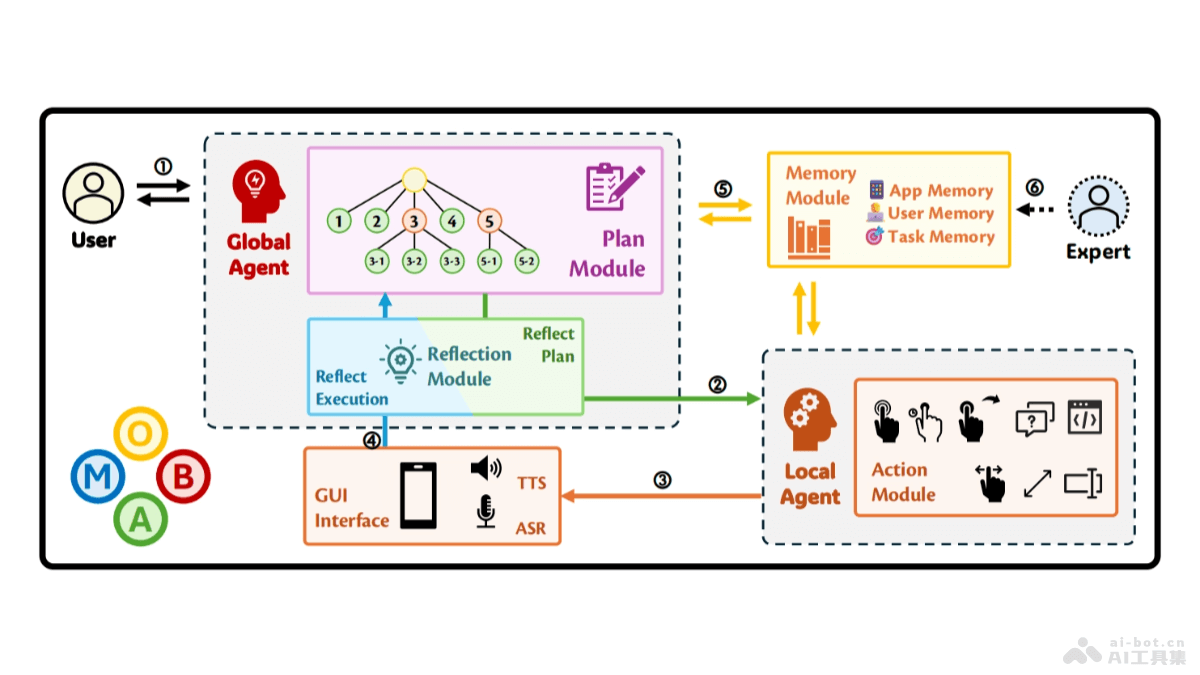
MobA(Mobile Agent)是上海交通大学团队推出的新型移动智能体,基于多模态大型语言模型(MLLMs)提升移动设备的自动化任务执行能力。MobA采用两级架构:高级全局智能体(GA)负责理解用户指令、管理历史记录和规...
网站首页 > AI工具 第25页
-
-

Fugatto是英伟达(NVIDIA)推出的音频合成和转换模型,全称为"Foundational Generative Audio Transformer Opus 1"。模型能根据文本提示生成音频或视频...
-

Frames是Runway推出的最新AI图像生成模型,在风格控制和视觉保真度方面取得巨大进步。Frames能维持风格一致性,支持广泛的创意探索,为项目建立特定外观,并生成符合用户美学的变体。基于Frames,用户能精确设计想...
-

SlideChat是上海AI实验室、厦门大学、华东师范大学等机构推出的,首个能理解千兆像素级别全切片图像的视觉语言助手。SlideChat能生成详尽的全切片图像描述,并针对多样化的病理场景提供具有上下文关联的复杂指令响应。基...
-
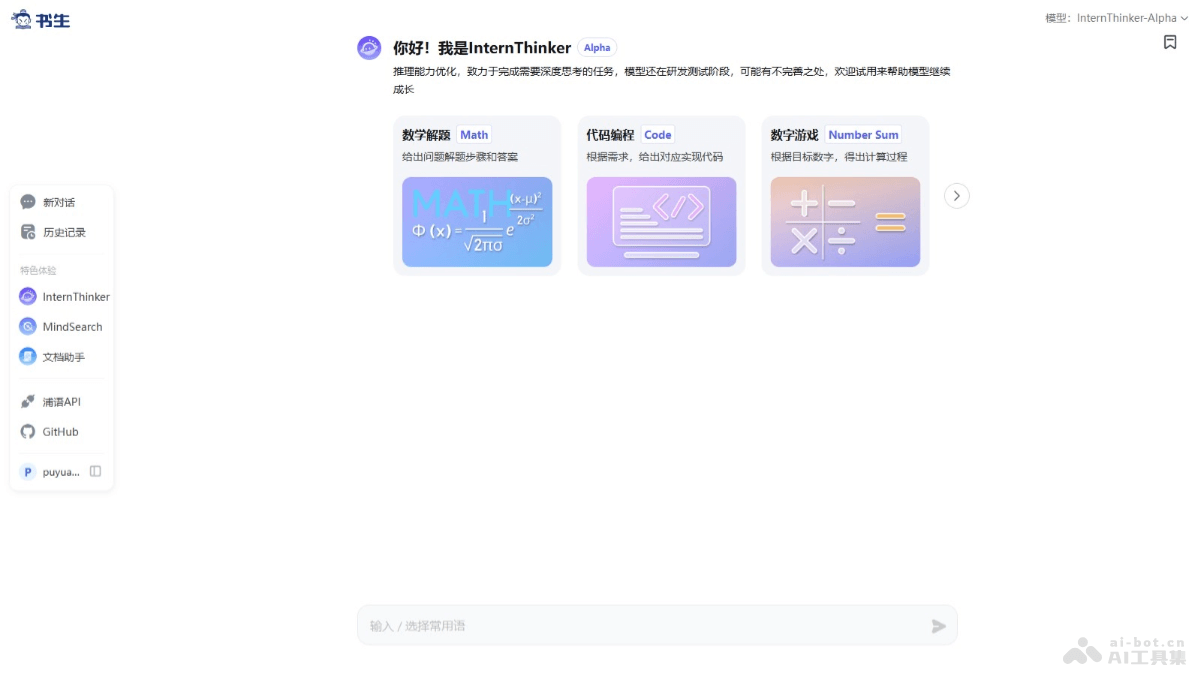
书生InternThinker是上海人工智能实验室推出的强推理模型,具备自主生成高智力密度数据和元动作思考能力。基于长思维能力和自我反思、纠正机制,在数学、代码、推理谜题等多种复杂任务上表现出色。模型用通专融合技术,基于大规...
-

MCP(Model Context Protocol,模型上下文协议)是一个开放协议,是Anthropic开源的,能实现大型语言模型(LLM)应用与外部数据源和工具之间的无缝集成。基于客户端-服务器架构,支持多个服务连接到任...
-

LEOPARD是腾讯AI Lab西雅图实验室推出的视觉语言模型,专为理解和处理含有大量文本的多图像任务设计。LEOPARD基于两个主要技术创新:一是策划约一百万条专门针对文本丰富、多图像场景的高质量多模态指令调优数据集;二是...
-

LazyGraphRAG是微软研究院推出的图形增强生成增强检索(RAG)框架,是GraphRAG的迭代版本。LazyGraphRAG在数据索引成本上大幅降低,是GraphRAG的0.1%,同时用新的混合数据搜索方法,提高生成...
-
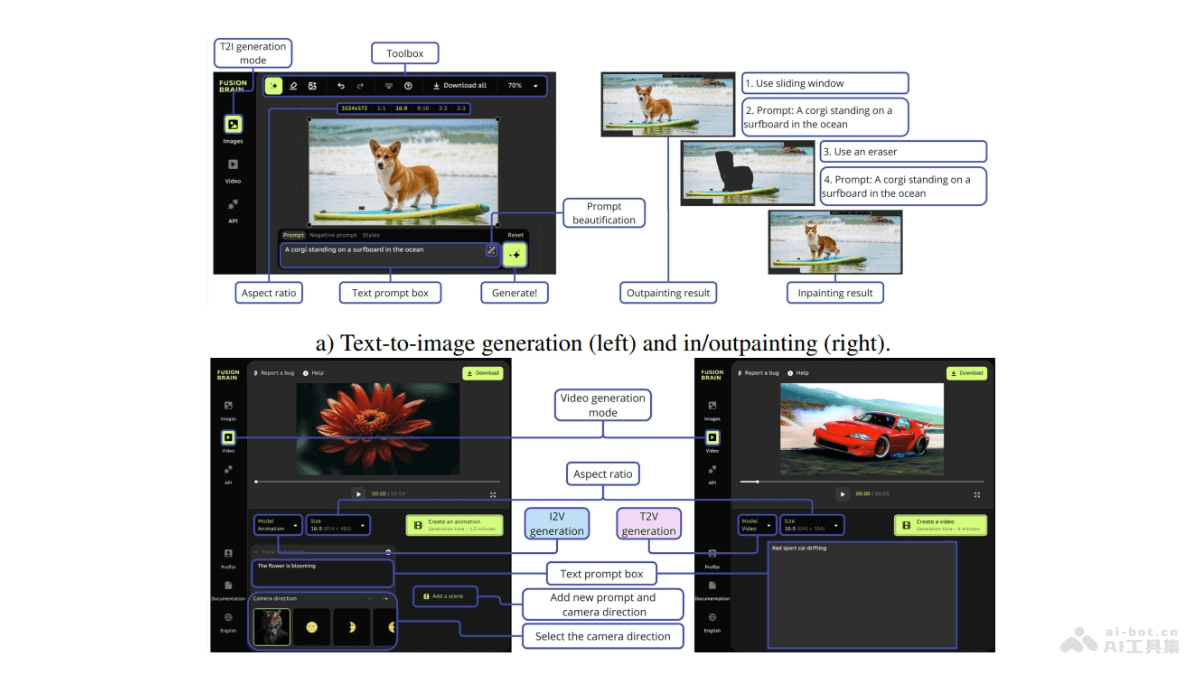
Kandinsky-3是基于潜在扩散模型的文本到图像(T2I)生成框架,以高质量和逼真度在图像合成领域脱颖而出。Kandinsky-3能适应多种图像生成任务,包括文本引导的修复/扩展、图像融合、文本-图像融合及视频生成等。研...
-
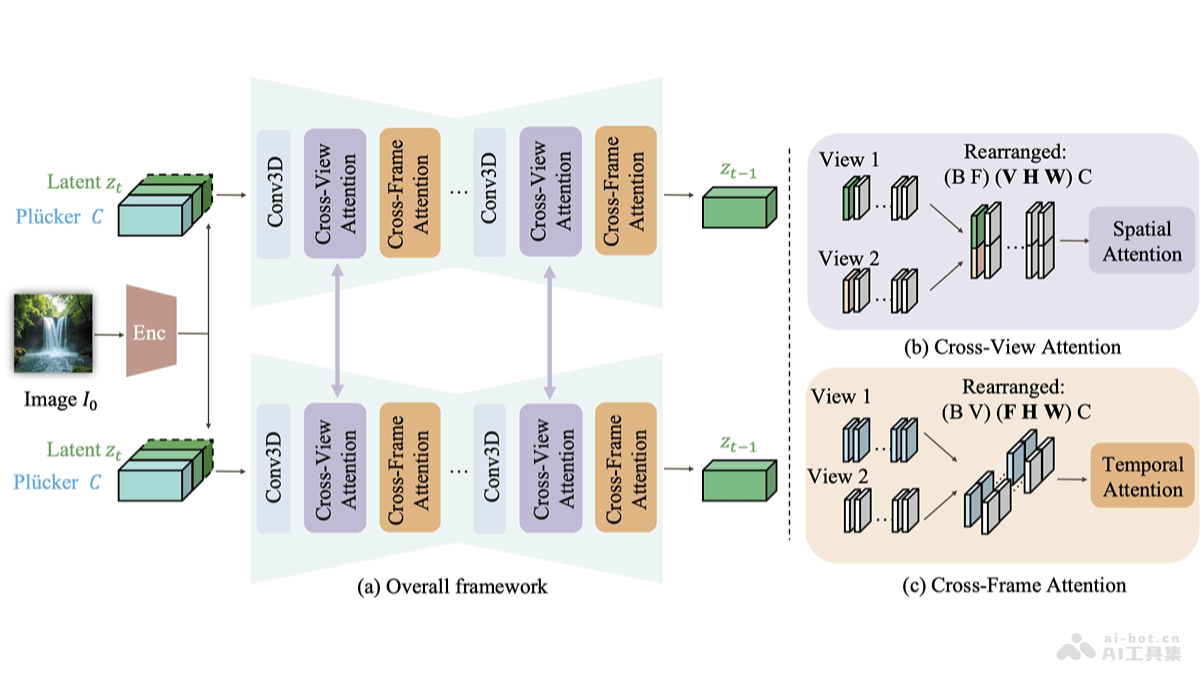
CAVIA是苹果公司、得克萨斯大学奥斯汀分校、谷歌联合推出的多视角视频生成框架,能将单一输入图像转换成多个时空一致的视频序列。框架基于引入视角集成注意力模块,增强视频的视角一致性和时间连贯性,支持用户精确控制相机运动,同时保...
