
SANA是由NVIDIA、麻省理工学院和清华大学共同推出的文本到图像生成框架,能高效地生成高达4096×4096分辨率的高清晰度图像。SANA基于深度压缩自编码器、线性扩散变换器(Linear DiT)、仅解码器的小型语言模...
网站首页 > AI工具 第52页
-

-
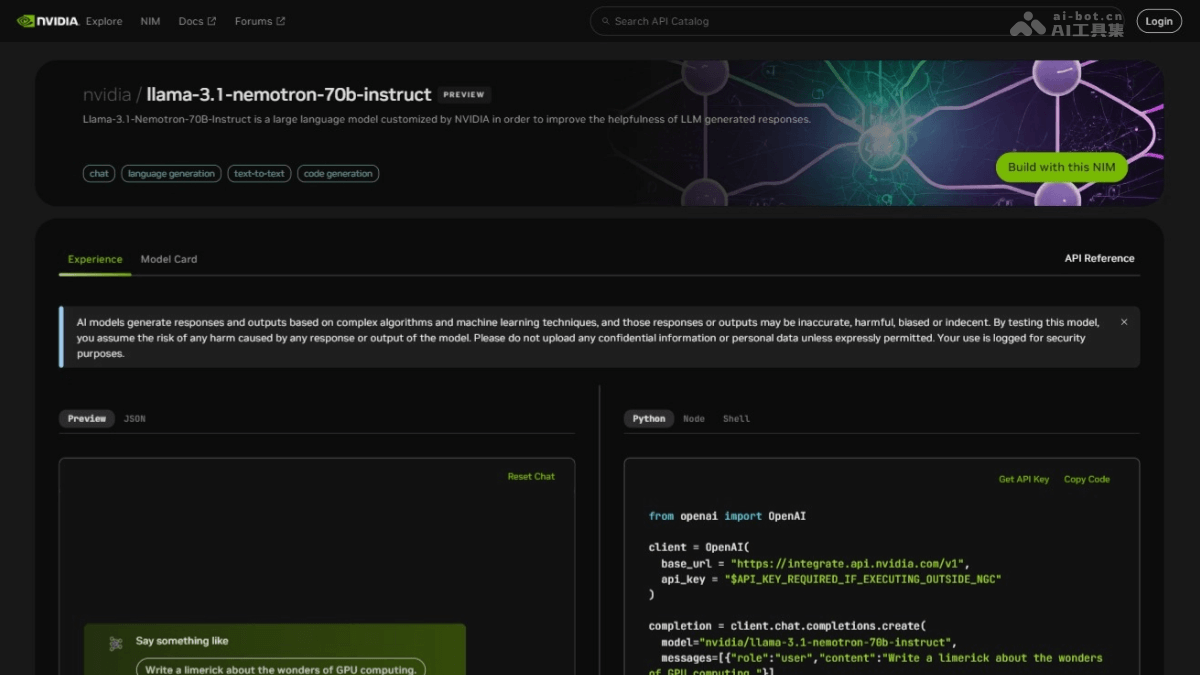
Nemotron-70B-Instruct 是英伟达(NVIDIA)发布的一个大型语言模型,基于一种新颖的混合训练方法提升模型遵循指令时的响应质量和一致性。模型结合Bradley-Terry和Regression风格训练的元...
-

TANGO 是一个由东京大学和 CyberAgent AI Lab 共同推出的开源框架,专注于生成与目标语音同步的全身手势视频。基于分层音频运动嵌入和扩散插值网络,将目标语音音频与参考视频库中的动作完美匹配,确保制作出高保真...
-

Ministral 3B和8B是由Mistral AI推出的两款新型AI小模型,专为设备端计算和边缘使用场景设计。在知识、常识、推理、功能调用和效率方面为10亿参数以下的类别设定新的标准。Ministral 3B和8B支持高...
-

Marco是阿里国际最新推出的大规模商用翻译大模型,支持15种全球主流语种,包括中、英、日、韩、西、法等。在BLEU评测指标上超越Google翻译、DeepL、GPT-4等竞争对手,提供基于语境的精准翻译,避免字面意思造成的...
-

模型判官是一个基于 Next.js 构建的在线AI模型评测平台,用户输入问题并选择多个AI模型进行测试,帮助用户快速识别出最适于需求的AI模型。平台的特色在于,提供多个模型的回答,自动调用一个评判模型评估回答的质量,给出评分...
-

AgentStack是一个开源工具,旨在帮助开发者快速构建AI代理项目。基于提供一个预配置的模板和集成流行的代理框架及大型语言模型(LLM)提供商,简化从零开始创建AI代理的过程。AgentStack支持macOS、Wind...
-

Hallo2是由复旦大学、百度公司和南京大学共同推出的音频驱动肖像图像动画生成模型。能将单张参考图片和持续几分钟的音频输入结合起来,基于可选的文本提示调节肖像表情,生成与音频同步的高分辨率4K视频。Hallo2基于先进的数据...
-
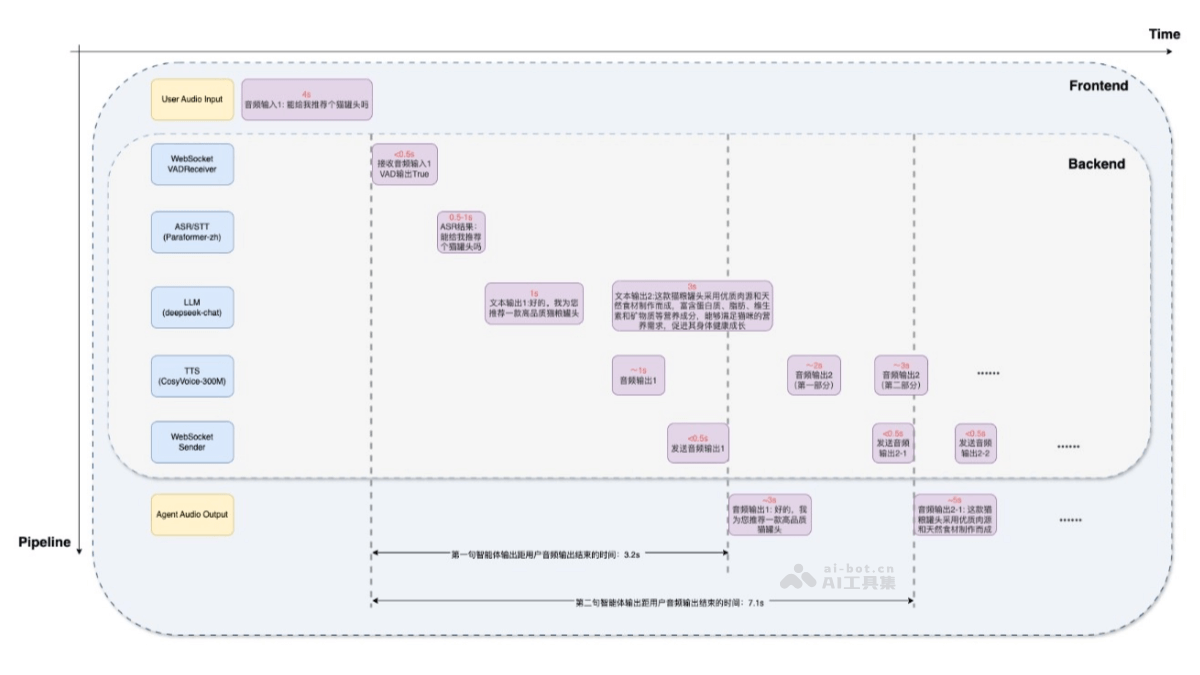
CleanS2S是一个流式语音到语音(S2S)交互智能体原型,提供高质量、实时的语音交互体验。CleanS2S项目基于单文件实现,简化配置和理解过程,便于用户和研究人员快速体验语言用户界面(LUI)的强大功能,探索S2S管道...
-
FunASR是由阿里巴巴达摩院开源的语音识别工具包,提供包括语音识别(ASR)、语音活动检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离及多说话人ASR等多种功能。FunASR工具包支持工业级语音识别模型的训练和微...
