
StoryDiffusion是一个先进的AI图像和视频生成框架,用于从文本描述生成具有一致性的图像和视频序列。基于Consistent Self-Attention机制增强图像间的一致性,生成的内容在身份和服饰等细节上保持连...
网站首页 > AI工具 第56页
-

-

Crawl4AI是一款用 Python 开发的异步爬虫框架,专为大型语言模型(LLMs)和人工智能(AI)应用设计,简化网络爬虫和数据提取流程。基于异步架构,高效地处理多个网页,快速抓取所需数据。Crawl4AI支持多种输出...
-

Wren AI 是一个开源的文本到 SQL 解决方案,基于自然语言处理技术,支持用户通过自然语言提问执行数据库查询,无需编写复杂的 SQL 代码。支持多种数据库和数据源,包括 PostgreSQL、MySQL、BigQuer...
-

Playground v3(PGv3)是由Playground Research推出的最新文本到图像模型,基于深度融合的大型语言模型(LLM)技术,实现在图形设计任务上超越人类设计师的能力。PGv3拥有240亿参数量,能精确...
-
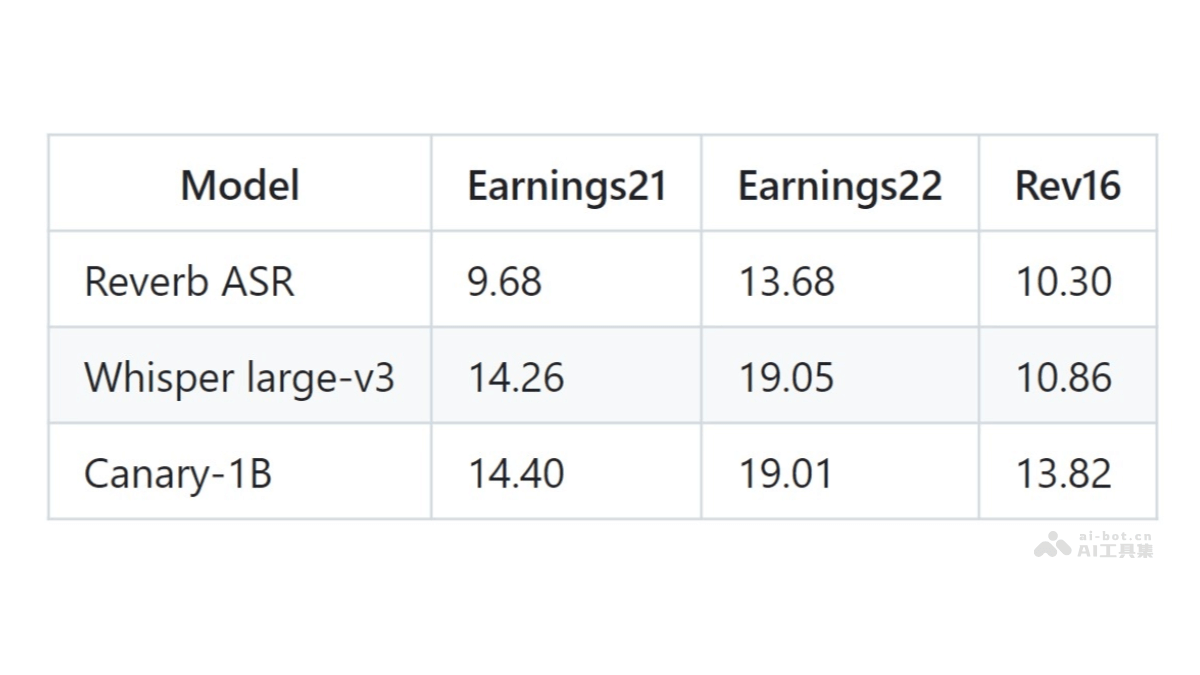
Reverb ASR是Rev公司推出的开源自动语音识别和说话人分离模型,基于20万小时的人工转录英语数据训练而成。模型在长语音识别领域表现卓越,适合处理如播客和财报电话会议等场景。Reverb ASR支持用户控制输出文本的逐...
-
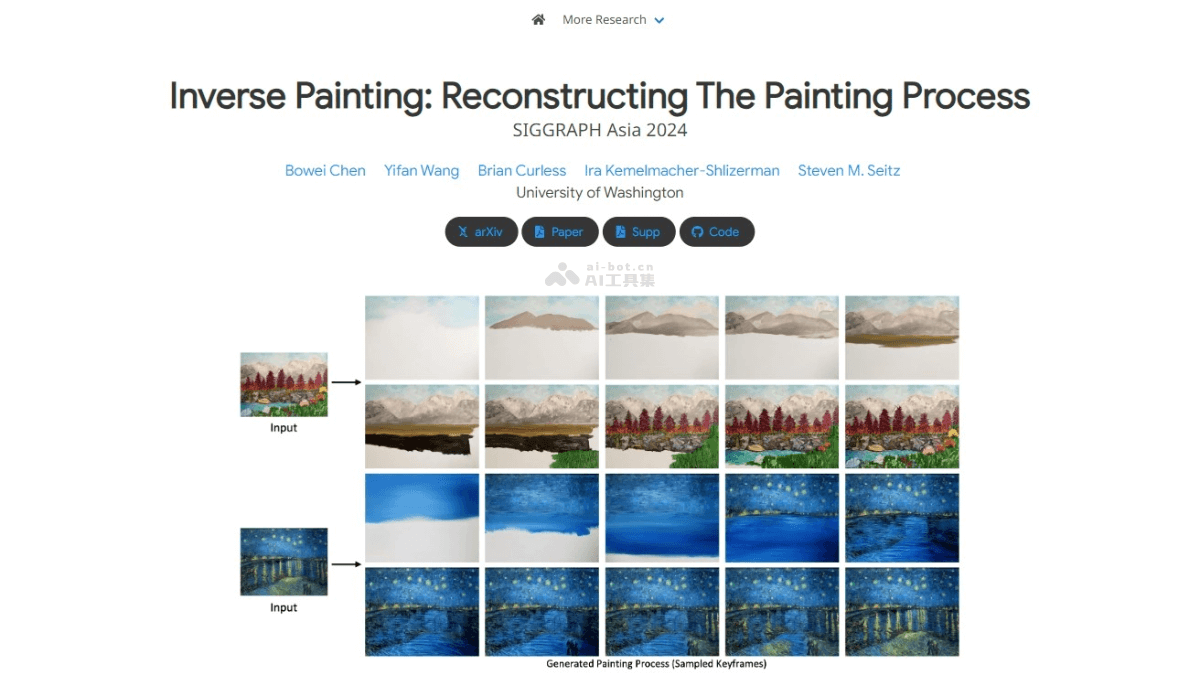
Inverse Painting 是一种AI技术,由华盛顿大学的研究人员推出,能逆向重现绘画过程。通过分析艺术家的绘画视频,学习绘画技巧和顺序,然后生成一系列绘画指令,逐步更新画布,模拟艺术家的创作过程。过程包括学习绘画过程...
-

Open NotebookLM 是一个开源的AI工具,基于最新的开源AI模型,如Llama 3.1 405B、MeloTTS和Bark,将PDF文档转换成播客形式的音频内容。工具适合将书面信息转换成听觉格式的用户,例如学生、...
-

IFAdapter是一种新型的文本到图像生成模型,由腾讯和新加坡国立大学共同推出。提升生成含有多个实例的图像时的位置和特征准确性。传统模型在处理多实例图像时常常面临定位和特征准确性的挑战,IFAdapter通过引入两个关键组...
-

TinyVLA是一种面向机器人操控的视觉-语言-动作(VLA)模型,由华东师范大学和上海大学团队推出。针对现有VLA模型的不足,如推理速度慢和需要大量数据预训练,提出解决方案。TinyVLA基于轻量级的多模态模型和扩散策略解...
-

Matryoshka Diffusion Models(MDM)是苹果公司推出的一种创新的扩散模型,主要用于生成高分辨率图像和视频。MDM通过多分辨率扩散过程,在不同尺度上同时进行去噪,有效提升模型的训练效率和生成质量。...
