
CogView3是清华大学联合智谱AI推出的开源AI图像生成模型,采用中继扩散技术。模型分阶段生成图像,首先创建低分辨率图像,然后通过中继超分辨率技术提升至高分辨率,提高生成效率并降低成本。CogView3在生成质量和速度上...
网站首页 > AI工具 第60页
-

-

Mini-LLaVA是一款轻量级的多模态大语言模型,由清华大学和北京航空航天大学的研究团队联合开发。能处理图像、文本和视频输入,实现高效的多模态数据处理。Mini-LLaVA基于Llama 3.1模型,优化了代码结构,在单个...
-

Movie Gen 是 Meta 推出的一种新型AI工具,能根据文本提示生成和编辑视频,为视频配上同步音频。技术包括创建长达16秒的高清视频、为现有视频配上音频、编辑视频以及基于照片制作定制视频。...
-

MemoryScope是一个为大型语言模型(LLM)聊天机器人设计的长期记忆系统。通过构建一个框架,使机器人记住用户的基础信息、习惯和偏好,提供个性化的交互体验。MemoryScope具备记忆数据库、核心worker库和核心...
-

Phidias是一个先进的3D内容生成模型,将检索增强生成(RAG)的概念引入到3D建模领域。模型能基于用户提供的或从大型数据库中检索到的3D参考模型,辅助生成新的3D内容。...
-

Seed-VC 是一种零样本声音转换技术,基于上下文学习实现高质量的音频输出和音色相似度。用户无需进行特定训练,只需提供1到30秒的参考语音样本,实现声音的克隆和转换。...
-
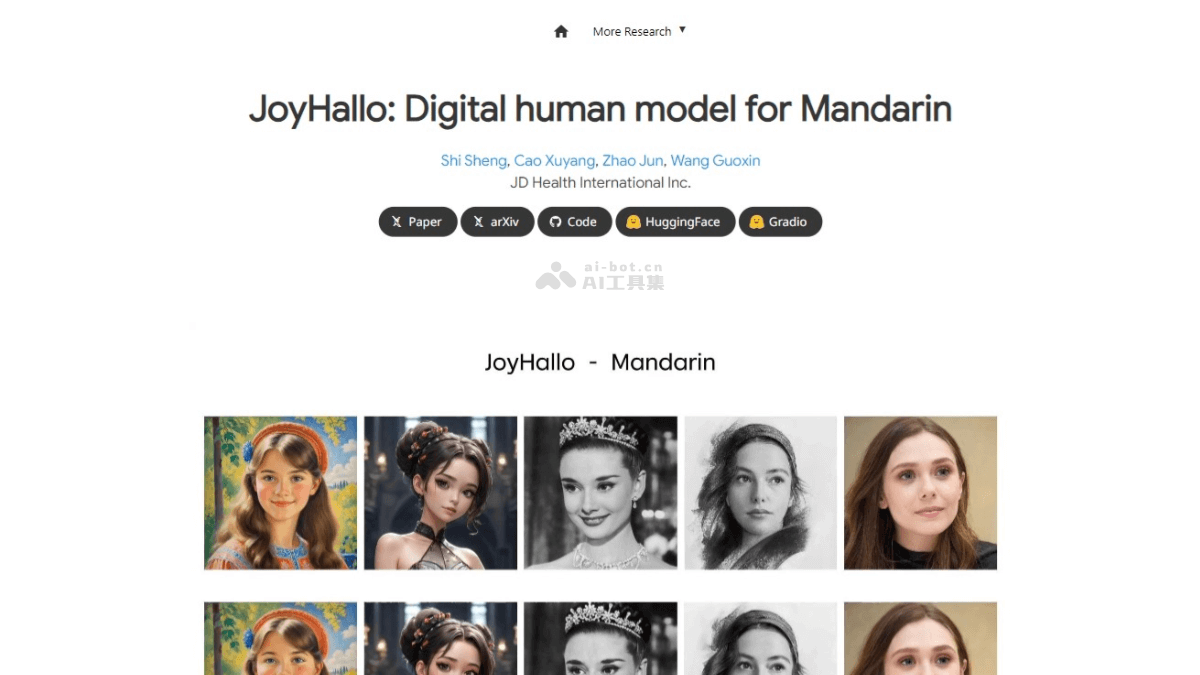
JoyHallo 是京东开源的数字人模型,专为普通话设计,能根据音频生成逼真的说话视频。特别适合处理普通话的复杂口型和语调,具有跨语言生成视频的能力。...
-

AMD-135M是AMD推出的首款小型语言模型(SLM),为特定用例提供性能与资源消耗之间的平衡。基于LLaMA2模型架构,在AMD Instinct MI250加速器上训练,基于670亿个token,AMD-135M分为两...
-

HouseCrafter 是由东北大学和 Stability AI 推出的先进技术,将二维平面图自动转换成三维室内场景。基于一个网络规模图像训练的2D扩散模型,生成一致的多视图彩色(RGB)和深度(D)图像。图像自回归地批量...
-

MemFree是一款开源的混合AI搜索引擎,通过整合多种AI模型和搜索引擎,提供高效、多样化的搜索体验。可以用文本、图像、文件和网页等多种方式进行搜索和提问,获取文本、思维导图、图片和视频等多格式的搜索结果。...
