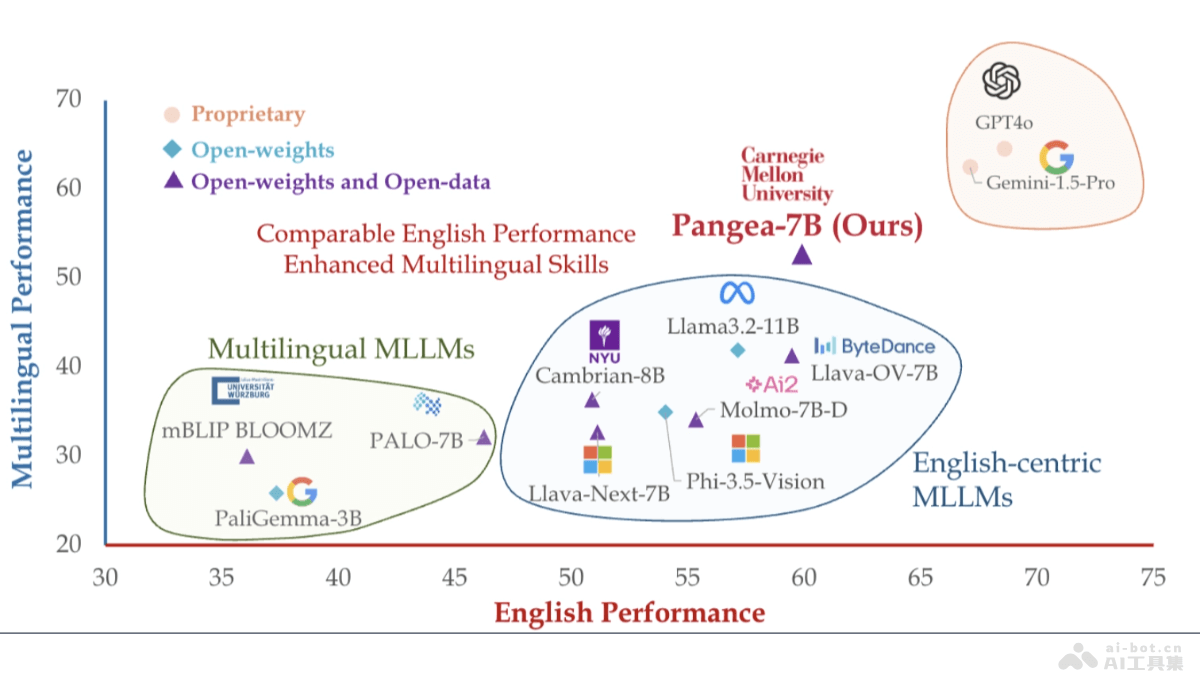
LongRAG是清华大学、中国科学院和智谱的研究团队推出的,面向长文本问答(LCQA)的双视角鲁棒检索增强生成(RAG)框架。基于混合检索器、LLM增强信息提取器、CoT引导过滤器和LLM增强生成器四个组件,有效解决长文本问答中的全局上下文理解和事实细节识别难题。LongRAG在多个数据集上超越长上下文LLM、高级RAG系统和Vanilla RAG等基线模型,展现出卓越的性能和鲁棒性。LongRAG提供自动化微调数据构建管道,增强系统的“指令跟随”能力和领域适应性。
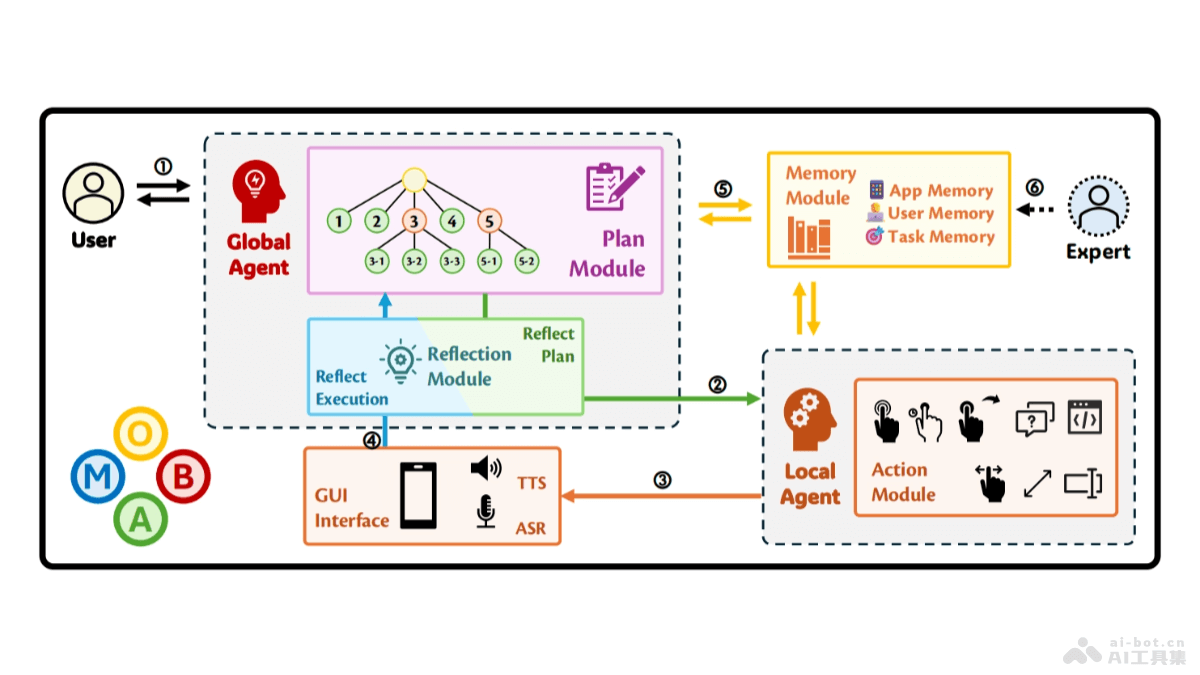
 LongRAG的主要功能双视角信息处理:基于全局信息和事实细节的双视角来理解和回答长文本上下文问题。混合检索器:快速从大量数据中检索与问题相关的信息片段。LLM增强信息提取器:将检索到的片段映射回原始长文本段落,提取全局背景和结构信息。CoT引导过滤器:用链式思考(Chain of Thought, CoT)指导模型关注与问题相关的信息,过滤掉不相关的内容。LLM增强生成器:结合全局信息和关键事实细节生成最终答案。自动化微调数据构建:基于自动化流程构建高质量的微调数据集,提升模型在特定任务上的表现。LongRAG的技术原理检索增强生成(RAG):基于RAG框架,检索外部知识辅助语言模型生成回答。全局信息和细节信息的整合:系统不仅关注局部事实细节,还整合长文本中的全局信息,提供更全面的答案。映射策略:将检索到的片段映射回原始长文本,恢复上下文信息,提供更准确的背景结构。链式思考(CoT):用CoT作为全球线索,指导模型逐步关注与问题相关的知识,提高证据密度。过滤策略:基于CoT的全局线索,过滤掉不相关的信息片段,保留关键的事实细节。LongRAG的项目地址GitHub仓库:https://github.com/QingFei1/LongRAGarXiv技术论文:https://arxiv.org/pdf/2410.18050LongRAG的应用场景客户服务与支持:在客户服务领域,理解和回答长篇的客户查询或历史交互记录,提供更准确的回答和解决方案。医疗咨询:在医疗行业处理大量的病人记录和医学文献,回答医生或病人关于疾病、治疗和药物的复杂问题。法律咨询:帮助法律专业人士基于分析大量的法律文件和案例,提供关于法律问题的深入分析和建议。教育与研究:在教育领域,作为辅助工具,帮助学生和研究人员深入理解长篇学术文章和研究报告,回答研究相关的问题。企业决策支持:分析市场研究报告、企业年报等长篇文档,为商业决策提供数据支持和洞察。
LongRAG的主要功能双视角信息处理:基于全局信息和事实细节的双视角来理解和回答长文本上下文问题。混合检索器:快速从大量数据中检索与问题相关的信息片段。LLM增强信息提取器:将检索到的片段映射回原始长文本段落,提取全局背景和结构信息。CoT引导过滤器:用链式思考(Chain of Thought, CoT)指导模型关注与问题相关的信息,过滤掉不相关的内容。LLM增强生成器:结合全局信息和关键事实细节生成最终答案。自动化微调数据构建:基于自动化流程构建高质量的微调数据集,提升模型在特定任务上的表现。LongRAG的技术原理检索增强生成(RAG):基于RAG框架,检索外部知识辅助语言模型生成回答。全局信息和细节信息的整合:系统不仅关注局部事实细节,还整合长文本中的全局信息,提供更全面的答案。映射策略:将检索到的片段映射回原始长文本,恢复上下文信息,提供更准确的背景结构。链式思考(CoT):用CoT作为全球线索,指导模型逐步关注与问题相关的知识,提高证据密度。过滤策略:基于CoT的全局线索,过滤掉不相关的信息片段,保留关键的事实细节。LongRAG的项目地址GitHub仓库:https://github.com/QingFei1/LongRAGarXiv技术论文:https://arxiv.org/pdf/2410.18050LongRAG的应用场景客户服务与支持:在客户服务领域,理解和回答长篇的客户查询或历史交互记录,提供更准确的回答和解决方案。医疗咨询:在医疗行业处理大量的病人记录和医学文献,回答医生或病人关于疾病、治疗和药物的复杂问题。法律咨询:帮助法律专业人士基于分析大量的法律文件和案例,提供关于法律问题的深入分析和建议。教育与研究:在教育领域,作为辅助工具,帮助学生和研究人员深入理解长篇学术文章和研究报告,回答研究相关的问题。企业决策支持:分析市场研究报告、企业年报等长篇文档,为商业决策提供数据支持和洞察。