
GLM-Zero是智谱AI基于扩展强化学习技术的推理模型,专注于提升模型的深度推理能力。擅长处理数理逻辑、代码编写和复杂问题解决,在AIME 2024、MATH500和LiveCodeBench等评测中表现优异,与 Open...
网站首页 > AI工具
-

-

RAG Logger是开源的日志记录工具,专为检索增强生成(RAG)应用设计。作为LangSmith的轻量级替代品,专注于满足RAG应用的日志记录需求。RAG Logger提供查询跟踪、检索结果记录、LLM交互记录和性能监控...
-
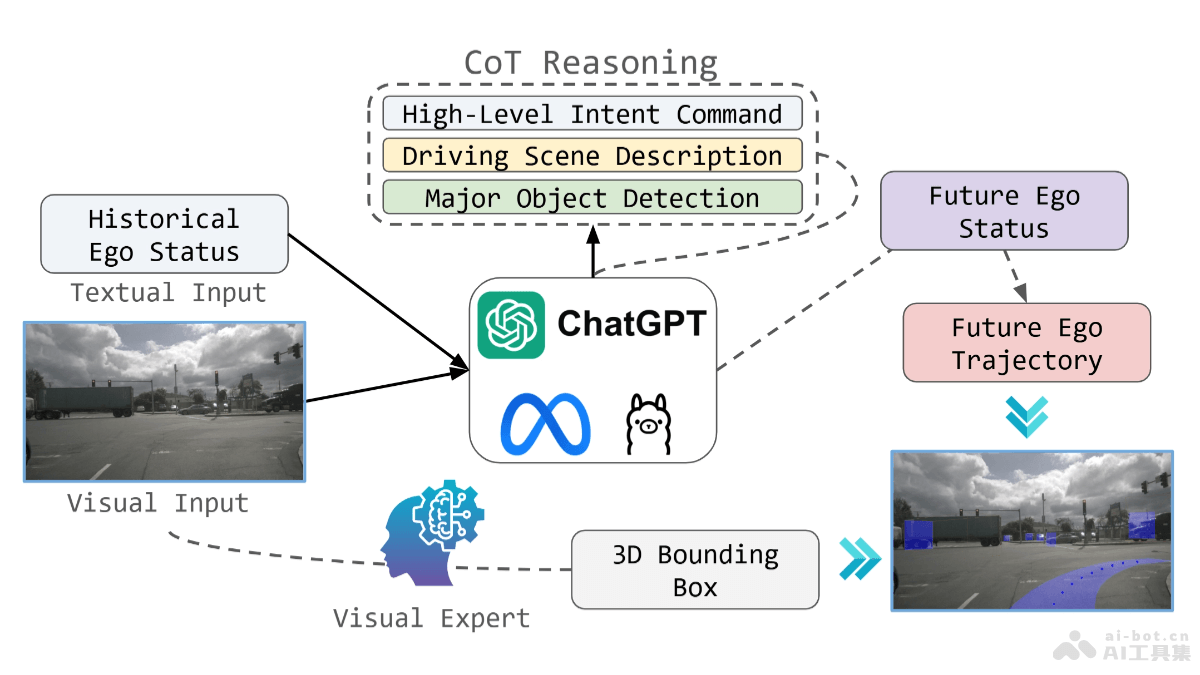
OpenEMMA是德州农工大学、密歇根大学和多伦多大学共同开源的端到端自动驾驶多模态模型框架,基于预训练的多模态大型语言模型(MLLMs)处理视觉数据和复杂驾驶场景的推理。框架基于链式思维推理过程,显著提高模型在轨迹规划和感...
-
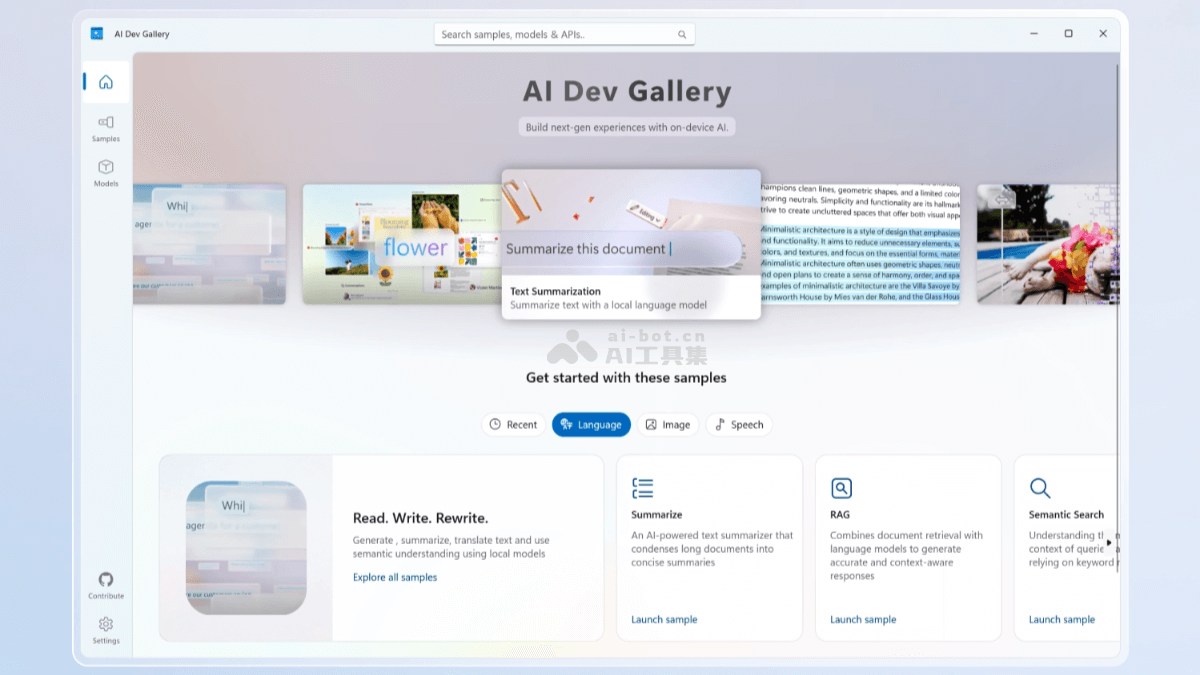
AI Dev Gallery是微软推出的开源AI工具包和示例库,集成在Visual Studio中,帮助Windows开发者轻松集成端侧AI功能。AI Dev Gallery提供超过25个交互式示例,覆盖文本、图像、音频和视...
-

VideoVAE+(VideoVAE Plus)是香港科技大学团队推出的先进的跨模态视频变分自编码器(Video VAE),通过引入新的时空分离压缩机制和文本指导,实现了对大幅运动视频的高效压缩与精准重建,同时保持了良好的时...
-
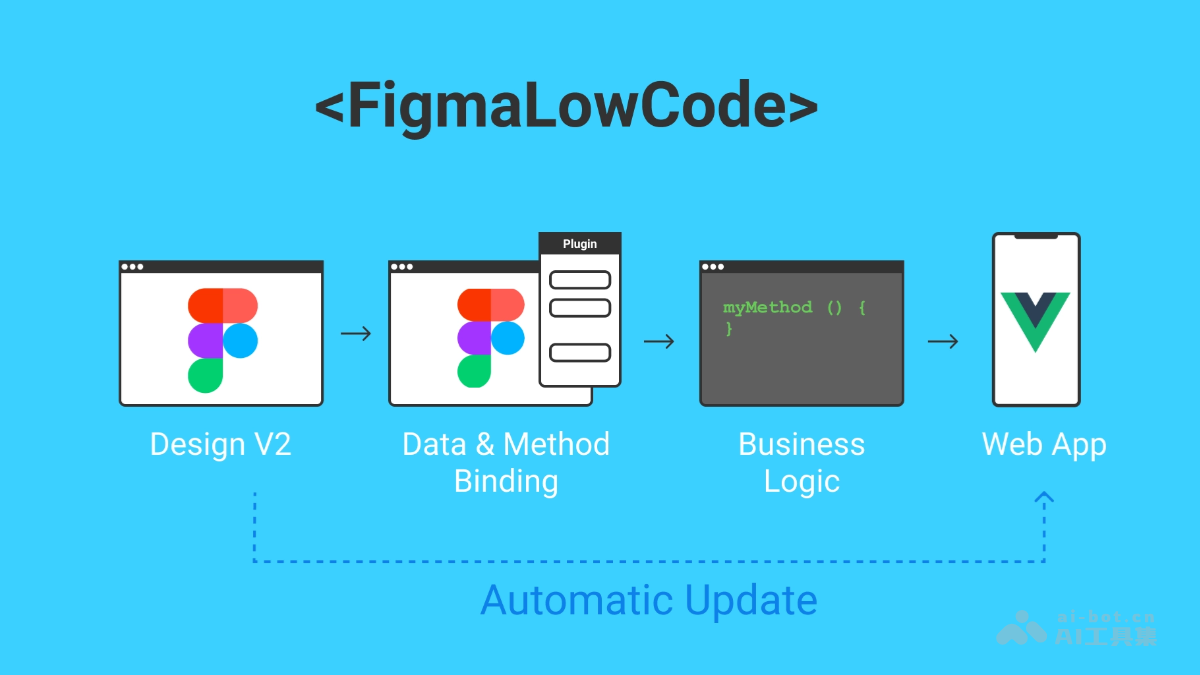
Figma-Low-Code是开源的项目,基于Luisa框架,支持开发者直接将Figma设计转换为Vue.js应用程序。大幅减少设计师与开发者之间的交接时间,减少前端编码工作,确保Figma设计作为唯一的数据源。Figma-...
-

Languine 是 AI 驱动的翻译工具,能帮助开发者简化应用程序的开发过程。Languine 基于智能检测、AI 翻译、自动化工作流程和开发者友好的设计,让翻译管理变得高效且一致。Languine 支持超过100种语言,...
-
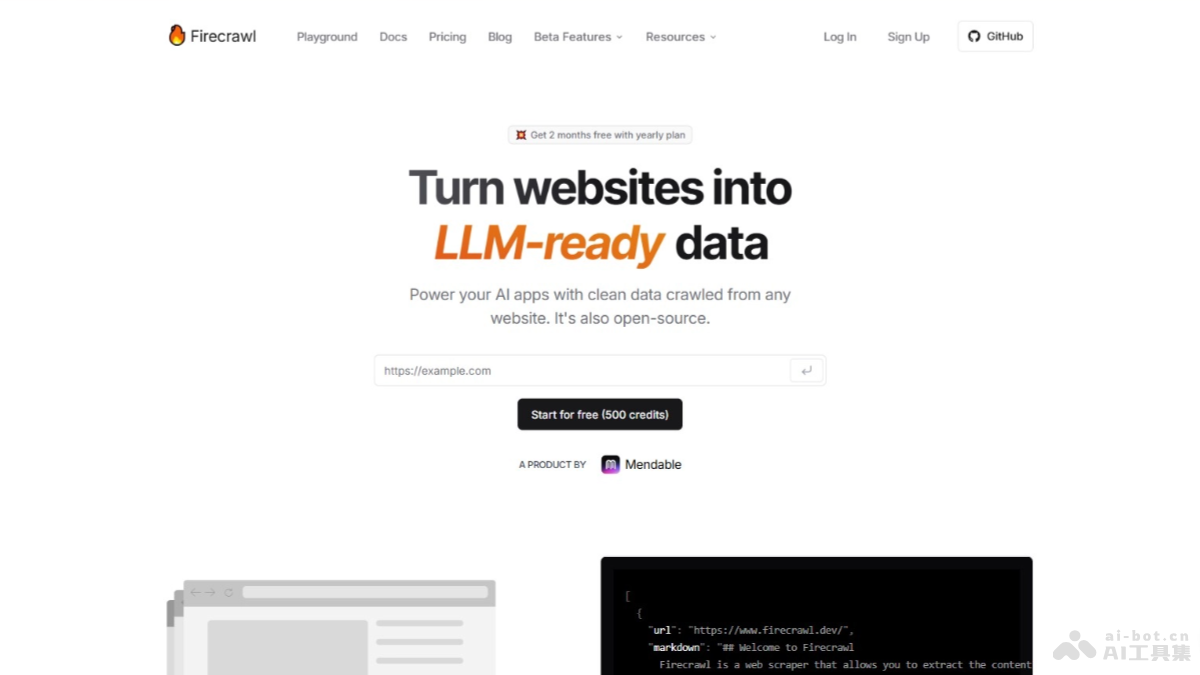
FireCrawl是开源的AI爬虫工具,专门用在Web数据提取,转换为Markdown或其他结构化数据。FireCrawl具备强大的抓取能力,支持动态网页内容处理,提供智能爬取状态管理和多样的输出格式。FireCrawl集成...
-

AgiBot World是智元机器人开源的百万真机数据集,旨在推动具身智能的发展。数据集包含八十余种日常技能,覆盖家居、餐饮、工业等五大核心场景,数据规模和质量远超谷歌的Open X-Embodiment。...
-

GraphAgent是香港大学和香港科技大学(广州)联合推出的智能图形语言助手,能处理现实世界中结构化(如图连接)和非结构化(如文本、视觉信息)格式的数据,数据包含复杂关系和相互依赖性,能用知识图谱展示。...
