
HourVideo是斯坦福大学李飞飞和吴佳俊团队推出的长视频理解基准数据集,包含500个第一人称视角视频,时长20至120分钟,覆盖77种日常活动,能评估多模态模型对长视频的理解能力。...
网站首页 > AI工具 第38页
-

-

DimensionX是香港科技大学、清华大学和生数科技共同推出的框架,能从单张图片生成高逼真度的3D和4D场景,基于视频扩散技术实现对空间和时间维度的精确控制。框架基于ST-Director技术解耦空间和时间因素,支持独立或...
-

FabricDiffusion是谷歌和卡内基梅隆大学共同推出的高保真度3D服装生成技术,能将现实世界中2D服装图像的纹理和印花高质量地转移到任意形状的3D服装模型上。FabricDiffusion基于去噪扩散模型和大规模合成...
-
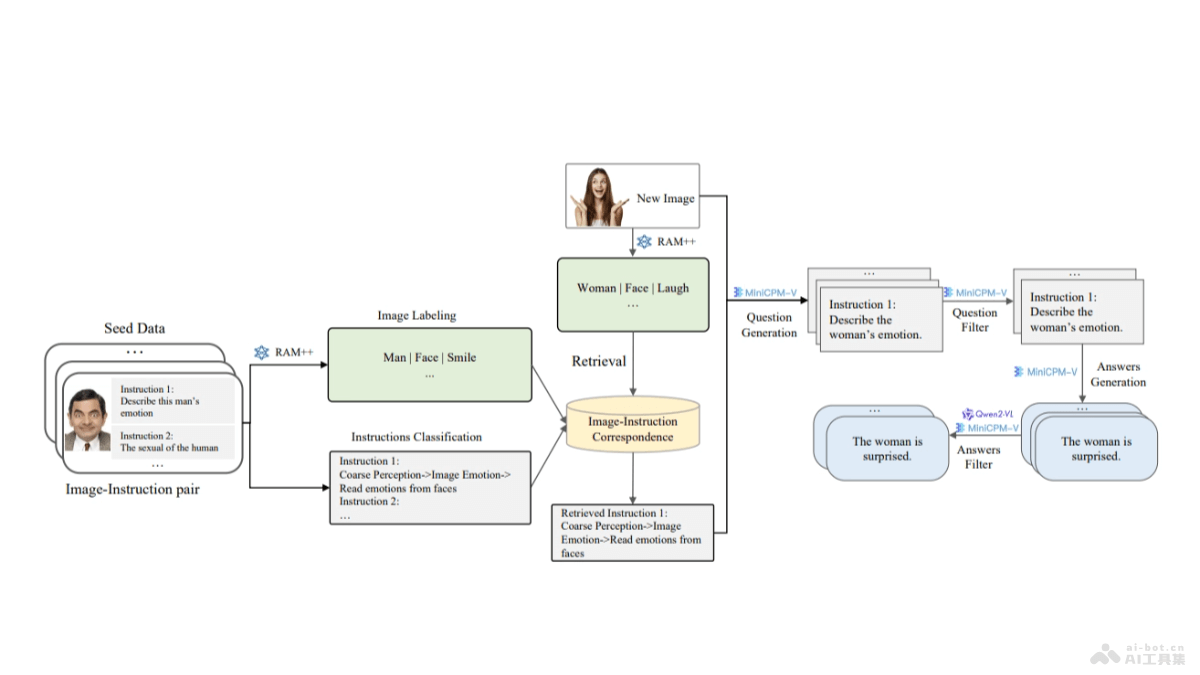
Infinity-MM是智源研究院推出的千万级多模态指令数据集,包含4300万条样本,数据量达10TB。数据集经过质量过滤和去重,确保高质量和多样性,能提升开源视觉-语言模型(VLMs)的性能。智源推出基于开源VLMs的合成...
-

OpenCoder是墨尔本大学、复旦大学等高校研究人员联合无限光年推出的开源代码大型语言模型(LLM),能提升开源代码LLM的性能至专有模型水平,推动代码AI研究的透明化和可重复性。OpenCoder提供模型权重和推理代码,...
-
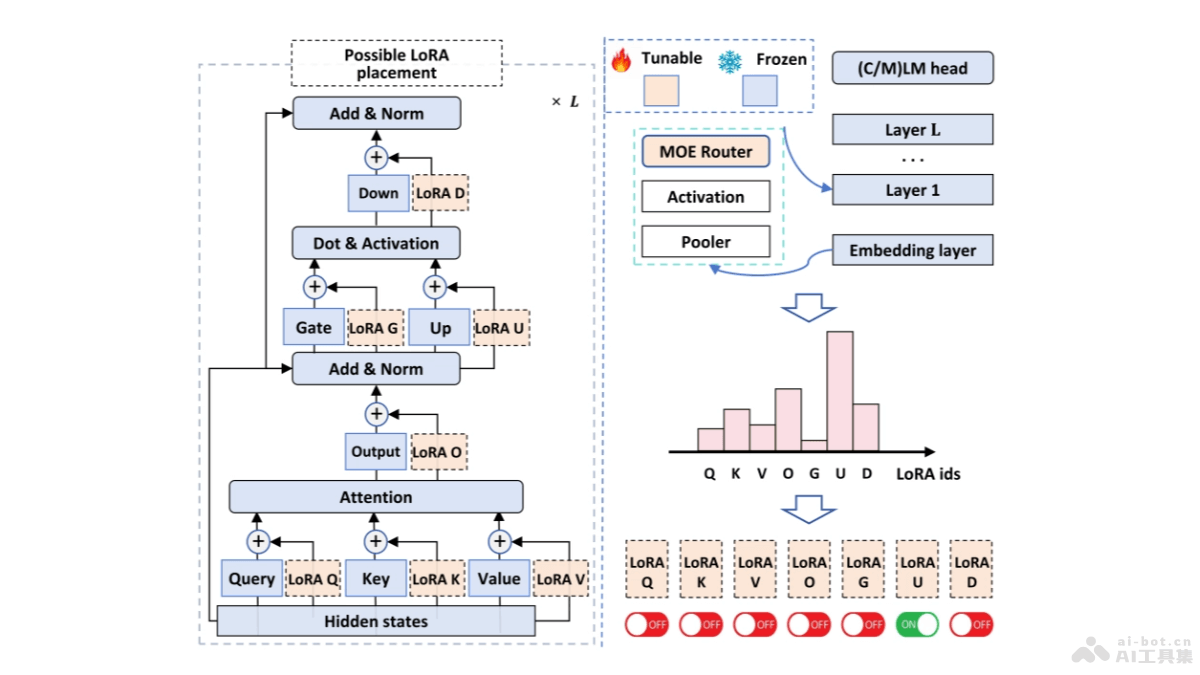
MiLoRA是参数高效的大型语言模型(LLMs)微调方法,通过更新权重分量来矩阵的次要奇异减少计算和内存成本。方法基于奇异值分解(SVD)将权重矩阵分为主要和次要两部分,主要部分包含重要知识,次要部分包含噪声或长尾信息。...
-

CogVideoX v1.5是智谱最新开源的AI视频生成模型。模型包含CogVideoX v1.5-5B和CogVideoX v1.5-5B-I2V两个版本,5B 系列模型支持生成5至10秒、768P分辨率、16帧的视频,I...
-

AdaCache(Adaptive Caching)是Meta推出的开源技术,能加速AI视频生成过程。AdaCache自适应缓存机制优化计算资源分配,根据不同视频内容的复杂度动态调整计算量,减少不必要的计算开销。AdaCac...
-

AgentSquare是清华大学团队推出自动搜索和优化大型语言模型(LLM)代理的框架。基于标准化的模块接口抽象,实现AI智能体的高速自我演化和自适应演进。框架包含任务规划、常识推理、工具使用和记忆学习四个核心模块,支持智能...
-

CogSound是智谱AI最新推出的音效模型,能为无声视频增添动人的音效。 基于GLM-4V的视频理解能力,CogSound能精准识别理解视频背后的语义和情感,为无声视频添加与之相匹配的音频内容,可以生成更复杂的音效,如爆炸...
