
Olly.bot是集成于iMessage和SMS的个人AI助手,基于OpenAI大模型,提供网络搜索、文档分析、图片生成等功能。Olly.bot无需下载、注册,不收集用户身份信息,保护隐私。支持iOS、macOS、Andro...
网站首页 > AI工具 第39页
-
-
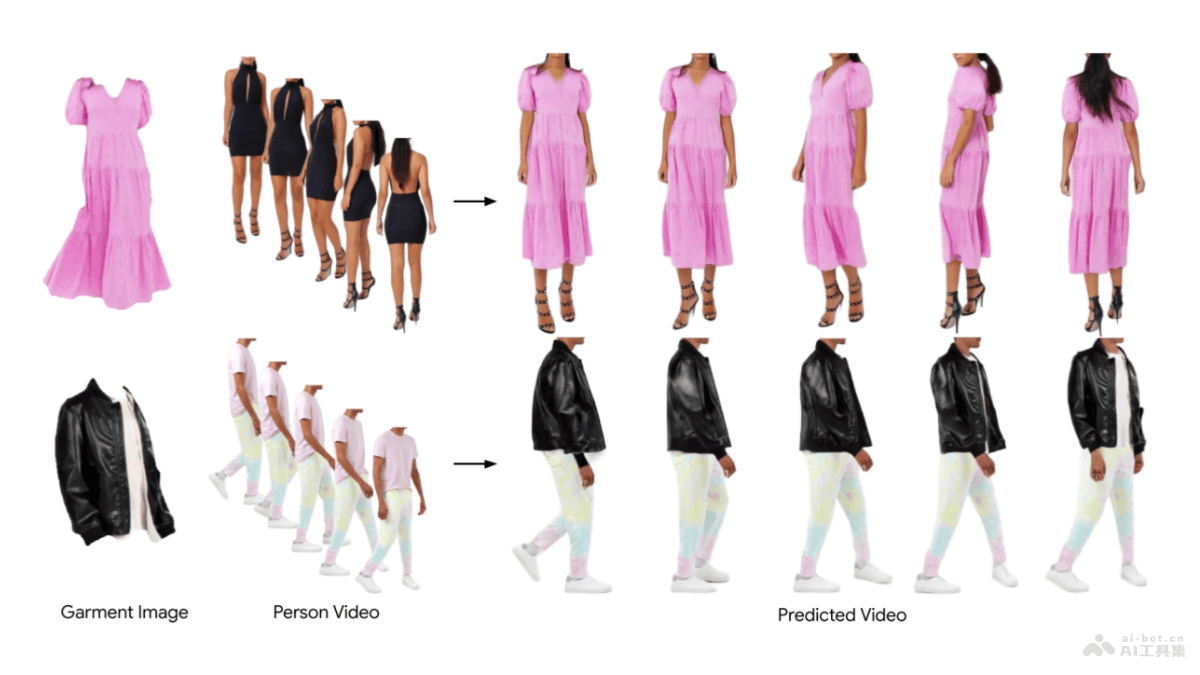
Fashion-VDM是谷歌和华盛顿大学共同推出的基于视频扩散模型(VDM)的虚拟试穿技术。能在给定服装图像和人物视频的情况下,生成人物穿着指定服装的高质量试穿视频,保留人物的身份和动作。Fashion-VDM基于扩散模型架...
-

Ichigo是开源的多模态AI语音助手,采用混合模态模型,能实时处理语音和文本的交织序列。基于将语音直接量化为离散令牌,用统一的变换器架构同时处理语音和文本,实现跨模态的联合推理和生成。...
-

Recraft V3是Recraft公司推出的AI文本到图像生成模型,在Hugging Face的文本到图像模型排行榜上以1172的ELO评分荣获第一。模型具有高质量的图像生成和先进的设计控制功能,支持用户精确定位文本和元素...
-

Magentic-One 是微软推出的通用多智能体系统,解决跨领域的复杂网络和文件任务。系统基于多智能体架构,由Orchestrator智能体领导,协调WebSurfer、FileSurfer、Coder和ComputerT...
-
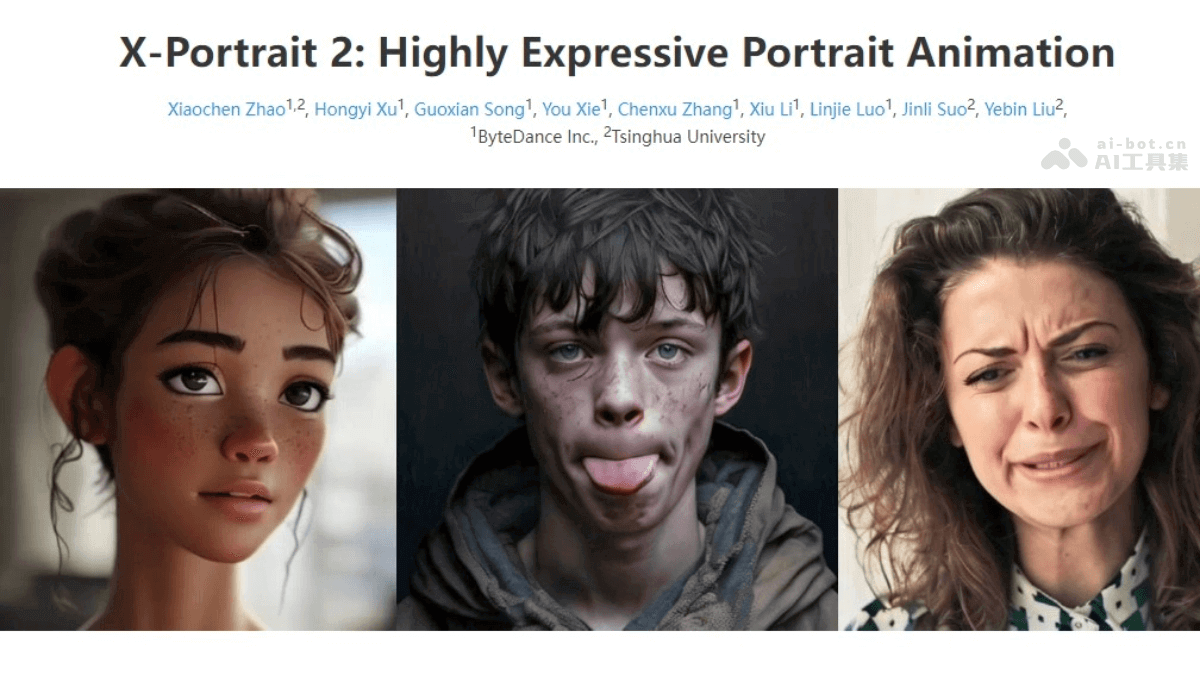
X-Portrait 2是字节跳动智能创作团队推出的单图视频驱动技术,基于一张静态照片和一段驱动视频生成高质量、电影级视频。X-Portrait 2保留原图身份特征,准确捕捉细微表情和情绪,实现跨风格动作迁移,适用于写实人像...
-
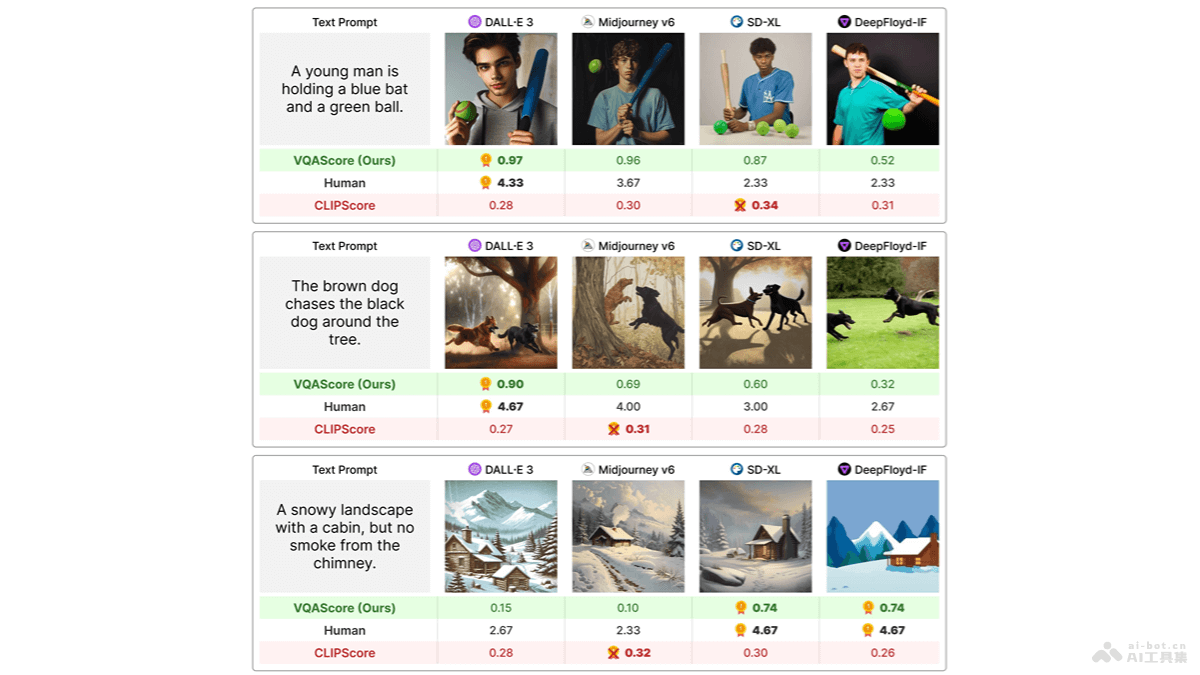
VQAScore是CMU和Meta联合推出的评估方法,基于视觉问答(VQA)模型衡量由文本提示生成的图像质量。VQAScore用计算模型对“Does this figure show {text}?”这一问题回答“是”的概率...
-

AndroidLab是用在训练和系统评估Android自主代理的框架,集成文本和图像模态操作环境,统一行动空间和可重现基准测试。AndroidLab支持大型语言模型和多模态模型,包含138个任务,覆盖九个应用。基于Andro...
-
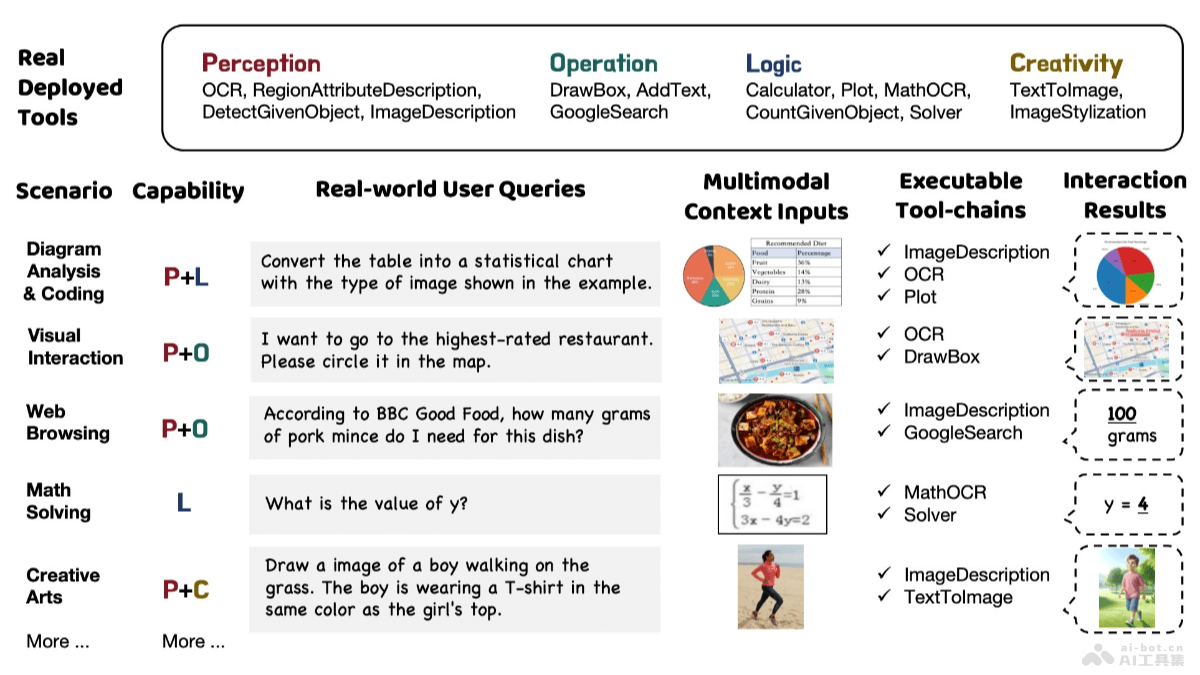
GTA(a benchmark for General Tool Agents)是上海交通大学和上海AI实验室共同推出的基准测试,评估大型语言模型(LLMs)在真实世界场景中调用工具的能力。GTA基于提供真实的用户问题、真实...
-

OuteTTS是开源的文本到语音(TTS)项目,基于纯语言建模的方法生成语音。OuteTTS项目基于LLaMa架构,用Oute3-350M-DEV基础模型,拥有3.5亿参数。OuteTTS具备音频标记化、CTC强制对齐技术和...
