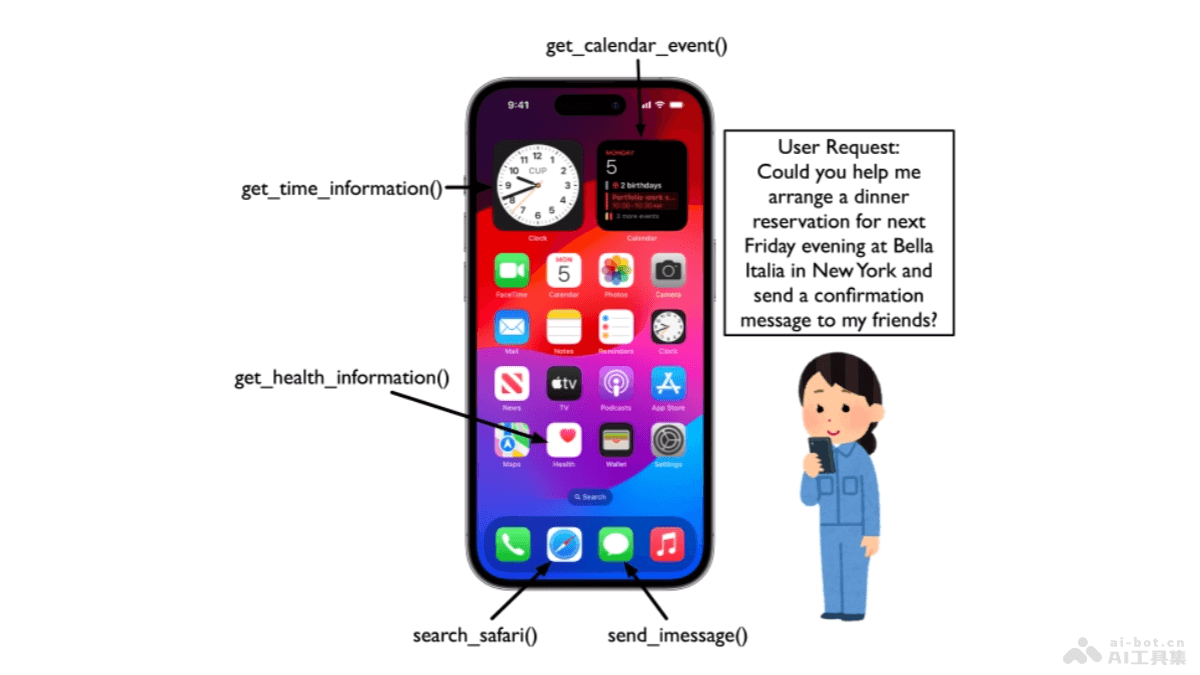
XGrammar是由陈天奇团队推出的开源软件库,能为大型语言模型(LLM)提供高效、灵活且可移植的结构化数据生成能力。基于上下文无关语法(CFG)定义结构,支持递归组合以表示复杂结构,适合生成JSON、SQL等格式数据。XGrammar用字节级下推自动机优化解释CFG,减少每token延迟,实现百倍加速,几乎无额外开销。XGrammar集成多种系统优化,如自适应token掩码缓存、上下文扩展等,提高掩码生成速度并减少预处理时间。XGrammar的C++后端设计易于集成,并支持在LLM推理中实现零开销的结构化生成。
 XGrammar的主要功能高效结构化生成:支持上下文无关语法(CFG),支持定义和生成遵循特定格式(如JSON、SQL)的结构化数据。灵活性:基于CFG的递归规则,能灵活地表示复杂的结构,适应多样的结构化数据需求。零开销集成:XGrammar与LLM推理引擎共同设计,能在LLM推理中实现零开销的结构化生成。快速执行:基于系统优化,显著提高结构化生成的执行速度,相比于SOTA方法,每token延迟减少多达100倍。跨平台部署:具有最小且可移植的C++后端,能轻松集成到多个环境和框架中。自适应token掩码缓存:在预处理阶段生成,加快运行时的掩码生成。XGrammar的技术原理字节级下推自动机(PDA):用字节级PDA解释CFG,支持每个字符边缘包含一个或多个字节,处理不规则的token边界,支持包含sub-UTF8字符的token。预处理和运行时优化:在预处理阶段,生成自适应token掩码缓存,基于预先计算与上下文无关的token加快运行时的掩码生成。上下文无关与相关token的区分:区分上下文无关token和上下文相关token,预先计算PDA中每个位置的上下文无关token的有效性,并将它们存储在自适应token掩码缓存中。语法编译:基于语法编译过程,预先计算掩码中相当一部分token,加快掩码生成速度。算法和系统优化:包括上下文扩展、持续性执行堆栈、下推自动机结构优化等,进一步提高掩码生成速度并减少预处理时间。掩码生成与LLM推理重叠:将CPU上的掩码生成过程与GPU上的LLM推理过程并行化,消除约束解码的开销。XGrammar的项目地址项目官网:xgrammar.mlc.aiGitHub仓库:https://github.com/mlc-ai/xgrammararXiv技术论文:https://arxiv.org/pdf/2411.15100XGrammar的应用场景编程语言辅助:用于辅助编写和调试代码,自动生成符合特定编程语言规范的代码片段,提高开发效率。数据库操作:生成符合SQL语法的查询语句,帮助开发者或应用程序自动构建数据库查询,减少手动编写SQL语句的工作量。自然语言处理(NLP):生成结构化的训练数据,用于训练和优化NLP模型,提高模型对结构化信息的处理能力。Web开发:自动生成前端代码和API文档,确保文档与代码的一致性,提高开发效率和维护性。配置文件和模板:生成和填充配置文件及模板,如自动化生成系统配置、填充邮件模板等,提高自动化水平。
XGrammar的主要功能高效结构化生成:支持上下文无关语法(CFG),支持定义和生成遵循特定格式(如JSON、SQL)的结构化数据。灵活性:基于CFG的递归规则,能灵活地表示复杂的结构,适应多样的结构化数据需求。零开销集成:XGrammar与LLM推理引擎共同设计,能在LLM推理中实现零开销的结构化生成。快速执行:基于系统优化,显著提高结构化生成的执行速度,相比于SOTA方法,每token延迟减少多达100倍。跨平台部署:具有最小且可移植的C++后端,能轻松集成到多个环境和框架中。自适应token掩码缓存:在预处理阶段生成,加快运行时的掩码生成。XGrammar的技术原理字节级下推自动机(PDA):用字节级PDA解释CFG,支持每个字符边缘包含一个或多个字节,处理不规则的token边界,支持包含sub-UTF8字符的token。预处理和运行时优化:在预处理阶段,生成自适应token掩码缓存,基于预先计算与上下文无关的token加快运行时的掩码生成。上下文无关与相关token的区分:区分上下文无关token和上下文相关token,预先计算PDA中每个位置的上下文无关token的有效性,并将它们存储在自适应token掩码缓存中。语法编译:基于语法编译过程,预先计算掩码中相当一部分token,加快掩码生成速度。算法和系统优化:包括上下文扩展、持续性执行堆栈、下推自动机结构优化等,进一步提高掩码生成速度并减少预处理时间。掩码生成与LLM推理重叠:将CPU上的掩码生成过程与GPU上的LLM推理过程并行化,消除约束解码的开销。XGrammar的项目地址项目官网:xgrammar.mlc.aiGitHub仓库:https://github.com/mlc-ai/xgrammararXiv技术论文:https://arxiv.org/pdf/2411.15100XGrammar的应用场景编程语言辅助:用于辅助编写和调试代码,自动生成符合特定编程语言规范的代码片段,提高开发效率。数据库操作:生成符合SQL语法的查询语句,帮助开发者或应用程序自动构建数据库查询,减少手动编写SQL语句的工作量。自然语言处理(NLP):生成结构化的训练数据,用于训练和优化NLP模型,提高模型对结构化信息的处理能力。Web开发:自动生成前端代码和API文档,确保文档与代码的一致性,提高开发效率和维护性。配置文件和模板:生成和填充配置文件及模板,如自动化生成系统配置、填充邮件模板等,提高自动化水平。