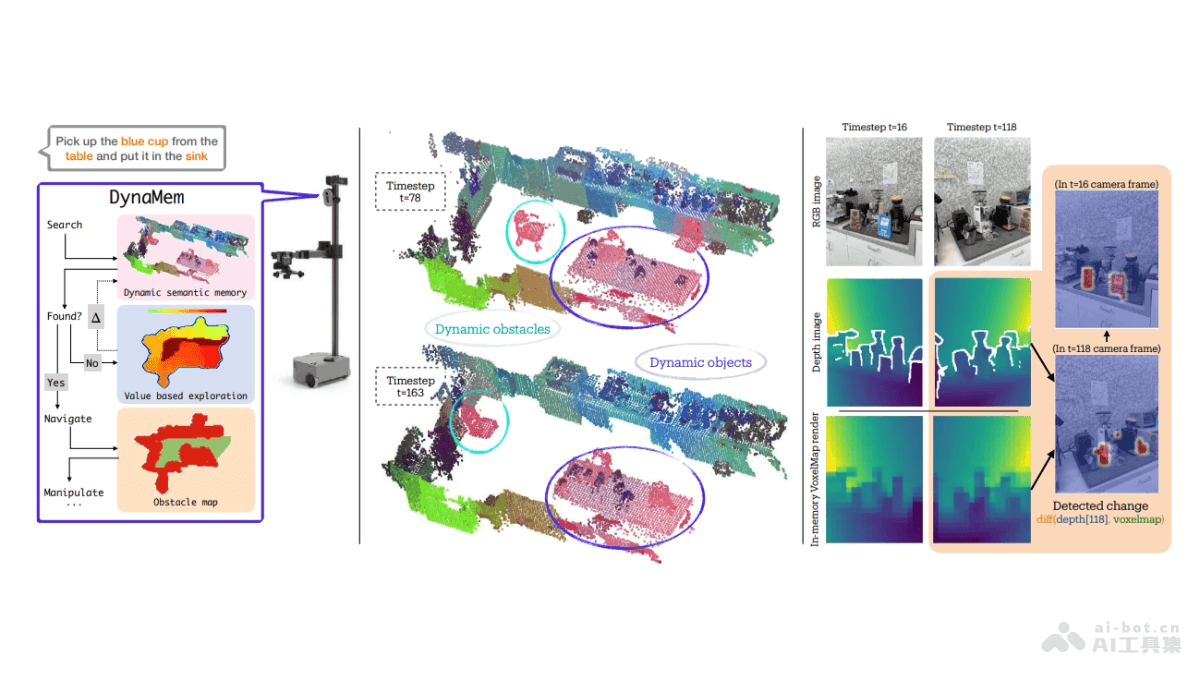
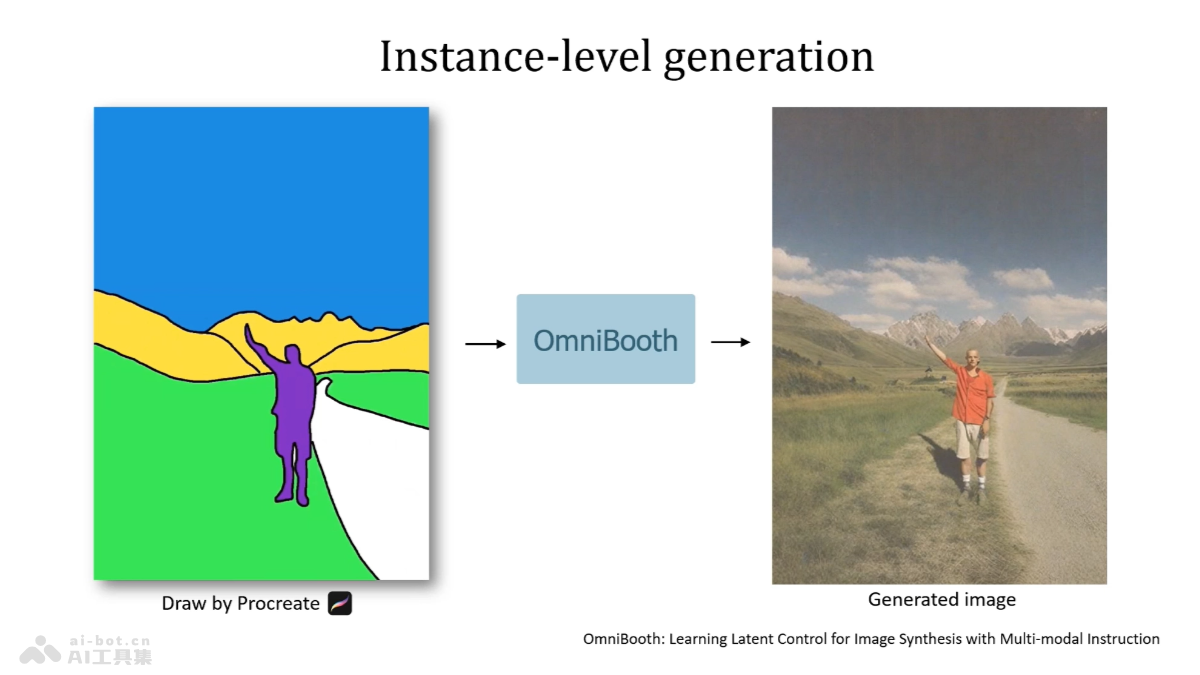
LongCite是由清华大学推出的项目,旨在提升大型语言模型(LLMs)在长文本问答任务中的可信度和可验证性。项目通过生成细粒度的句子级引用,使用户能验证模型的回答是否准确。核心组成部分包括LongBench-Cite评估基准、CoF自动化数据构建流程、LongCite-45k数据集,以及基于该数据集训练的LongCite-8B和LongCite-9B模型。模型能理解长文本内容并提供准确的问答服务,同时附上直接查阅的文本引用,增强信息的透明度和可靠性。
 LongCite的主要功能生成细粒度引用:LongCite使语言模型在回答长文本问题时,生成精确到句子级别的引用,用户能直接追溯到原文中的具体信息。提高回答的忠实度:LongCite有助于确保模型的回答更加忠实于原文,减少模型出现的“幻觉”(即生成与原文不符的信息)。增强可验证性:用户基于模型提供的细粒度引用来验证回答的真实性和准确性,提高模型输出的可信度。自动化数据构建:LongCite采用了CoF(Coarse to Fine)流程,自动化地生成带有细粒度引用的高质量长文本问答数据,为模型训练提供丰富的标注资源。评测基准:LongCite引入LongBench-Cite评测基准,用于衡量模型在长文本问答中生成引用的能力,包括正确性和引用质量。LongCite的技术原理长文本处理能力:LongCite支持超长上下文窗口的大型语言模型(如GLM-4-9B-1M,Gemini 1.5等),能处理和理解长达数万字的文本。细粒度引用生成:LongCite训练模型生成精确到句子级别的引用,使每个回答都能追溯到原文的具体句子,提高了回答的可验证性。自动化数据构建流程(CoF):使用自指导(Self-Instruct)方法自动从长文本中生成问题和答案对。从长文本中检索与答案相关的句子块,并生成块级引用。在块级引用的基础上,提取出支持每个陈述的具体句子,生成句子级引用。监督式微调(Supervised Fine-Tuning, SFT):CoF流程生成的带有细粒度引用的高质量数据集对大型语言模型进行微调,提升模型在长文本问答任务中的表现。LongCite的项目地址GitHub仓库:https://github.com/THUDM/LongCiteHuggingFace模型库:https://huggingface.co/THUDMarXiv技术论文:https://arxiv.org/pdf/2409.02897LongCite的应用场景学术研究:研究人员和学者用LongCite来查询大量的文献资料,并获取带有引用的详细答案,支持研究工作。法律咨询:法律专业人士用LongCite分析法律文档,获取具体的法律条文或案例引用,支持法律分析和案件研究。金融分析:金融分析师和投资者使用LongCite来理解复杂的金融报告和市场研究,获取关键数据和趋势的准确引用。医疗咨询:医疗专业人员依赖LongCite来查询医疗文献,获取基于最新研究成果的诊断和治疗建议的引用。新闻报道:记者和新闻机构用LongCite验证报道中的信息,确保发布的新闻内容准确无误,并提供可靠的来源引用。
LongCite的主要功能生成细粒度引用:LongCite使语言模型在回答长文本问题时,生成精确到句子级别的引用,用户能直接追溯到原文中的具体信息。提高回答的忠实度:LongCite有助于确保模型的回答更加忠实于原文,减少模型出现的“幻觉”(即生成与原文不符的信息)。增强可验证性:用户基于模型提供的细粒度引用来验证回答的真实性和准确性,提高模型输出的可信度。自动化数据构建:LongCite采用了CoF(Coarse to Fine)流程,自动化地生成带有细粒度引用的高质量长文本问答数据,为模型训练提供丰富的标注资源。评测基准:LongCite引入LongBench-Cite评测基准,用于衡量模型在长文本问答中生成引用的能力,包括正确性和引用质量。LongCite的技术原理长文本处理能力:LongCite支持超长上下文窗口的大型语言模型(如GLM-4-9B-1M,Gemini 1.5等),能处理和理解长达数万字的文本。细粒度引用生成:LongCite训练模型生成精确到句子级别的引用,使每个回答都能追溯到原文的具体句子,提高了回答的可验证性。自动化数据构建流程(CoF):使用自指导(Self-Instruct)方法自动从长文本中生成问题和答案对。从长文本中检索与答案相关的句子块,并生成块级引用。在块级引用的基础上,提取出支持每个陈述的具体句子,生成句子级引用。监督式微调(Supervised Fine-Tuning, SFT):CoF流程生成的带有细粒度引用的高质量数据集对大型语言模型进行微调,提升模型在长文本问答任务中的表现。LongCite的项目地址GitHub仓库:https://github.com/THUDM/LongCiteHuggingFace模型库:https://huggingface.co/THUDMarXiv技术论文:https://arxiv.org/pdf/2409.02897LongCite的应用场景学术研究:研究人员和学者用LongCite来查询大量的文献资料,并获取带有引用的详细答案,支持研究工作。法律咨询:法律专业人士用LongCite分析法律文档,获取具体的法律条文或案例引用,支持法律分析和案件研究。金融分析:金融分析师和投资者使用LongCite来理解复杂的金融报告和市场研究,获取关键数据和趋势的准确引用。医疗咨询:医疗专业人员依赖LongCite来查询医疗文献,获取基于最新研究成果的诊断和治疗建议的引用。新闻报道:记者和新闻机构用LongCite验证报道中的信息,确保发布的新闻内容准确无误,并提供可靠的来源引用。