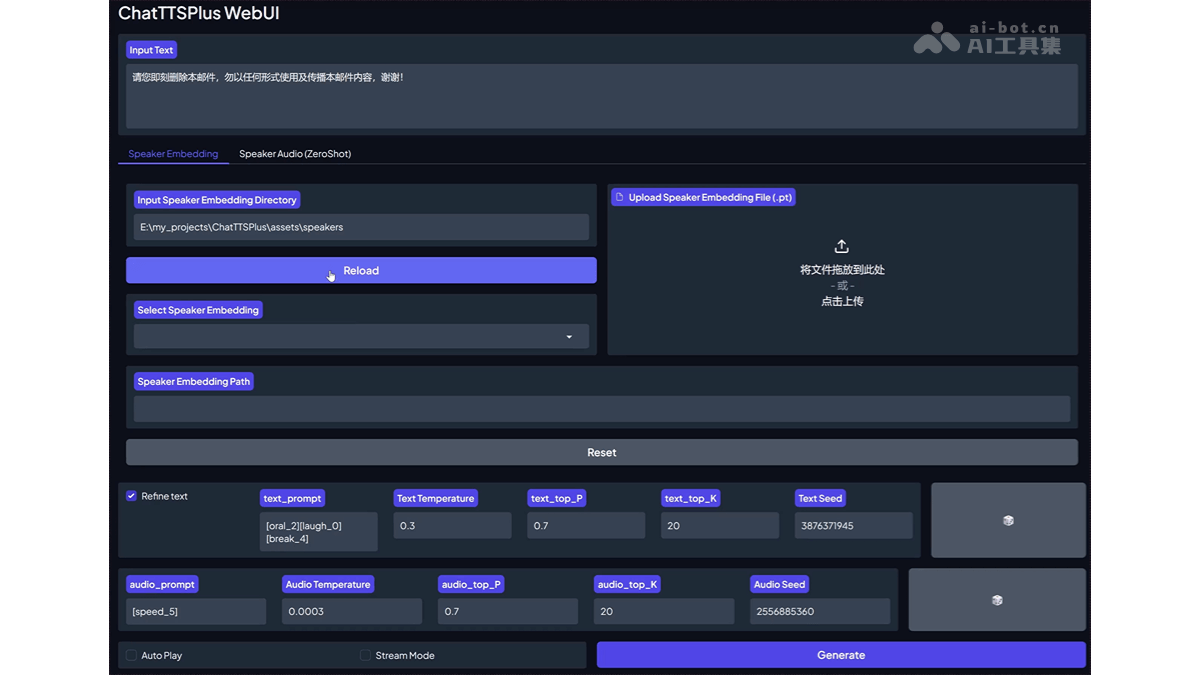
FLOAT是DeepBrain AI 和韩国先进科技研究院推出的音频驱动说话人头像生成模型,基于流匹配生成模型,学习运动潜在空间实现高效的时间一致性运动设计。模型基于Transformer架构的向量场预测器,实现帧间时间一致性,支持语音驱动的情感增强,让生成的说话动作更自然、富有表现力。FLOAT在视觉质量、运动保真度和生成效率方面均超越现有的基于扩散和非扩散的方法,达到业界领先水平。
 FLOAT的主要功能音频驱动的说话人像生成:根据单一源图像和驱动音频生成说话人像视频,实现音频同步的头部动作,包括言语和非言语动作。时间一致性视频生成:在运动潜在空间内建模,FLOAT生成的视频在时间上具有高度一致性,解决传统基于扩散模型的视频生成中的时间连贯性问题。情感增强:用语音驱动的情感标签,增强视频中的情感表达,让生成的说话动作更加自然和富有表现力。高效采样:基于流匹配技术,提高视频生成的采样速度和效率。FLOAT的技术原理运动潜在空间:将生成建模从像素潜在空间转移到学习的运动潜在空间,更有效地捕捉和生成时间上连贯的运动。流匹配:基于流匹配在运动潜在空间中高效地采样,生成时间一致的运动序列。基于Transformer的向量场预测器:基于Transformer的架构预测生成流的向量场,预测器能处理帧条件并生成时间一致的运动。帧条件机制:基于简单的帧条件机制,将驱动音频和其他条件(如情感标签)整合到生成过程中,实现对运动潜在空间的有效控制。情感控制:用预训练的语音情感预测器生成情感标签,将标签作为条件输入到向量场预测器中,在生成过程中引入情感控制。快速采样与高效生成:基于流匹配技术减少生成过程中的迭代次数,实现快速采样,保持生成视频的高质量。FLOAT的项目地址项目官网:deepbrainai-research.github.io/floatarXiv技术论文:https://arxiv.org/pdf/2412.01064FLOAT的应用场景虚拟主播和虚拟助手:在新闻播报、天气预报、在线教育等领域,生成逼真的虚拟主播,提供24小时不间断的节目制作。视频会议和远程通信:在视频会议中,创建用户的虚拟形象,即使在没有摄像头的情况下也能进行视频交流。社交媒体和娱乐:在社交媒体平台上,用户生成自己的虚拟形象,用在直播、互动娱乐或虚拟社交。游戏和虚拟现实:在游戏和虚拟现实应用中,于创建或自定义游戏角色的面部表情和动作,提升沉浸感。电影和动画制作:在电影后期制作中,生成或增强角色的面部表情和口型,减少传统动作捕捉的需求。
FLOAT的主要功能音频驱动的说话人像生成:根据单一源图像和驱动音频生成说话人像视频,实现音频同步的头部动作,包括言语和非言语动作。时间一致性视频生成:在运动潜在空间内建模,FLOAT生成的视频在时间上具有高度一致性,解决传统基于扩散模型的视频生成中的时间连贯性问题。情感增强:用语音驱动的情感标签,增强视频中的情感表达,让生成的说话动作更加自然和富有表现力。高效采样:基于流匹配技术,提高视频生成的采样速度和效率。FLOAT的技术原理运动潜在空间:将生成建模从像素潜在空间转移到学习的运动潜在空间,更有效地捕捉和生成时间上连贯的运动。流匹配:基于流匹配在运动潜在空间中高效地采样,生成时间一致的运动序列。基于Transformer的向量场预测器:基于Transformer的架构预测生成流的向量场,预测器能处理帧条件并生成时间一致的运动。帧条件机制:基于简单的帧条件机制,将驱动音频和其他条件(如情感标签)整合到生成过程中,实现对运动潜在空间的有效控制。情感控制:用预训练的语音情感预测器生成情感标签,将标签作为条件输入到向量场预测器中,在生成过程中引入情感控制。快速采样与高效生成:基于流匹配技术减少生成过程中的迭代次数,实现快速采样,保持生成视频的高质量。FLOAT的项目地址项目官网:deepbrainai-research.github.io/floatarXiv技术论文:https://arxiv.org/pdf/2412.01064FLOAT的应用场景虚拟主播和虚拟助手:在新闻播报、天气预报、在线教育等领域,生成逼真的虚拟主播,提供24小时不间断的节目制作。视频会议和远程通信:在视频会议中,创建用户的虚拟形象,即使在没有摄像头的情况下也能进行视频交流。社交媒体和娱乐:在社交媒体平台上,用户生成自己的虚拟形象,用在直播、互动娱乐或虚拟社交。游戏和虚拟现实:在游戏和虚拟现实应用中,于创建或自定义游戏角色的面部表情和动作,提升沉浸感。电影和动画制作:在电影后期制作中,生成或增强角色的面部表情和口型,减少传统动作捕捉的需求。