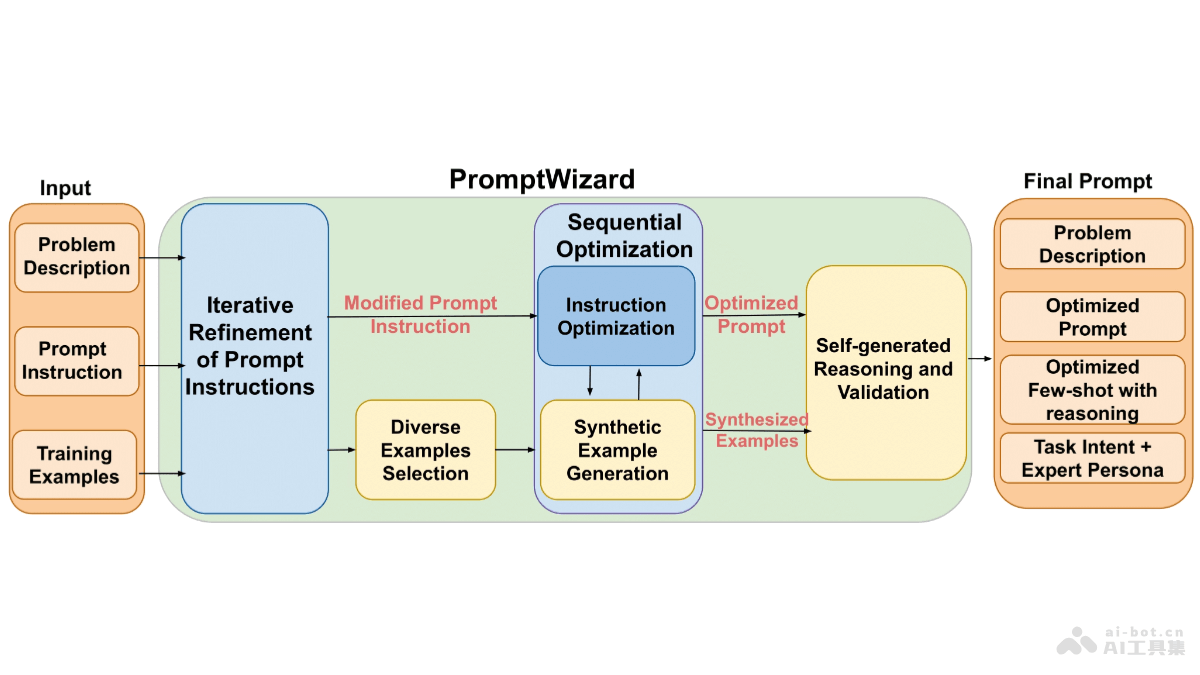
INFP是音频驱动的头部生成框架,专为双人对话交互设计。能自动在对话音频引导下进行角色的转换,无需手动分配角色和角色切换。INFP包括两个阶段:基于动作头部模仿阶段和音频引导动作生成阶段,通过实验和可视化展示,验证了INFP方法的卓越性能和有效性。INFP提出了大规模双人对话数据集DyConv,以支持该研究领域的进步。
 INFP的主要功能角色自动转换:在双人对话中,INFP能自动进行角色的转换,无需手动分配角色和角色切换,增强了交互的自然性和流畅性。轻量与高效:在保持强大功能的同时,INFP还具有轻量级的特性。能够在Nvidia Tesla A10上实现超过40 fps的推理速度,这意味着INFP能够支持实时的智能代理交互,无论是代理之间的沟通还是人与代理的互动。交互式头部生成:INFP包含两个关键阶段:基于运动的头部模仿和音频引导的运动生成。第一阶段将真实对话视频中的面部交流行为编码到低维运动潜在空间,第二阶段则将输入的音频映射到这些运动潜在代码,实现音频驱动的头部生成。大规模双人对话数据集DyConv:为了支持该研究领域的进步,INFP提出了大规模双人对话数据集DyConv,从互联网上收集的丰富的二元对话。INFP的技术原理基于运动的头部模仿阶段:在这个阶段,框架学习将现实生活中的对话视频中的面部交流行为投影到一个低维运动潜在空间。这个过程涉及到从大量真实对话视频中提取面部交流行为,并将其编码为可以驱动静态图像动画的运动潜在代码。音频引导运动生成阶段:在第二阶段,框架学习从输入的双通道音频到运动潜在代码的映射。这一阶段通过去噪过程实现,从而在交互场景中实现音频驱动的头部生成。实时互动与风格控制:INFP支持实时互动,支持用户在对话中随时打断或回应虚拟形象。通过提取任意肖像视频的风格向量,INFP还能够全局控制生成结果中的情绪或态度。INFP的项目地址项目官网:https://grisoon.github.io/INFP/arXiv技术论文:https://www.arxiv.org/pdf/2412.04037INFP的应用场景视频会议与虚拟助手:INFP框架能实现真实感、交互性和实时性,适合实时场景,例如视频会议和虚拟助手等,提供更加自然和流畅的交互体验。社交媒体与互动娱乐:在社交媒体平台或互动娱乐应用中,INFP可以用于生成具有自然表情和头部动作的交互式头像,增强用户的互动体验。教育培训:INFP可以用于创建虚拟教师或培训师,提供更加生动和互动的教学体验。客户服务:在客户服务领域,INFP可以用于生成虚拟客服代表,提供更加人性化的服务。广告与营销:INFP可以用于生成更加吸引人的虚拟代言人,用于广告和营销活动,提供更加逼真和互动的广告体验。游戏与模拟:在游戏和模拟环境中,INFP可以用于创建更加真实和互动的角色,提高游戏的沉浸感和互动性。
INFP的主要功能角色自动转换:在双人对话中,INFP能自动进行角色的转换,无需手动分配角色和角色切换,增强了交互的自然性和流畅性。轻量与高效:在保持强大功能的同时,INFP还具有轻量级的特性。能够在Nvidia Tesla A10上实现超过40 fps的推理速度,这意味着INFP能够支持实时的智能代理交互,无论是代理之间的沟通还是人与代理的互动。交互式头部生成:INFP包含两个关键阶段:基于运动的头部模仿和音频引导的运动生成。第一阶段将真实对话视频中的面部交流行为编码到低维运动潜在空间,第二阶段则将输入的音频映射到这些运动潜在代码,实现音频驱动的头部生成。大规模双人对话数据集DyConv:为了支持该研究领域的进步,INFP提出了大规模双人对话数据集DyConv,从互联网上收集的丰富的二元对话。INFP的技术原理基于运动的头部模仿阶段:在这个阶段,框架学习将现实生活中的对话视频中的面部交流行为投影到一个低维运动潜在空间。这个过程涉及到从大量真实对话视频中提取面部交流行为,并将其编码为可以驱动静态图像动画的运动潜在代码。音频引导运动生成阶段:在第二阶段,框架学习从输入的双通道音频到运动潜在代码的映射。这一阶段通过去噪过程实现,从而在交互场景中实现音频驱动的头部生成。实时互动与风格控制:INFP支持实时互动,支持用户在对话中随时打断或回应虚拟形象。通过提取任意肖像视频的风格向量,INFP还能够全局控制生成结果中的情绪或态度。INFP的项目地址项目官网:https://grisoon.github.io/INFP/arXiv技术论文:https://www.arxiv.org/pdf/2412.04037INFP的应用场景视频会议与虚拟助手:INFP框架能实现真实感、交互性和实时性,适合实时场景,例如视频会议和虚拟助手等,提供更加自然和流畅的交互体验。社交媒体与互动娱乐:在社交媒体平台或互动娱乐应用中,INFP可以用于生成具有自然表情和头部动作的交互式头像,增强用户的互动体验。教育培训:INFP可以用于创建虚拟教师或培训师,提供更加生动和互动的教学体验。客户服务:在客户服务领域,INFP可以用于生成虚拟客服代表,提供更加人性化的服务。广告与营销:INFP可以用于生成更加吸引人的虚拟代言人,用于广告和营销活动,提供更加逼真和互动的广告体验。游戏与模拟:在游戏和模拟环境中,INFP可以用于创建更加真实和互动的角色,提高游戏的沉浸感和互动性。