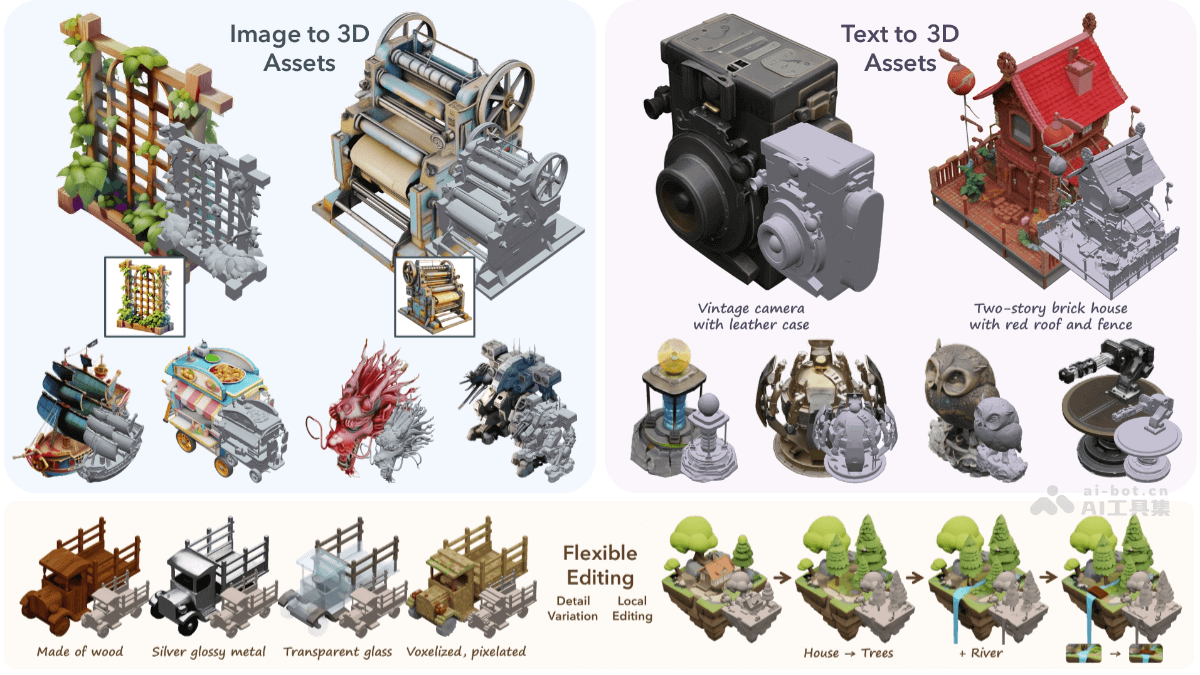
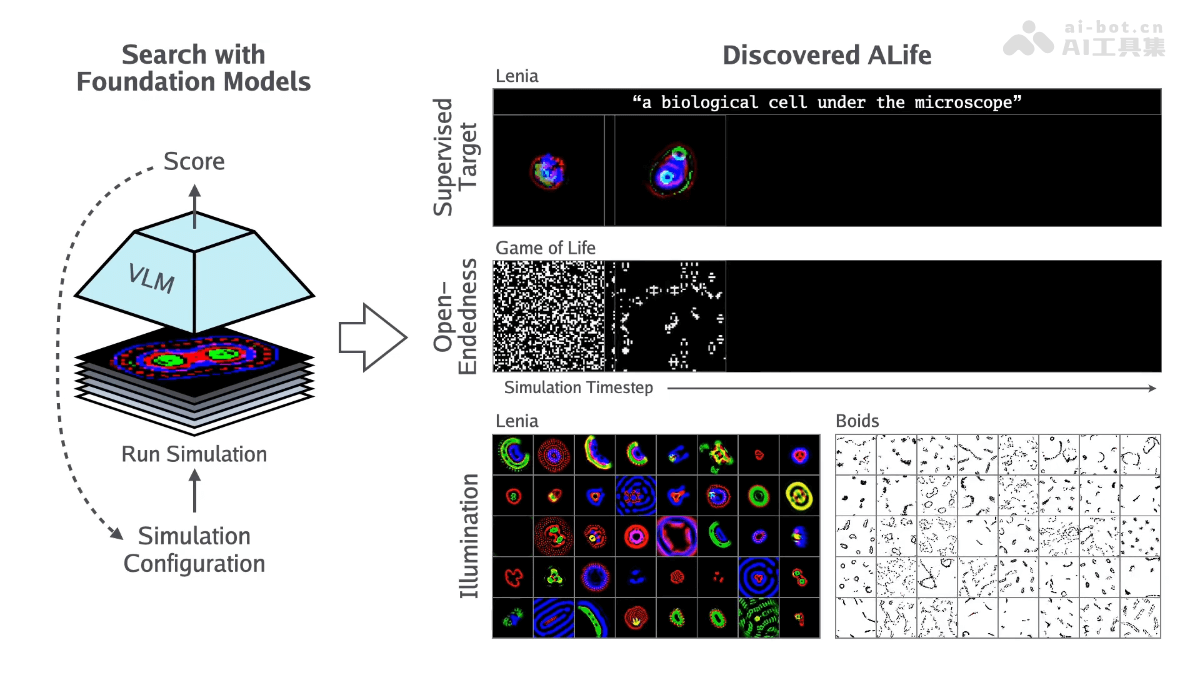
Sketch2Sound是Adobe 研究院和西北大学推出的AI音频生成技术,能基于声音模仿和文本提示生成高品质音效。Sketch2Sound从声音模仿中提取响度、亮度和音高三个控制信号,将控制信号编码后用于条件文本到声音的生成系统。Sketch2Sound轻量级,只需少量微调步骤和单层线性适配,即可在多种文本到音频模型上实现。Sketch2Sound为声音设计师提供结合文本提示的语义灵活性和声音模仿的精确性的工具,增强了声音创作的表达力和可控性。
 Sketch2Sound的主要功能声音模仿与文本提示结合: Sketch2Sound能理解声音模仿(如口头模仿)和文本提示,生成与两者相符的高品质音效。提取控制信号: 从任何输入的声音模仿中提取三个关键的控制信号:响度(loudness)、亮度(spectral centroid)和音高概率(pitch probabilities)。生成任意声音: 用提取的控制信号和文本提示,合成任意声音,包括模仿特定声音或创造新的声音效果。轻量级实现: 能在任何文本到音频潜在扩散变换器(DiT)上实现,只需40,000步的微调和每个控制信号一个单独的线性层。Sketch2Sound的技术原理控制信号提取: 用音频信号处理技术,从输入的声音模仿中提取响度、亮度和音高概率。潜在扩散模型: 基于预训练的文本到声音潜在扩散变换器(DiT),模型包含变分自编码器(VAE)和变换器解码器,将音频压缩成连续向量序列,然后生成新的潜在向量序列以合成音频。条件生成: 在潜在扩散模型中添加线性投影层,将控制信号直接添加到模型的噪声潜在变量中,实现对模型的条件化。微调与适配: 对预训练的文本到音频模型进行微调,使其能处理时间变化的控制信号,实现自监督微调。推理时控制: 在推理时,用户选择不同大小的中值滤波器调整控制信号的时间细节,从而在声音模仿的精确性和生成音频的质量之间进行权衡。语义灵活性与表达性: 结合文本提示的语义灵活性和声音模仿的表达性,为用户提供自然、直观的声音创作方法。Sketch2Sound的项目地址项目官网:hugofloresgarcia.art/sketch2soundarXiv技术论文:https://arxiv.org/pdf/2412.08550Sketch2Sound的应用场景电影和视频制作: 在电影和视频后期制作中,生成与画面同步的音效,如模拟特定环境的声音效果(如森林、城市、战场等)。游戏开发: 为电子游戏设计逼真的音效和环境音,增强游戏的沉浸感和互动性。音乐制作: 音乐制作人创作新的音乐元素或模拟特定乐器的声音。声音设计教育: 在声音设计的教学中,作为工具帮助学生理解声音的构成和操控声音的基本方法。互动媒体和装置艺术: 在互动艺术项目中,根据观众的行为或输入生成相应的声音反馈。
Sketch2Sound的主要功能声音模仿与文本提示结合: Sketch2Sound能理解声音模仿(如口头模仿)和文本提示,生成与两者相符的高品质音效。提取控制信号: 从任何输入的声音模仿中提取三个关键的控制信号:响度(loudness)、亮度(spectral centroid)和音高概率(pitch probabilities)。生成任意声音: 用提取的控制信号和文本提示,合成任意声音,包括模仿特定声音或创造新的声音效果。轻量级实现: 能在任何文本到音频潜在扩散变换器(DiT)上实现,只需40,000步的微调和每个控制信号一个单独的线性层。Sketch2Sound的技术原理控制信号提取: 用音频信号处理技术,从输入的声音模仿中提取响度、亮度和音高概率。潜在扩散模型: 基于预训练的文本到声音潜在扩散变换器(DiT),模型包含变分自编码器(VAE)和变换器解码器,将音频压缩成连续向量序列,然后生成新的潜在向量序列以合成音频。条件生成: 在潜在扩散模型中添加线性投影层,将控制信号直接添加到模型的噪声潜在变量中,实现对模型的条件化。微调与适配: 对预训练的文本到音频模型进行微调,使其能处理时间变化的控制信号,实现自监督微调。推理时控制: 在推理时,用户选择不同大小的中值滤波器调整控制信号的时间细节,从而在声音模仿的精确性和生成音频的质量之间进行权衡。语义灵活性与表达性: 结合文本提示的语义灵活性和声音模仿的表达性,为用户提供自然、直观的声音创作方法。Sketch2Sound的项目地址项目官网:hugofloresgarcia.art/sketch2soundarXiv技术论文:https://arxiv.org/pdf/2412.08550Sketch2Sound的应用场景电影和视频制作: 在电影和视频后期制作中,生成与画面同步的音效,如模拟特定环境的声音效果(如森林、城市、战场等)。游戏开发: 为电子游戏设计逼真的音效和环境音,增强游戏的沉浸感和互动性。音乐制作: 音乐制作人创作新的音乐元素或模拟特定乐器的声音。声音设计教育: 在声音设计的教学中,作为工具帮助学生理解声音的构成和操控声音的基本方法。互动媒体和装置艺术: 在互动艺术项目中,根据观众的行为或输入生成相应的声音反馈。