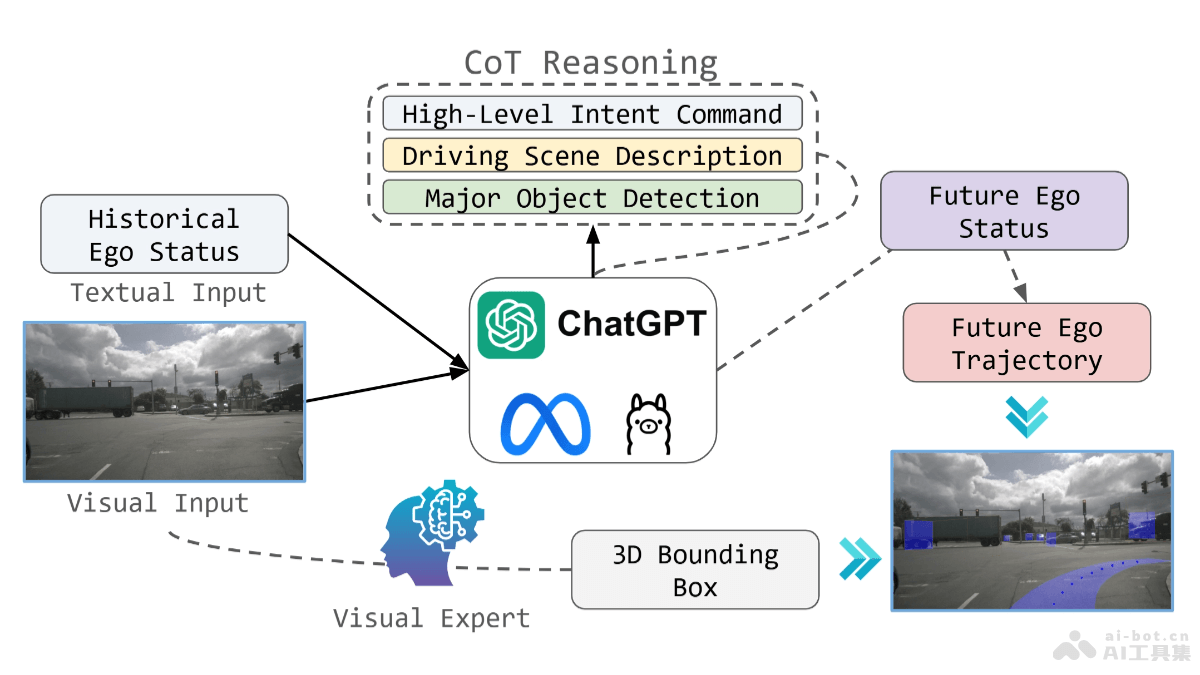
VideoVAE+(VideoVAE Plus)是香港科技大学团队推出的先进的跨模态视频变分自编码器(Video VAE),通过引入新的时空分离压缩机制和文本指导,实现了对大幅运动视频的高效压缩与精准重建,同时保持了良好的时间一致性和运动恢复。VideoVAE+在视频重建质量上全面超越了最新模型,包括英伟达的Cosmos Tokenizer等。模型支持高保真重建,跨模态重建,在视频重建任务中树立了新的基准。
 VideoVAE+的主要功能高保真重建:VideoVAE+能实现卓越的图像和视频重建质量,即使在大幅运动的视频场景中也能保持高清晰度和细节。跨模态重建:模型能够基于文本信息来指导视频的重建过程,提高了视频细节的保留能力和时间稳定性。VideoVAE+的技术原理时空分离的压缩机制:VideoVAE+提出了一种时序感知的空间压缩方法,有效分离空间和时间信息处理,避免因时空耦合而导致的运动伪影。轻量级运动压缩模型:专门设计了一个模型用于时序压缩,高效捕获视频中的运动动态。文本信息融合:利用文本到视频数据集中的文本信息作为指导,提高视频细节的保留能力和时间稳定性。图像和视频的联合训练:通过在图像和视频数据上的联合训练,增强了模型在多任务上的重建性能和适应性。智能特征分块:将视频的视觉特征图分割成小块(patch),并将它们作为token进行处理,不同层采用多种尺寸(8×8、4×4、2×2、1×1),确保每层特征的细节追踪到位。跨模态注意力机制:首次在Video VAE任务上引入文本信息作为语义指导,让视觉token(作为Query)与文本嵌入(作为Key和Value)计算跨模态注意力,提升细节重建质量。强大的文本嵌入器:采用先进的Flan-T5模型,将文字转化为语义向量,为视频生成提供坚实的语义基础。VideoVAE+的项目地址Github仓库:https://github.com/VideoVerses/VideoVAEPlusarXiv技术论文:https://arxiv.org/pdf/2412.17805VideoVAE+的应用场景视频压缩:VideoVAE+通过将视频映射到潜在空间,实现了高效的视频压缩,同时保持了视频的高质量。视频重建:VideoVAE+在视频重建方面表现出色,能精准重建原始视频信息,为生成高质量视频提供基础。在线教育:在在线教育领域,VideoVAE+的视频生成能力可以用于创建虚拟教师的教学视频,提升学生的学习兴趣和参与度。影视后期制作:VideoVAE+的潜在空间插值和注意力机制为特效制作带来了革命性的变化。可以通过潜在空间的插值操作,在两个不同的视频之间生成过渡视频,实现平滑的视频变换效果。视频流媒体:VideoVAE+的高效压缩和高质量重建能力为视频流媒体平台带来了更好的观看体验。使用VideoVAE+后,视频加载速度提升,卡顿率降低。
VideoVAE+的主要功能高保真重建:VideoVAE+能实现卓越的图像和视频重建质量,即使在大幅运动的视频场景中也能保持高清晰度和细节。跨模态重建:模型能够基于文本信息来指导视频的重建过程,提高了视频细节的保留能力和时间稳定性。VideoVAE+的技术原理时空分离的压缩机制:VideoVAE+提出了一种时序感知的空间压缩方法,有效分离空间和时间信息处理,避免因时空耦合而导致的运动伪影。轻量级运动压缩模型:专门设计了一个模型用于时序压缩,高效捕获视频中的运动动态。文本信息融合:利用文本到视频数据集中的文本信息作为指导,提高视频细节的保留能力和时间稳定性。图像和视频的联合训练:通过在图像和视频数据上的联合训练,增强了模型在多任务上的重建性能和适应性。智能特征分块:将视频的视觉特征图分割成小块(patch),并将它们作为token进行处理,不同层采用多种尺寸(8×8、4×4、2×2、1×1),确保每层特征的细节追踪到位。跨模态注意力机制:首次在Video VAE任务上引入文本信息作为语义指导,让视觉token(作为Query)与文本嵌入(作为Key和Value)计算跨模态注意力,提升细节重建质量。强大的文本嵌入器:采用先进的Flan-T5模型,将文字转化为语义向量,为视频生成提供坚实的语义基础。VideoVAE+的项目地址Github仓库:https://github.com/VideoVerses/VideoVAEPlusarXiv技术论文:https://arxiv.org/pdf/2412.17805VideoVAE+的应用场景视频压缩:VideoVAE+通过将视频映射到潜在空间,实现了高效的视频压缩,同时保持了视频的高质量。视频重建:VideoVAE+在视频重建方面表现出色,能精准重建原始视频信息,为生成高质量视频提供基础。在线教育:在在线教育领域,VideoVAE+的视频生成能力可以用于创建虚拟教师的教学视频,提升学生的学习兴趣和参与度。影视后期制作:VideoVAE+的潜在空间插值和注意力机制为特效制作带来了革命性的变化。可以通过潜在空间的插值操作,在两个不同的视频之间生成过渡视频,实现平滑的视频变换效果。视频流媒体:VideoVAE+的高效压缩和高质量重建能力为视频流媒体平台带来了更好的观看体验。使用VideoVAE+后,视频加载速度提升,卡顿率降低。