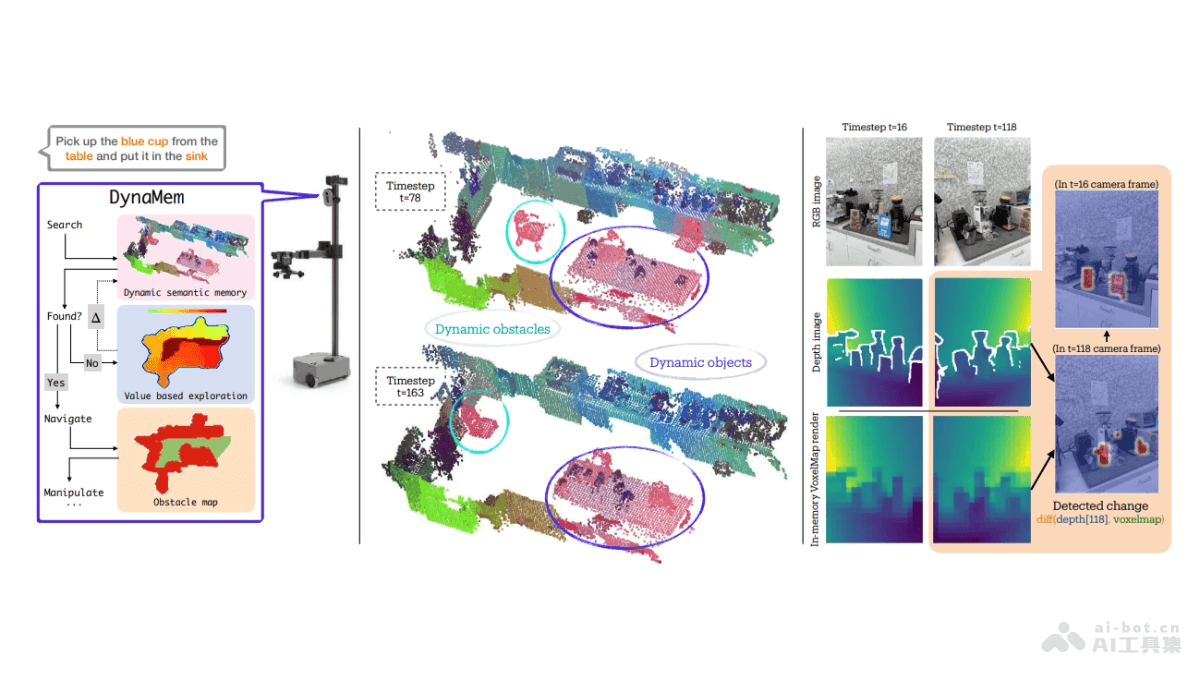
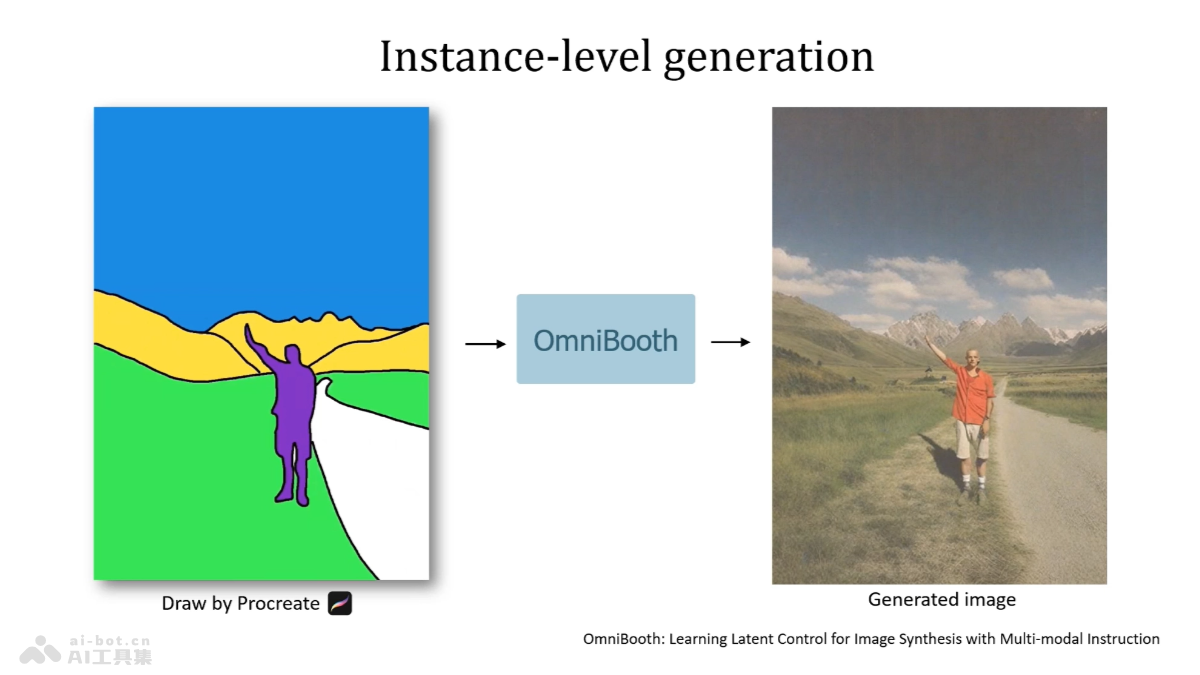
Draw an Audio 是中国科学院自动化研究所和美团点评的研究人员推出的视频生成音频系统。根据视频内容自动生成匹配的声音效果,类似于电影制作中的 Foley 艺术。系统分析视频结合多种输入指令,如文本、视频遮罩和响度信号,生成与视频内容、时间和响度一致的音频。核心架构包括潜在扩散模型(LDM)、文本条件模型、掩码注意力模块(MAM)和时间-响度模块(TLM),组件共同确保音频生成的高质量和准确性。为视频内容创作者提供了一个强大的工具,声音设计过程更加高效和灵活。
 Draw an Audio的主要功能内容一致性:系统分析视频内容,生成与视频场景语义相匹配的声音,如视频中出现动物时生成相应的动物叫声。时间一致性:生成的音频与视频中的动作精确同步,确保声音效果在正确的时间点出现,例如视频中的物体碰撞声音与碰撞动作同时发生。响度一致性:系统根据视频中的动作强度调整声音的响度,如视频中远处物体的声音相对较小,而近处物体的声音较大。多指令输入:系统支持多种输入指令,包括视频本身、相关文本描述、视频遮罩和响度信号,音频生成更加灵活和可控。高质量的同步音频:通过多指令的利用,Draw an Audio 能生成与视频内容自然同步的高质量音频,提升观看体验。Draw an Audio的技术原理潜在扩散模型(Latent Diffusion Model, LDM):作为基础模型,负责处理音频数据的基本生成和处理。文本条件模型:处理文本指令,确保生成的音频与文本描述相匹配,提高内容的语义一致性。掩码注意力模块(Masked-Attention Module, MAM):通过视频遮罩来关注视频的重点区域,增强视频内容与生成音频之间的一致性。时间-响度模块(Time-Loudness Module, TLM):处理信号指令,如响度信号,确保生成的声音在时间和响度上与视频同步。Draw an Audio的项目地址项目官网:yannqi.github.io/Draw-an-AudioarXiv技术论文:https://arxiv.org/pdf/2409.06135Draw an Audio的应用场景电影和视频制作:在影视后期制作中,Draw an Audio 自动为无声视频添加匹配的音效,如脚步声、车辆行驶声等,提高制作效率并减少成本。游戏开发:为游戏中的动画和场景生成逼真的声音效果,增强玩家的沉浸感和游戏体验。虚拟现实(VR)和增强现实(AR):在虚拟环境中生成与场景相匹配的声音,提升用户的交互体验和感知真实性。教育和培训:为教育视频自动生成解释性的声音,帮助学生更好地理解和吸收知识。动画制作:自动生成动画角色的对话和环境音效,使动画制作更加高效。广告制作:为广告视频生成吸引人的音频效果,增强广告的吸引力和记忆点。
Draw an Audio的主要功能内容一致性:系统分析视频内容,生成与视频场景语义相匹配的声音,如视频中出现动物时生成相应的动物叫声。时间一致性:生成的音频与视频中的动作精确同步,确保声音效果在正确的时间点出现,例如视频中的物体碰撞声音与碰撞动作同时发生。响度一致性:系统根据视频中的动作强度调整声音的响度,如视频中远处物体的声音相对较小,而近处物体的声音较大。多指令输入:系统支持多种输入指令,包括视频本身、相关文本描述、视频遮罩和响度信号,音频生成更加灵活和可控。高质量的同步音频:通过多指令的利用,Draw an Audio 能生成与视频内容自然同步的高质量音频,提升观看体验。Draw an Audio的技术原理潜在扩散模型(Latent Diffusion Model, LDM):作为基础模型,负责处理音频数据的基本生成和处理。文本条件模型:处理文本指令,确保生成的音频与文本描述相匹配,提高内容的语义一致性。掩码注意力模块(Masked-Attention Module, MAM):通过视频遮罩来关注视频的重点区域,增强视频内容与生成音频之间的一致性。时间-响度模块(Time-Loudness Module, TLM):处理信号指令,如响度信号,确保生成的声音在时间和响度上与视频同步。Draw an Audio的项目地址项目官网:yannqi.github.io/Draw-an-AudioarXiv技术论文:https://arxiv.org/pdf/2409.06135Draw an Audio的应用场景电影和视频制作:在影视后期制作中,Draw an Audio 自动为无声视频添加匹配的音效,如脚步声、车辆行驶声等,提高制作效率并减少成本。游戏开发:为游戏中的动画和场景生成逼真的声音效果,增强玩家的沉浸感和游戏体验。虚拟现实(VR)和增强现实(AR):在虚拟环境中生成与场景相匹配的声音,提升用户的交互体验和感知真实性。教育和培训:为教育视频自动生成解释性的声音,帮助学生更好地理解和吸收知识。动画制作:自动生成动画角色的对话和环境音效,使动画制作更加高效。广告制作:为广告视频生成吸引人的音频效果,增强广告的吸引力和记忆点。