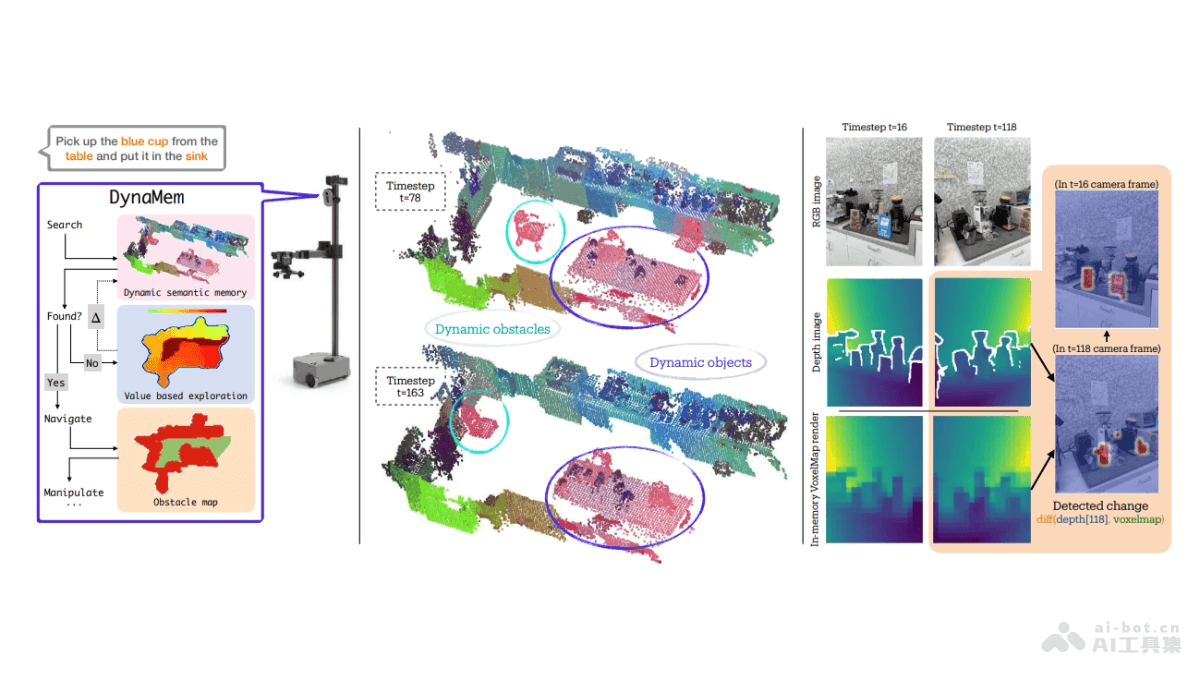
书生·物华2.0(3DTopia 2.0)是由上海人工智能实验室与南洋理工大学联合开发的三维物体生成大模型。模型采用创新的原语(primitive-based)三维表示方法PrimX,能将形状、纹理和材质信息编码为紧凑的张量格式,实现高分辨率几何图形的建模。3DTopia 2.0基于Diffusion Transformer框架,支持从文本或图像输入高效生成具有物理基础渲染(PBR)特性的高质量三维资产。模型代码已开源,提供免费商用授权,有潜力革新游戏、影视、建筑和设计等行业的三维内容创作流程。
- 上海AI实验室联合南洋理工推出三维物体生成大模型 第1张") 书生·物华2.0的主要功能多模态输入生成三维物体:能根据文本描述或图像输入,快速生成对应的三维模型。高效率的生成过程:模型能在五秒内完成从输入到三维模型的转换,大幅提高创作效率。高质量和精细纹理:生成的三维物体具有平滑的几何形状和空间变化的纹理和材质,接近真实物理材质感。直接应用于游戏引擎和设计软件:生成的三维模型可以直接用于游戏引擎和工业设计软件,无需额外处理。支持高分辨率几何图形:基于PrimX表示法,能建模高分辨率的三维几何图形。书生·物华2.0的技术原理PrimX表示法:一种新颖的基于原语的三维表示方法,将三维物体的形状、反照率(albedo)、材质信息编码到一个紧凑的张量格式中。每个原语都是一个小体素,通过其三维位置、全局缩放因子和对应的空间变化的有效载荷(包括SDF、RGB和材质信息)来参数化。原始补丁压缩:使用三维变分自编码器(VAE)对每个原语的空间信息进行压缩,得到潜在的原语标记。过程采用了3D卷积层,将原语的有效载荷从高维空间压缩到低维潜在空间,为后续的生成模型提供了高效的输入。潜在原语扩散(Latent Primitive Diffusion):基于Diffusion Transformer(DiT)框架,模型学习了如何从随机噪声中逐步去除噪声,生成符合输入条件的潜在原语标记。过程模拟了物理过程中的扩散和去噪,能生成具有高分辨率几何图形和PBR材质的三维物体。可微分渲染:PrimX表示法支持可微分渲染,模型可以直接从二维图像数据中学习,提高了模型从现有图像资源中学习的能力。书生·物华2.0的项目地址Github仓库:https://github.com/3DTopia/3DTopia-XLarXiv技术论文:https://arxiv.org/pdf/2409.12957书生·物华2.0的应用场景游戏开发:在游戏设计中,可以快速生成各种三维游戏资产,如角色、道具、环境元素等,提高游戏开发的效率和丰富性。电影和动画制作:用于创建电影或动画中的三维场景和角色模型,减少手工建模的时间和成本,同时提供更多的创意自由度。虚拟现实(VR)和增强现实(AR):为虚拟现实和增强现实应用生成逼真的三维环境和对象,提升用户体验。建筑和城市规划:在建筑设计和城市规划中,快速生成三维建筑模型和城市景观,帮助设计师和规划师进行方案推敲和效果展示。
书生·物华2.0的主要功能多模态输入生成三维物体:能根据文本描述或图像输入,快速生成对应的三维模型。高效率的生成过程:模型能在五秒内完成从输入到三维模型的转换,大幅提高创作效率。高质量和精细纹理:生成的三维物体具有平滑的几何形状和空间变化的纹理和材质,接近真实物理材质感。直接应用于游戏引擎和设计软件:生成的三维模型可以直接用于游戏引擎和工业设计软件,无需额外处理。支持高分辨率几何图形:基于PrimX表示法,能建模高分辨率的三维几何图形。书生·物华2.0的技术原理PrimX表示法:一种新颖的基于原语的三维表示方法,将三维物体的形状、反照率(albedo)、材质信息编码到一个紧凑的张量格式中。每个原语都是一个小体素,通过其三维位置、全局缩放因子和对应的空间变化的有效载荷(包括SDF、RGB和材质信息)来参数化。原始补丁压缩:使用三维变分自编码器(VAE)对每个原语的空间信息进行压缩,得到潜在的原语标记。过程采用了3D卷积层,将原语的有效载荷从高维空间压缩到低维潜在空间,为后续的生成模型提供了高效的输入。潜在原语扩散(Latent Primitive Diffusion):基于Diffusion Transformer(DiT)框架,模型学习了如何从随机噪声中逐步去除噪声,生成符合输入条件的潜在原语标记。过程模拟了物理过程中的扩散和去噪,能生成具有高分辨率几何图形和PBR材质的三维物体。可微分渲染:PrimX表示法支持可微分渲染,模型可以直接从二维图像数据中学习,提高了模型从现有图像资源中学习的能力。书生·物华2.0的项目地址Github仓库:https://github.com/3DTopia/3DTopia-XLarXiv技术论文:https://arxiv.org/pdf/2409.12957书生·物华2.0的应用场景游戏开发:在游戏设计中,可以快速生成各种三维游戏资产,如角色、道具、环境元素等,提高游戏开发的效率和丰富性。电影和动画制作:用于创建电影或动画中的三维场景和角色模型,减少手工建模的时间和成本,同时提供更多的创意自由度。虚拟现实(VR)和增强现实(AR):为虚拟现实和增强现实应用生成逼真的三维环境和对象,提升用户体验。建筑和城市规划:在建筑设计和城市规划中,快速生成三维建筑模型和城市景观,帮助设计师和规划师进行方案推敲和效果展示。