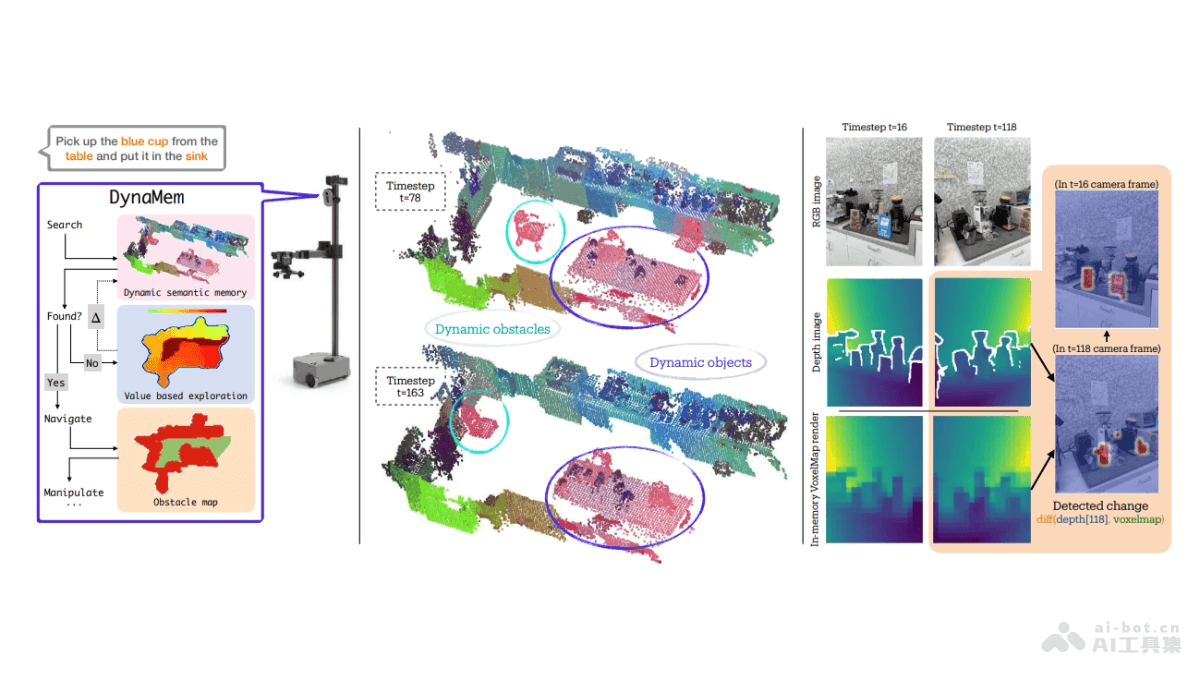
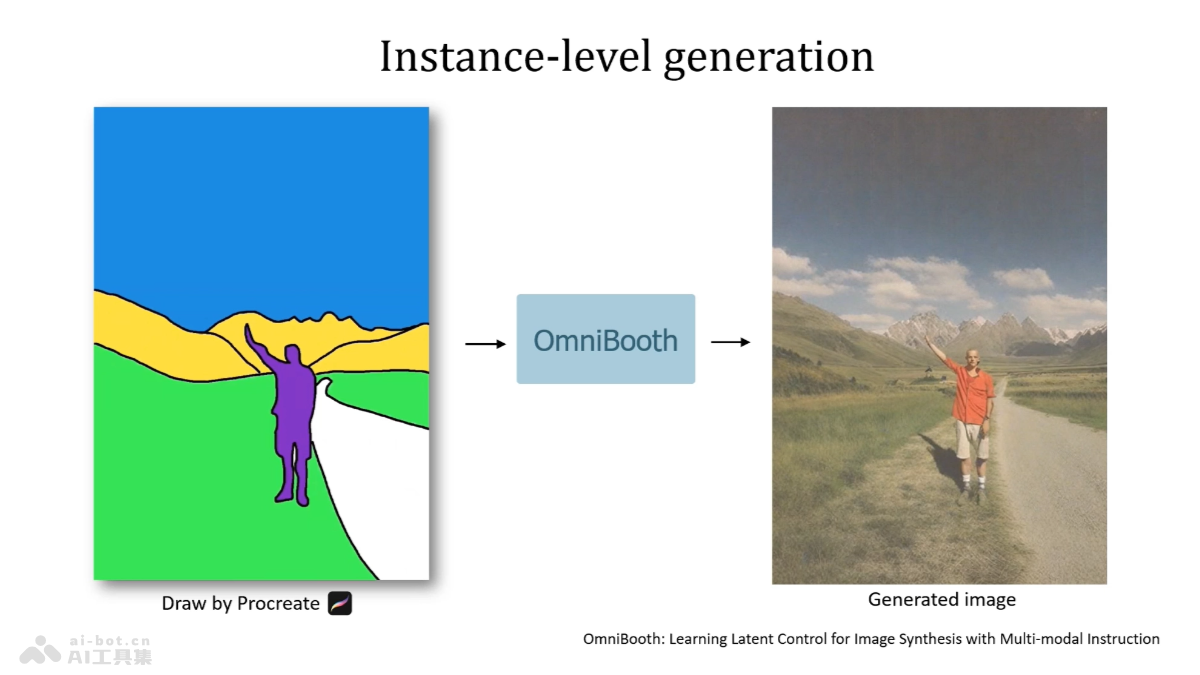
GLM-4-Voice是智谱AI推出的端到端情感语音模型,能直接理解和生成中英文语音,支持实时语音对话,能根据用户指令灵活调整语音的情感、语调、语速和方言等特征。模型由三个部分组成:GLM-4-Voice-Tokenizer负责将连续语音转换为离散token,GLM-4-Voice-Decoder将token转换回连续语音输出,GLM-4-Voice-9B基于GLM-4-9B模型进行预训练和对齐,理解和生成语音。GLM-4-Voice的设计用端到端建模减少信息损失,提高语音交互的自然度和流畅性,且支持低延迟的实时对话,为用户提供更加丰富和自然的语音交互体验。
 GLM-4-Voice的主要功能理解和生成语音:直接理解和生成中英文语音,实现流畅的人机交互。情感表达:模拟不同的情感和语调,如高兴、悲伤、生气、害怕等,让语音回复更加自然。调节语速:根据用户的指令调整语音的语速,适于不同的对话场景。实时打断和指令输入:支持用户随时打断语音输出,输入新的指令调整对话内容。多语言和方言支持:支持中英文及多种中国方言,如粤语、重庆话、北京话等。低延迟交互:设计流式思考架构,低延迟实现高质量的语音对话。GLM-4-Voice的技术原理端到端建模:与传统的级联方案(ASR + LLM + TTS)不同,GLM-4-Voice在一个统一的模型中完成语音的理解和生成,避免信息损失。音频Tokenizer:用有监督训练的音频Tokenizer将连续的语音输入转化为离散的token,用12.5Hz的低码率保留语义信息和副语言特征。语音解码器:基于Flow Matching模型结构的语音解码器,将离散的语音token转化为连续的语音输出,最低只需10个token开始生成,降低对话延迟。预训练和对齐:GLM-4-Voice-9B在GLM-4-9B的基础上进行预训练和对齐,理解和生成离散化的语音token。预训练用大量音频和文本数据,让模型具备强大的音频理解和建模能力。流式推理:支持流式推理,模型能交替输出文本和语音,用文本作为参照保证回复内容的高质量,根据用户的语音指令实时调整语音输出。GLM-4-Voice的项目地址产品体验:https://ai-bot.cn/sites/2005.html项目官网:zhipuai.cn/newsGitHub仓库:https://github.com/THUDM/GLM-4-VoiceGLM-4-Voice的应用场景智能助手:在智能手机、智能家居设备中,作为智能助手,用语音交互帮助用户完成各种任务,如设置提醒、查询天气、控制家居设备等。客户服务:在客户服务中心,作为虚拟客服,基于自然语言理解和语音合成技术,为用户提供咨询和解决问题的服务。教育和学习:在教育领域,作为语言学习助手,帮助学生练习发音、听力和口语,提供个性化的学习建议。娱乐和媒体:在娱乐行业,用在语音合成,为动画、游戏、有声书等提供自然、富有表现力的语音输出。新闻和播报:用在新闻播报,将文本新闻快速转换为语音,提供给需要语音信息的用户。
GLM-4-Voice的主要功能理解和生成语音:直接理解和生成中英文语音,实现流畅的人机交互。情感表达:模拟不同的情感和语调,如高兴、悲伤、生气、害怕等,让语音回复更加自然。调节语速:根据用户的指令调整语音的语速,适于不同的对话场景。实时打断和指令输入:支持用户随时打断语音输出,输入新的指令调整对话内容。多语言和方言支持:支持中英文及多种中国方言,如粤语、重庆话、北京话等。低延迟交互:设计流式思考架构,低延迟实现高质量的语音对话。GLM-4-Voice的技术原理端到端建模:与传统的级联方案(ASR + LLM + TTS)不同,GLM-4-Voice在一个统一的模型中完成语音的理解和生成,避免信息损失。音频Tokenizer:用有监督训练的音频Tokenizer将连续的语音输入转化为离散的token,用12.5Hz的低码率保留语义信息和副语言特征。语音解码器:基于Flow Matching模型结构的语音解码器,将离散的语音token转化为连续的语音输出,最低只需10个token开始生成,降低对话延迟。预训练和对齐:GLM-4-Voice-9B在GLM-4-9B的基础上进行预训练和对齐,理解和生成离散化的语音token。预训练用大量音频和文本数据,让模型具备强大的音频理解和建模能力。流式推理:支持流式推理,模型能交替输出文本和语音,用文本作为参照保证回复内容的高质量,根据用户的语音指令实时调整语音输出。GLM-4-Voice的项目地址产品体验:https://ai-bot.cn/sites/2005.html项目官网:zhipuai.cn/newsGitHub仓库:https://github.com/THUDM/GLM-4-VoiceGLM-4-Voice的应用场景智能助手:在智能手机、智能家居设备中,作为智能助手,用语音交互帮助用户完成各种任务,如设置提醒、查询天气、控制家居设备等。客户服务:在客户服务中心,作为虚拟客服,基于自然语言理解和语音合成技术,为用户提供咨询和解决问题的服务。教育和学习:在教育领域,作为语言学习助手,帮助学生练习发音、听力和口语,提供个性化的学习建议。娱乐和媒体:在娱乐行业,用在语音合成,为动画、游戏、有声书等提供自然、富有表现力的语音输出。新闻和播报:用在新闻播报,将文本新闻快速转换为语音,提供给需要语音信息的用户。