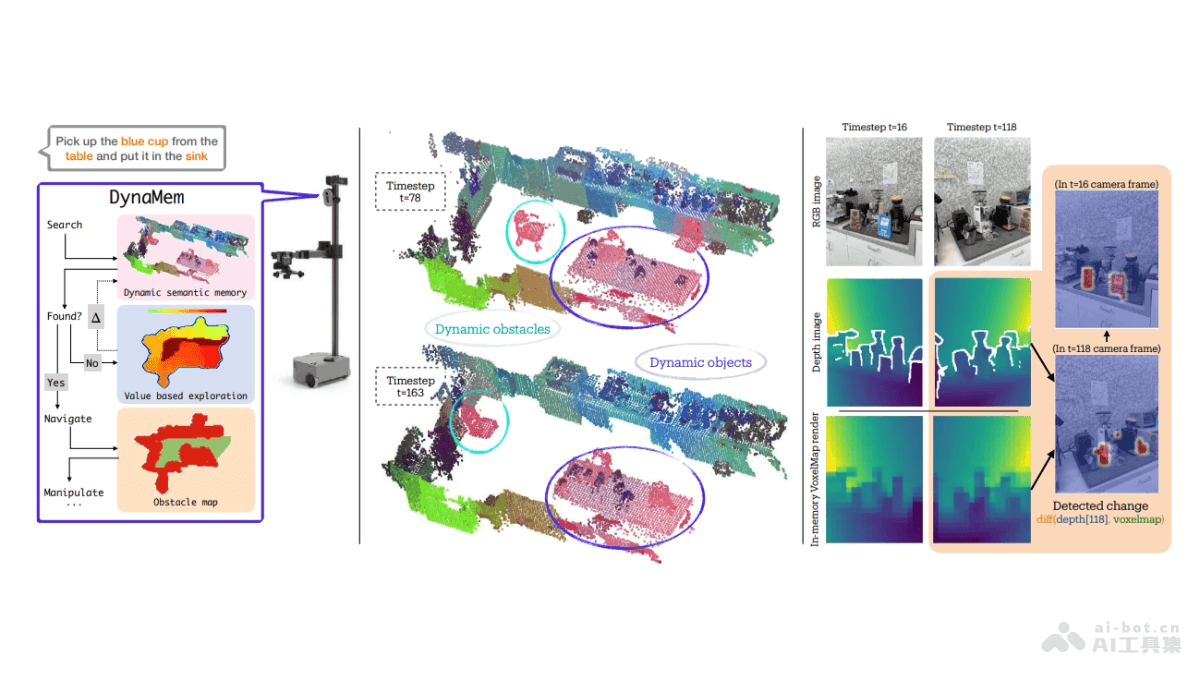
ProX(Programming Every Example)是一个旨在提高大型语言模型预训练数据质量的框架。与传统依赖人类专家制定规则的方法不同,ProX将数据清洗任务视为编程问题,支持模型自动执行如字符串标准化和噪声行移除等细粒度操作。小型模型(如0.3B参数)也能展现出与人类专家相当的数据处理能力。实验结果表明,ProX处理后的数据用于模型预训练,在各种下游任务中取得超过2%的性能提升。ProX的另一个显著优势是在不同模型大小和预训练语料库上的广泛适用性,包括在特定领域(如数学)的持续预训练中,无需特定领域设计即可显著提升模型性能。ProX节省训练FLOPs,为高效预训练大型语言模型提供有前景的路径。
 ProX的主要功能数据精炼: ProX基于生成和执行程序精炼大规模数据集,提高数据质量,用在大型语言模型的预训练。自动化处理: 自动化地对每个数据样本进行细粒度的清洗和改进,无需人工专家干预。性能提升: ProX处理过的数据进行预训练的模型,在多个下游任务中表现出超过2%的性能提升。领域灵活性: 适用于不同领域,包括数学等,在不需要特定领域设计的情况下提升准确性。资源节省: 相比于基于大型语言模型的数据合成方法,ProX在保持结果的同时,显著减少计算资源的需求。ProX的技术原理模型适应性: ProX首先在种子数据上微调小型基础语言模型适应数据精炼任务。程序生成: 适应后的模型为预训练语料库中的每个样本生成数据处理程序,程序包括过滤、字符串标准化和去除噪声行等操作。程序执行: 生成的程序由预定义的执行器执行,产生准备好预训练的精炼语料库。两阶段精炼: ProX包括文档级编程和块级编程两个阶段,分别进行粗粒度和细粒度的数据精炼。功能调用: ProX基于灵活的功能调用增强数据质量,统一为特定的转换或清洗过程。计算效率: ProX展示在较少的预训练计算FLOPs下,如何通过投资额外的计算资源精炼预训练语料库,从而实现更高效的预训练。ProX项目地址项目官网:gair-nlp.github.io/ProXGitHub仓库:https://github.com/GAIR-NLP/ProXHuggingFace模型库:https://huggingface.co/gair-proxarXiv技术论文:https://arxiv.org/pdf/2409.17115ProX的应用场景大型语言模型预训练:ProX能提升大量高质量文本数据进行预训练的大型语言模型的数据集质量。数据清洗和预处理:在数据挖掘、自然语言处理和其他机器学习任务中,ProX自动执行数据清洗和预处理步骤,减少人工干预。领域适应性训练:对于特定领域的应用,如医疗、法律或金融,ProX能优化数据集更好地适应专业术语和语境。持续学习:在持续学习或增量学习的场景中,ProX帮助模型通过不断精炼数据适应新信息和变化。数据合成:ProX能生成高质量的合成数据,增强现有的数据集,特别是在数据稀缺的领域。
ProX的主要功能数据精炼: ProX基于生成和执行程序精炼大规模数据集,提高数据质量,用在大型语言模型的预训练。自动化处理: 自动化地对每个数据样本进行细粒度的清洗和改进,无需人工专家干预。性能提升: ProX处理过的数据进行预训练的模型,在多个下游任务中表现出超过2%的性能提升。领域灵活性: 适用于不同领域,包括数学等,在不需要特定领域设计的情况下提升准确性。资源节省: 相比于基于大型语言模型的数据合成方法,ProX在保持结果的同时,显著减少计算资源的需求。ProX的技术原理模型适应性: ProX首先在种子数据上微调小型基础语言模型适应数据精炼任务。程序生成: 适应后的模型为预训练语料库中的每个样本生成数据处理程序,程序包括过滤、字符串标准化和去除噪声行等操作。程序执行: 生成的程序由预定义的执行器执行,产生准备好预训练的精炼语料库。两阶段精炼: ProX包括文档级编程和块级编程两个阶段,分别进行粗粒度和细粒度的数据精炼。功能调用: ProX基于灵活的功能调用增强数据质量,统一为特定的转换或清洗过程。计算效率: ProX展示在较少的预训练计算FLOPs下,如何通过投资额外的计算资源精炼预训练语料库,从而实现更高效的预训练。ProX项目地址项目官网:gair-nlp.github.io/ProXGitHub仓库:https://github.com/GAIR-NLP/ProXHuggingFace模型库:https://huggingface.co/gair-proxarXiv技术论文:https://arxiv.org/pdf/2409.17115ProX的应用场景大型语言模型预训练:ProX能提升大量高质量文本数据进行预训练的大型语言模型的数据集质量。数据清洗和预处理:在数据挖掘、自然语言处理和其他机器学习任务中,ProX自动执行数据清洗和预处理步骤,减少人工干预。领域适应性训练:对于特定领域的应用,如医疗、法律或金融,ProX能优化数据集更好地适应专业术语和语境。持续学习:在持续学习或增量学习的场景中,ProX帮助模型通过不断精炼数据适应新信息和变化。数据合成:ProX能生成高质量的合成数据,增强现有的数据集,特别是在数据稀缺的领域。