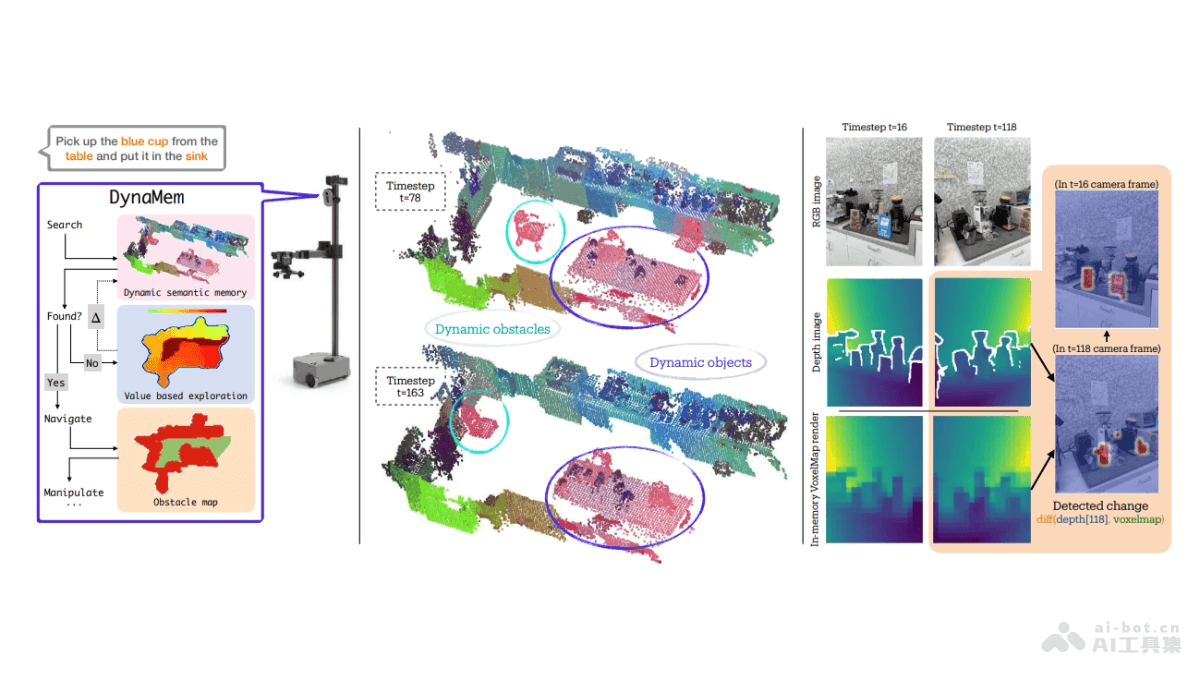
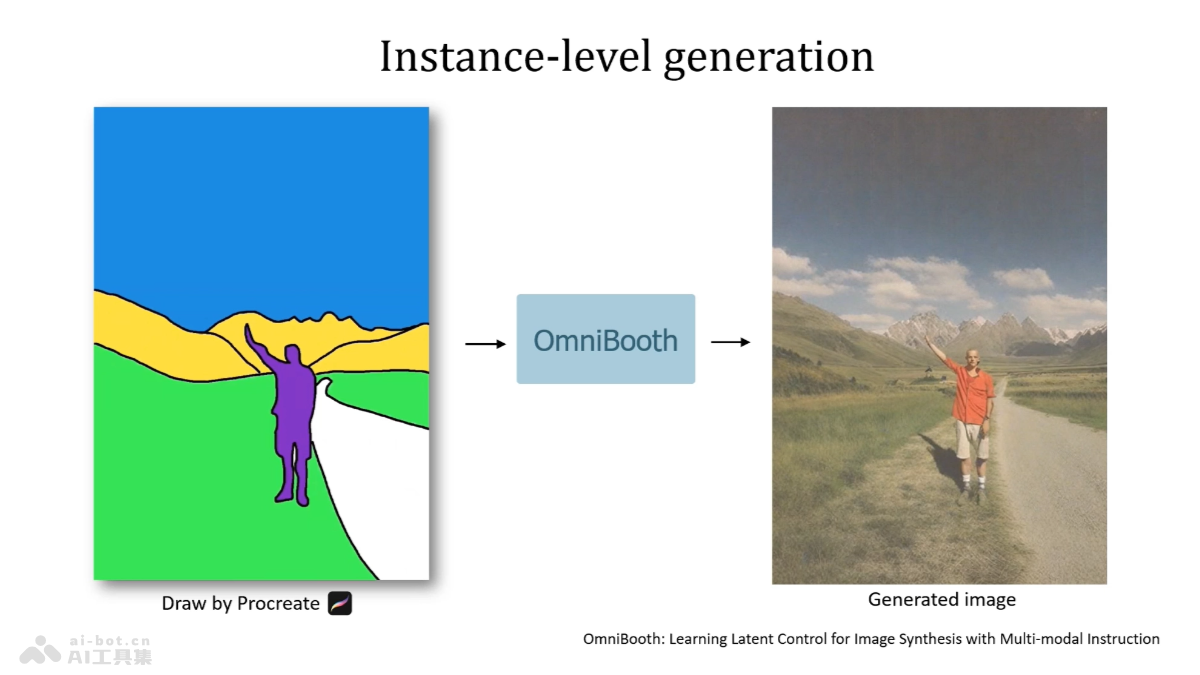
Crawl4AI是一款用 Python 开发的异步爬虫框架,专为大型语言模型(LLMs)和人工智能(AI)应用设计,简化网络爬虫和数据提取流程。基于异步架构,高效地处理多个网页,快速抓取所需数据。Crawl4AI支持多种输出格式,包括JSON、HTML、Markdown,满足不同场景的数据需求。Crawl4AI提取网页中的媒体文件、链接和元数据,提供强大的自定义功能,包括用户代理设置、自定义钩子、JavaScript执行等。Crawl4AI支持CSS选择器和多种分块策略,如基于主题、正则表达式、句子分割等,以及高级提取策略,如余弦聚类、LLM等,提高数据提取的准确性和效率。
 Crawl4AI的主要功能异步爬虫:支持异步操作,同时处理多个网页请求,提高爬虫效率。数据提取:提取网页的文本内容、图片、视频、音频等多媒体数据。多格式支持:提供JSON、HTML、Markdown等多种数据格式输出。链接抓取:自动提取网页中的内外链,方便进一步的数据探索。元数据提取:获取网页的元数据,如标题、描述、关键词等。自定义钩子:支持用户在爬虫运行前进行身份验证、设置请求头、修改页面等。Crawl4AI的技术原理异步编程:基于Python的
Crawl4AI的主要功能异步爬虫:支持异步操作,同时处理多个网页请求,提高爬虫效率。数据提取:提取网页的文本内容、图片、视频、音频等多媒体数据。多格式支持:提供JSON、HTML、Markdown等多种数据格式输出。链接抓取:自动提取网页中的内外链,方便进一步的数据探索。元数据提取:获取网页的元数据,如标题、描述、关键词等。自定义钩子:支持用户在爬虫运行前进行身份验证、设置请求头、修改页面等。Crawl4AI的技术原理异步编程:基于Python的asyncio库实现异步网络请求,提高爬虫的并发性能。请求处理:基于aiohttp等异步HTTP客户端库发送请求,获取网页数据。内容解析:基于BeautifulSoup、lxml等库解析HTML/XML内容,提取所需数据。正则表达式:用正则表达式匹配特定模式的字符串,用在数据提取和验证。JavaScript引擎:集成JavaScript引擎,如Selenium或Pyppeteer,执行网页中的JavaScript代码。Crawl4AI的项目地址项目官网:crawl4ai.com/mkdocsGitHub仓库:https://github.com/unclecode/crawl4aiCrawl4AI的应用场景市场研究:爬取竞争对手的网页,收集产品信息、价格、用户评价等数据,进行市场分析。客户洞察:从社交媒体和论坛中提取客户反馈和讨论,帮助企业了解客户需求和市场趋势。内容聚合:为新闻网站、博客聚合平台等抓取和整合内容。数据科学和分析:收集大量数据用于机器学习、数据挖掘和统计分析。学术研究:研究人员基于Crawl4AI爬取学术论文、统计数据、政策文件等,支持学术研究。产品监控:监控产品在不同网站上的价格和库存情况,进行价格比较和库存管理。