
Genesis是卡内基梅隆大学、马里兰大学、斯坦福大学、麻省理工学院等研究机构联合推出的开源生成式物理引擎,能模拟世界万物。Genesis能用简单的语言描述,快速生成精确的物理模拟,包括物体运动、人物动作和机器人策略等。...
网站首页 > AI工具 第6页
-

-

X-AnyLabeling是集成多种深度学习算法的图像标注软件,专注于提升标注效率和精度。X-AnyLabeling支持图像和视频的多样化标注样式,适配多种AI训练场景,提供图像级与对象级标签分类。软件支持主流深度学习框架的...
-

Explorer是Odyssey公司推出的生成性世界模型,能将任何图像转化为详细的3D世界。Explorer模型擅长生成真实感世界,且支持动态效果的生成。Explorer基于高斯溅射技术来重建场景,提供几乎无法察觉的真实细节...
-

UniReal是什么 UniReal是香港大学和Adobe研究院共同推出的框架,专注于实现多种图像生成和编辑任务。框架基于模拟现实世界动态,能在单一模型中处理包括图像生成、编辑、定制和合成在内的广泛任务。UniReal将不同...
-

WeaveFox是蚂蚁团队推出的AI驱动前端智能研发平台,基于蚂蚁自研的百灵多模态大模型,能直接根据设计图生成前端源代码。工具支持多种应用类型,包括控制台、移动端H5、小程序等,且兼容多种技术栈,如React、Vue等。...
-

EMMA-X是新加坡科技设计大学推出的具有70亿参数的具身多模态动作模型,在有根据的链式思维(CoT)推理数据上微调OpenVLA创建。EMMA-X结合层次化的具身数据集,包含3D空间运动、2D夹爪位置和有根据的推理,及推出...
-
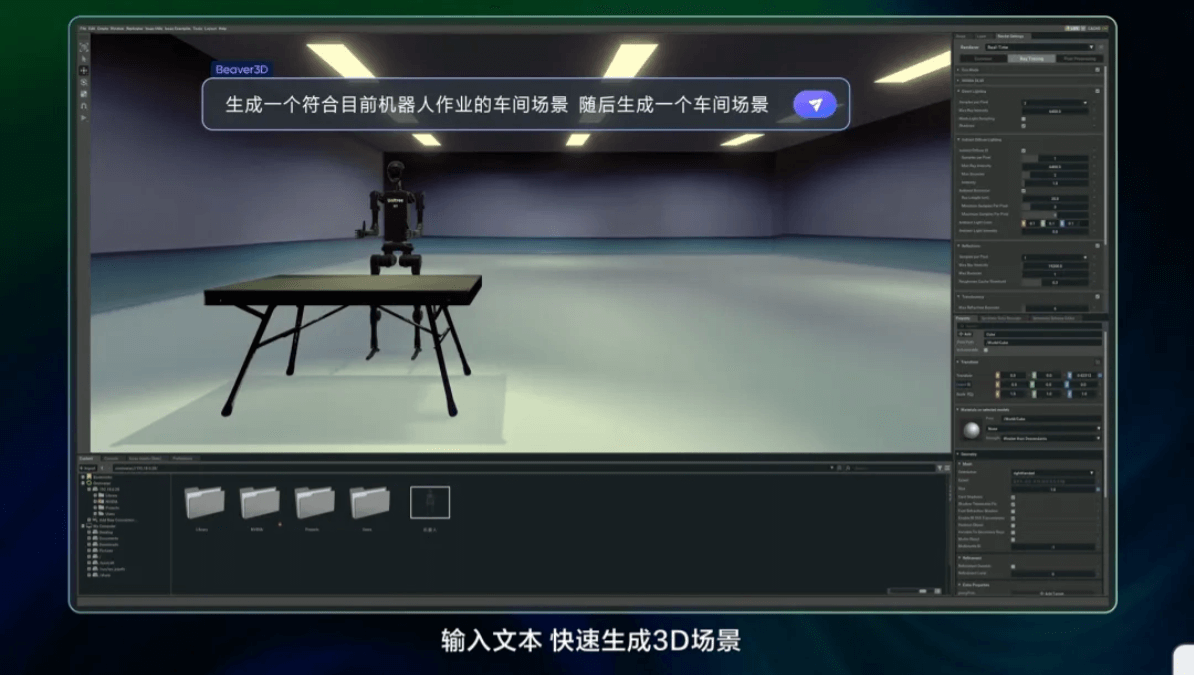
豆包3D生成模型是豆包推出的3D生成模型,属于豆包大模型家族。模型基于3D-DiT 架构,能生成高质量 3D 模块。与火山引擎数字孪生平台 veOmniverse 结合使用,能高效完成智能训练、数据合成和数字资产制作,成为一...
-

MV-Adapter是多视图一致图像生成模型,是北京航空航天大学、VAST和上海交通大学的研究团队推出的。MV-Adapter能将预训练的文本到图像扩散模型转化为多视图图像生成器,无需改变原始网络结构或特征空间。...
-

豆包视觉理解模型是豆包推出的先进AI大模型,具备视觉识别和理解推理能力。豆包视觉理解模型能识别图像中物体的类别、形状、纹理等,还能理解物体间的关系和场景含义,进行复杂的逻辑计算任务,如解析学术论文图表、诊断代码问题等。...
-

FACTS Grounding是谷歌DeepMind推出的评估大型语言模型(LLMs)能力的基准测试,衡量模型根据给定上下文生成事实准确且无捏造信息的文本的能力。FACTS Grounding测试集包含1719个跨多个领域的...
