
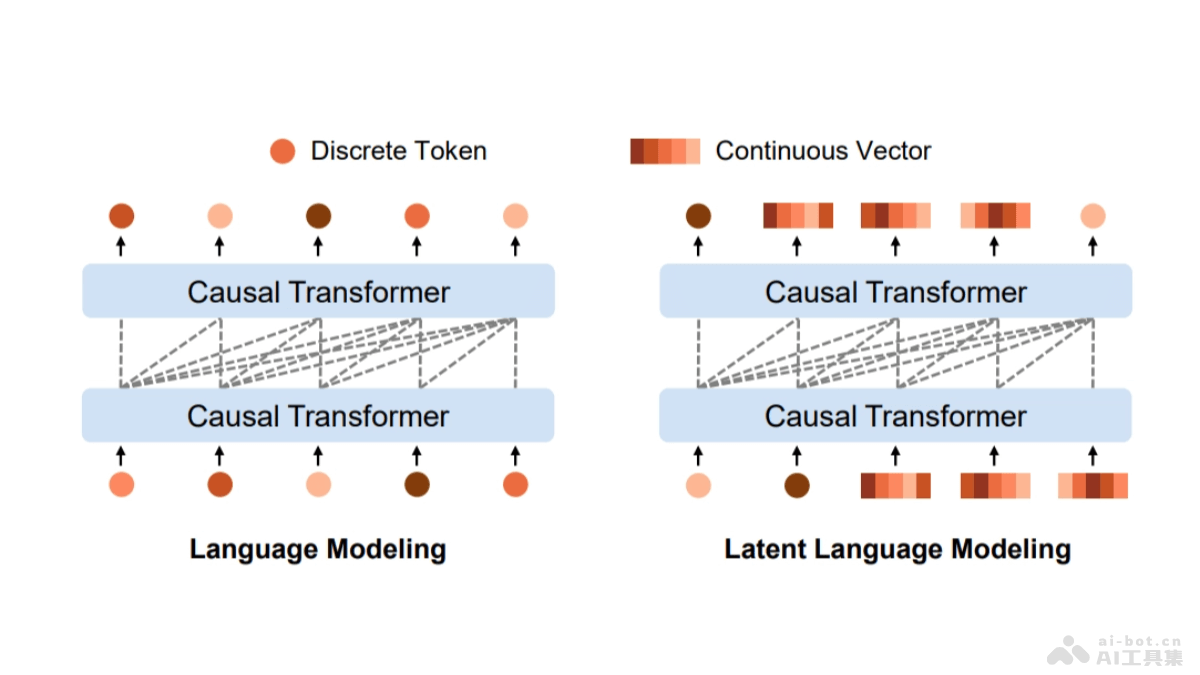
LatentLM是微软研究院和清华大学共同推出的多模态生成模型,能统一处理离散数据(如文本)和连续数据(如图像、音频)。模型用变分自编码器(VAE)将连续数据编码为潜在向量,引入下一个词扩散技术自回归生成向量。...
网站首页 > AI工具 第8页
-
-

BrushEdit是腾讯和北京大学等机构联合推出的先进图像编辑框架,是BrushNet模型的高级迭代版本。框架结合多模态大型语言模型(MLLMs)和双分支图像修复模型,实现基于指令引导的图像编辑和修复,支持用户用自然语言指令...
-

Apollo是Meta和斯坦福大学合作推出的大型多模态模型(LMMs),专注于视频理解。Apollo基于系统研究,揭示视频理解在LMMs中的关键驱动因素,推出“Scaling Consistency”现象,即在较小模型上的设...
-
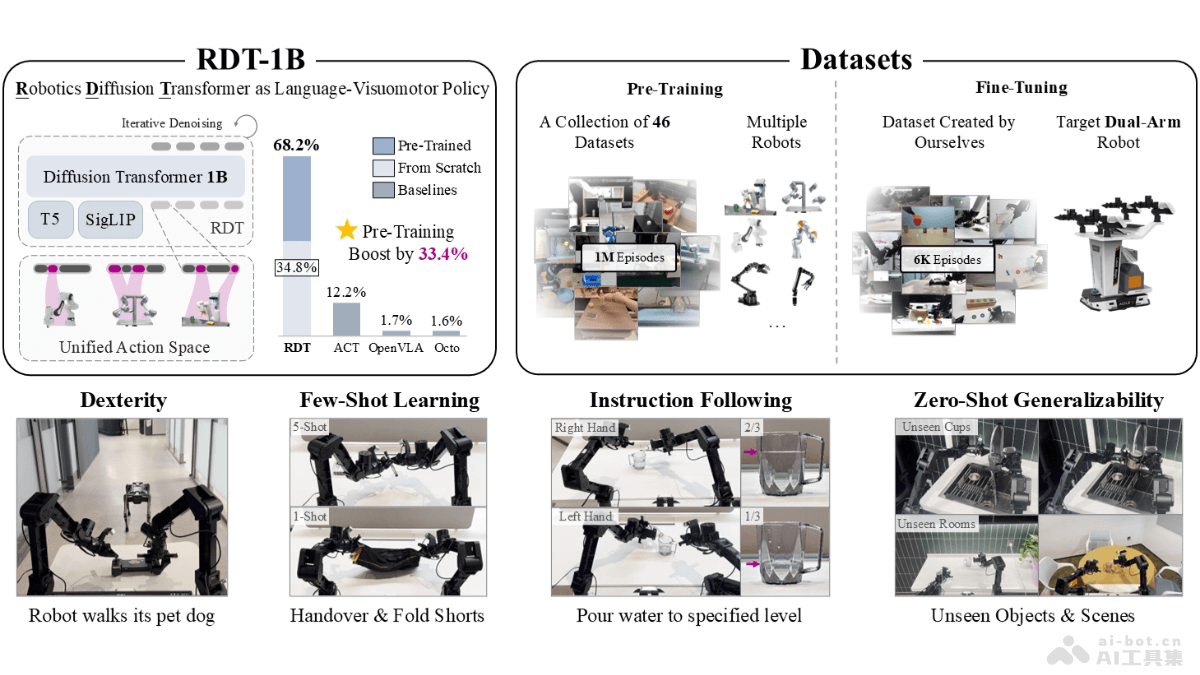
RDT(Robotics Diffusion Transformer)是清华大学AI研究院TSAIL团队推出的全球最大的双臂机器人操作任务扩散基础模型。RDT具备十亿参数量,能在无需人类操控的情况下,自主完成复杂任务,如调酒...
-
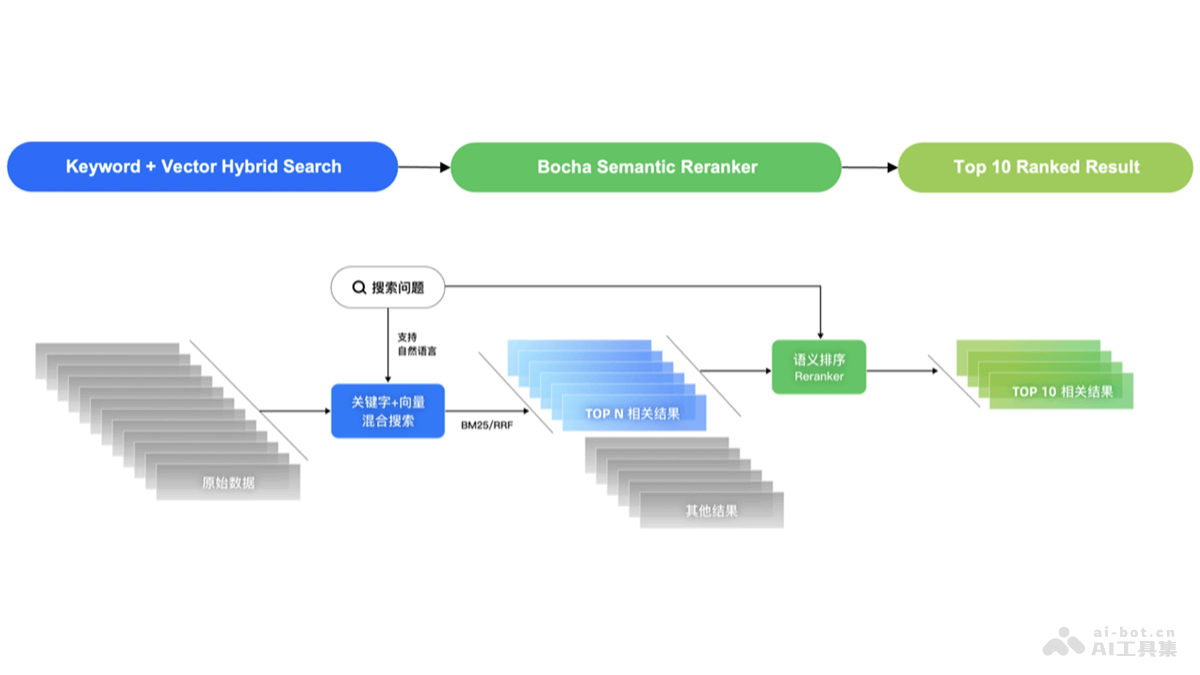
Bocha Semantic Reranker是博查AI推出的语义排序模型,能提升搜索应用和RAG应用中的搜索结果准确性。Bocha Semantic Reranker模型基于文本语义,对初步排序的搜索结果进行二次优化,用评...
-
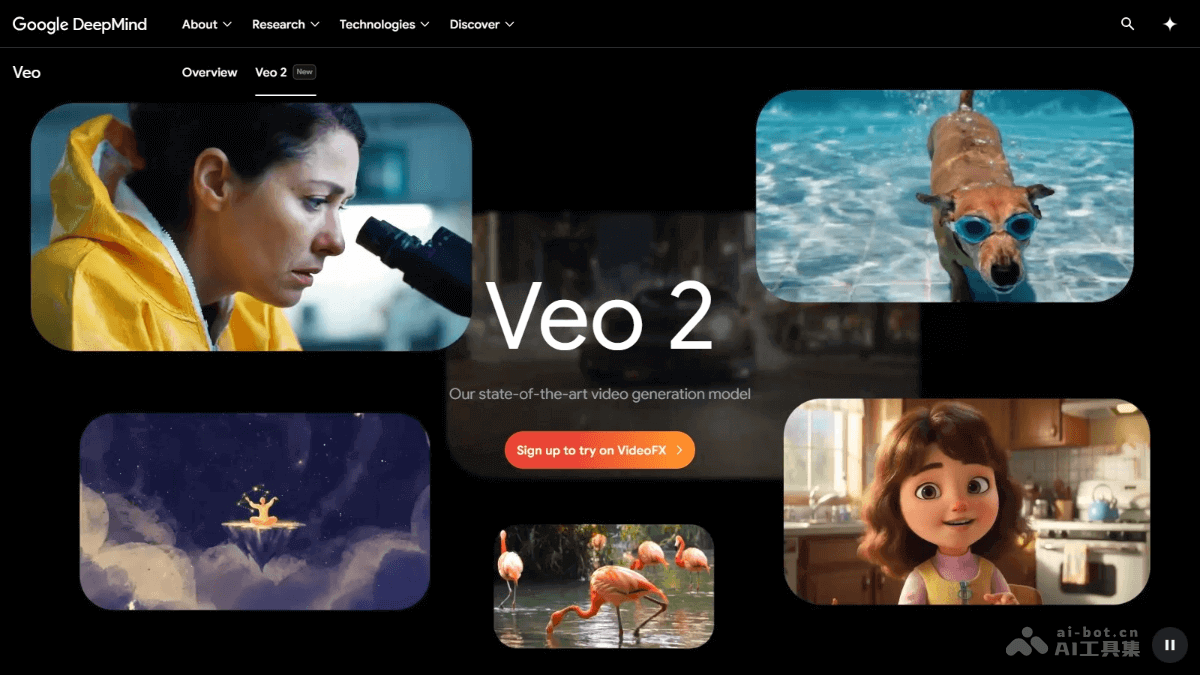
Veo 2 是 Google DeepMind 推出的 AI 视频生成模型,能根据文本或图像提示生成高质量视频内容。Veo 2支持高达 4K 分辨率的视频制作,理解镜头控制指令,能模拟现实世界的物理现象及人类表情。Veo 2...
-

Megrez-3B-Omni是无问芯穹推出的全球首个端侧全模态理解开源模型,能处理图像、音频和文本三种模态数据。Megrez-3B-Omni在多个主流测试集上展现出超越34B模型的性能,推理速度领先同精度模型达300%。...
-

FreeScale是南洋理工大学、阿里巴巴集团和复旦大学推出无需微调的推理框架,提升预训练扩散模型生成高分辨率图像和视频的能力。FreeScale基于处理和融合不同尺度的信息,有效解决模型在生成超训练分辨率内容时出现的高频信...
-

SnapGen是Snap Inc、香港科技大学、墨尔本大学等机构联合推出的文本到图像(T2I)扩散模型,能在移动设备上快速生成高分辨率(1024x1024像素)的图像,且只需1.4秒。模型用379M参数实现这一性能,显著减少...
-
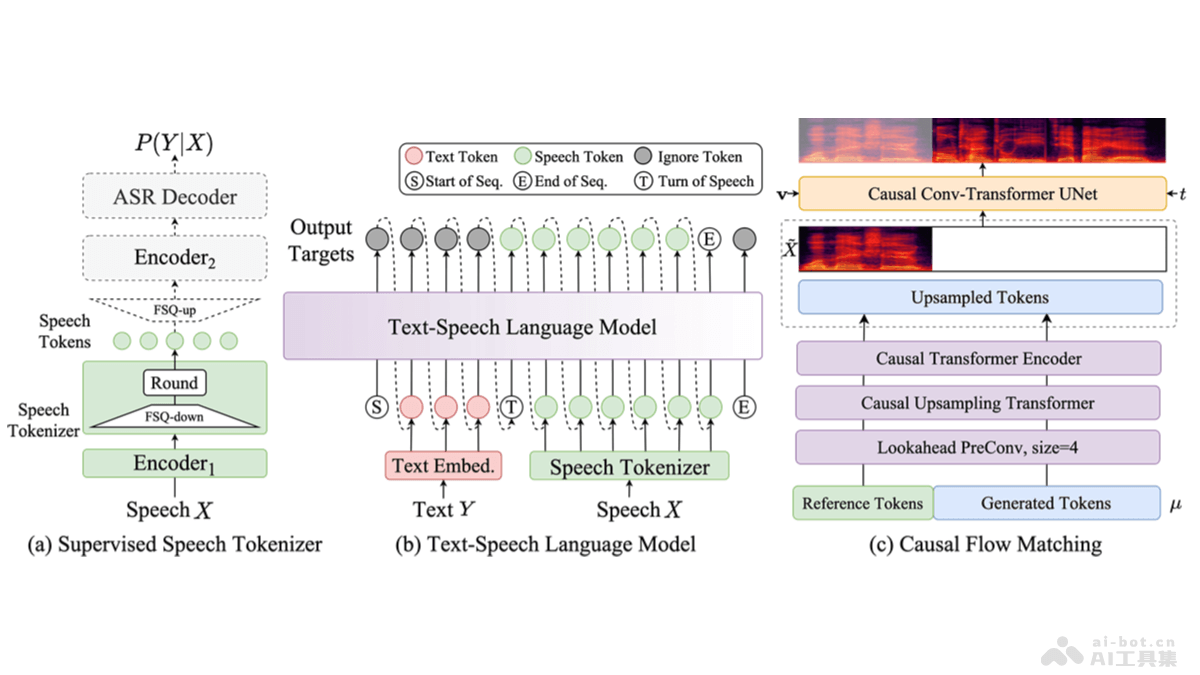
CosyVoice 2.0 是阿里巴巴通义实验室推出的CosyVoice语音生成大模型升级版,模型用有限标量量化技术提高码本利用率,简化文本-语音语言模型架构,推出块感知因果流匹配模型支持多样的合成场景。CosyVoice...
