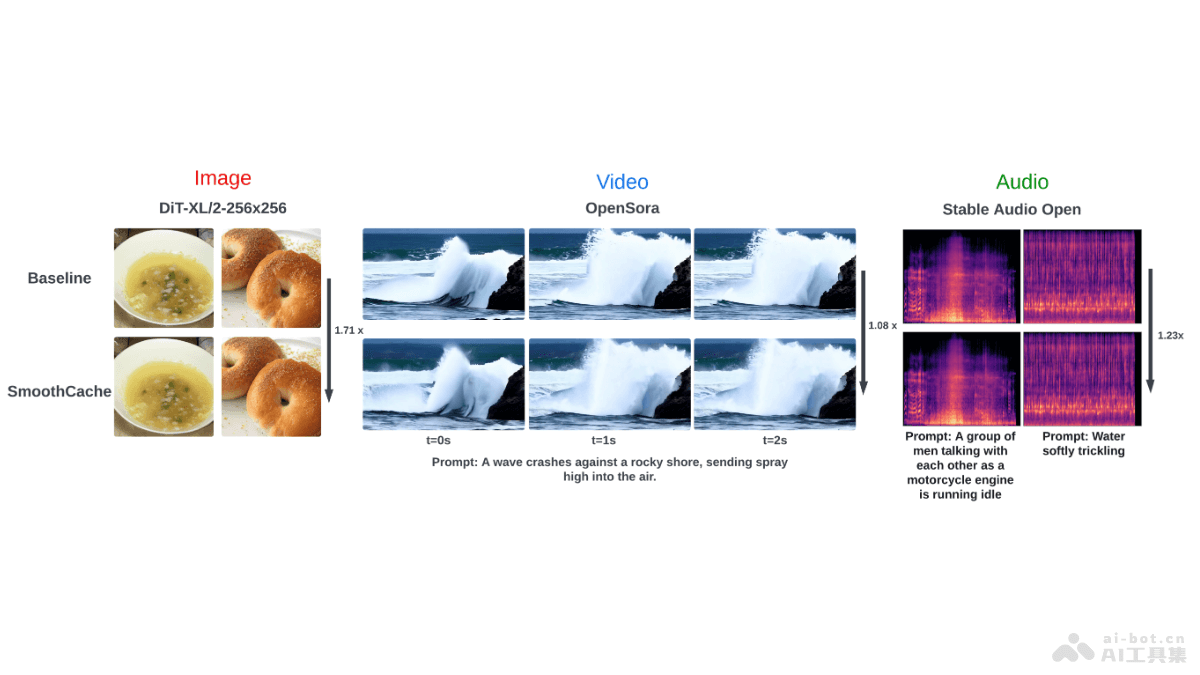
In-Context LoRA是阿里巴巴通义实验室推出的基于扩散变换器(DiTs)的图像生成框架,用模型的内在上下文学习能力,最小化调整激活模型的上下文生成能力。这种方法无需修改原始模型架构,只需对训练数据进行微调,就能适应多样的图像生成任务,有效简化训练过程并减少对大量标注数据的依赖,且保持高生成质量。In-Context LoRA在多个实际应用场景中表现出色,能生成连贯一致且高度符合提示的图像集合,支持条件图像生成。
 In-Context LoRA的主要功能多任务图像生成:适应多种图像生成任务,如故事板生成、字体设计、家居装饰等,无需针对每个任务训练特定模型。上下文学习能力:用现有文本到图像模型的内在上下文学习能力,基于小数据集的LoRA调整、激活和增强能力。任务无关性:在数据调整上是任务特定的,但在架构和流程上保持任务不可知,让框架能够适应广泛的任务。图像集生成:能同时生成具有定制内在关系的图像集,图像集是有条件的或基于文本提示的。条件图像生成:支持基于现有图像集的条件生成,用SDEdit技术进行训练免费的图像补全。In-Context LoRA的技术原理扩散变换器(DiTs):基于扩散变换器(DiTs),用于图像生成的模型,模拟扩散过程逐步构建图像。上下文生成能力:该技术假设文本到图像的DiTs天生就具备上下文生成能力,理解和生成具有复杂内在关系的图像集。图像连接:与其连接注意力标记(tokens)不同,In-Context LoRA将一组图像直接连接成一张大图像进行训练,类似于在DiTs中连接标记。联合描述:合并每个图像的提示(prompts)形成一个长的提示,模型能同时处理和生成多个图像。小数据集的LoRA调整:用小数据集(20到100个样本)进行Low-Rank Adaptation(LoRA)调整,激活和增强模型的上下文能力。任务特定的调整:In-Context LoRA的架构和流程保持任务不可知,适应不同的任务不需要修改原始模型架构。In-Context LoRA的项目地址项目官网:ali-vilab.github.io/In-Context-LoRA-PageGitHub仓库:https://github.com/ali-vilab/In-Context-LoRAarXiv技术论文:https://arxiv.org/pdf/2410.23775In-Context LoRA的应用场景故事板生成:用在电影、广告或动画制作中,快速生成一系列场景图像,展示故事情节的发展。字体设计:设计和生成具有特定风格和主题的字体,适于品牌标识、海报、邀请函等。家居装饰:生成家居装饰风格的图像,帮助设计师和客户预览装饰效果,如墙面颜色、家具布局等。肖像插画:将个人照片转换成艺术风格的插画,用于个人肖像、社交媒体头像或艺术作品。人像摄影:生成具有特定风格和背景的人像照片,用在时尚杂志、广告或个人艺术照。
In-Context LoRA的主要功能多任务图像生成:适应多种图像生成任务,如故事板生成、字体设计、家居装饰等,无需针对每个任务训练特定模型。上下文学习能力:用现有文本到图像模型的内在上下文学习能力,基于小数据集的LoRA调整、激活和增强能力。任务无关性:在数据调整上是任务特定的,但在架构和流程上保持任务不可知,让框架能够适应广泛的任务。图像集生成:能同时生成具有定制内在关系的图像集,图像集是有条件的或基于文本提示的。条件图像生成:支持基于现有图像集的条件生成,用SDEdit技术进行训练免费的图像补全。In-Context LoRA的技术原理扩散变换器(DiTs):基于扩散变换器(DiTs),用于图像生成的模型,模拟扩散过程逐步构建图像。上下文生成能力:该技术假设文本到图像的DiTs天生就具备上下文生成能力,理解和生成具有复杂内在关系的图像集。图像连接:与其连接注意力标记(tokens)不同,In-Context LoRA将一组图像直接连接成一张大图像进行训练,类似于在DiTs中连接标记。联合描述:合并每个图像的提示(prompts)形成一个长的提示,模型能同时处理和生成多个图像。小数据集的LoRA调整:用小数据集(20到100个样本)进行Low-Rank Adaptation(LoRA)调整,激活和增强模型的上下文能力。任务特定的调整:In-Context LoRA的架构和流程保持任务不可知,适应不同的任务不需要修改原始模型架构。In-Context LoRA的项目地址项目官网:ali-vilab.github.io/In-Context-LoRA-PageGitHub仓库:https://github.com/ali-vilab/In-Context-LoRAarXiv技术论文:https://arxiv.org/pdf/2410.23775In-Context LoRA的应用场景故事板生成:用在电影、广告或动画制作中,快速生成一系列场景图像,展示故事情节的发展。字体设计:设计和生成具有特定风格和主题的字体,适于品牌标识、海报、邀请函等。家居装饰:生成家居装饰风格的图像,帮助设计师和客户预览装饰效果,如墙面颜色、家具布局等。肖像插画:将个人照片转换成艺术风格的插画,用于个人肖像、社交媒体头像或艺术作品。人像摄影:生成具有特定风格和背景的人像照片,用在时尚杂志、广告或个人艺术照。