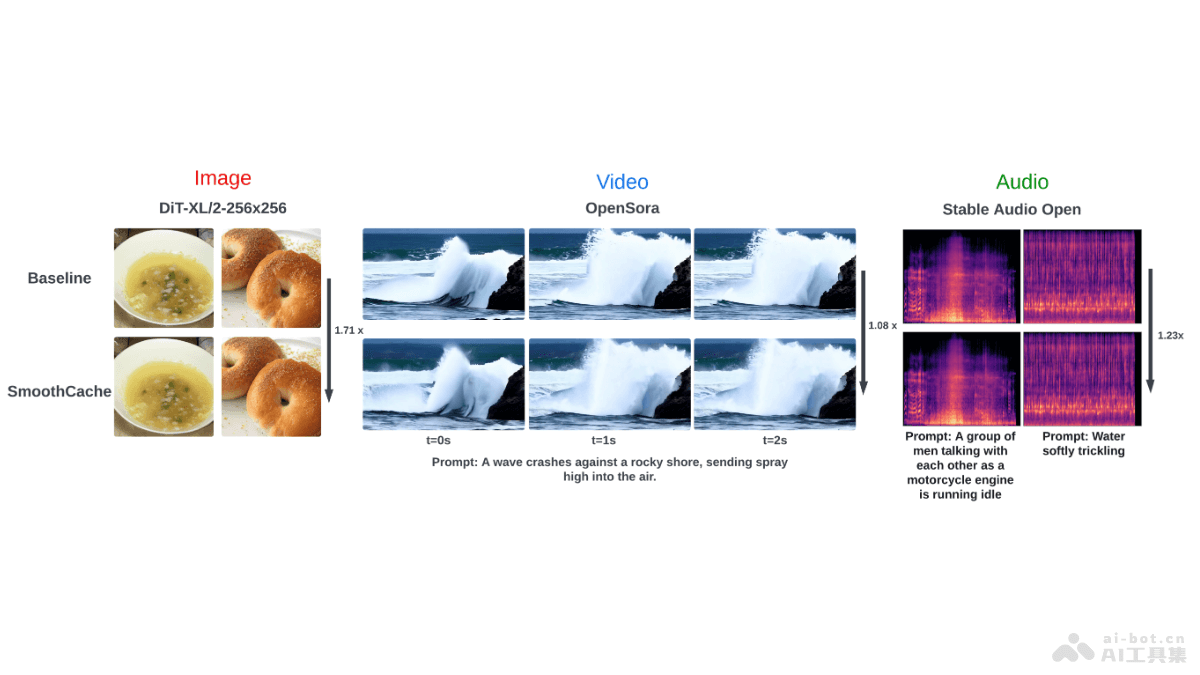
StableV2V是中国科技大学推出的开源视频编辑项目,基于文本、草图、图片等输入实现视频中物体的精准编辑和替换。项目用形状一致的编辑范式,基于三个主要组件:Prompted First-frame Editor(PFE)、Iterative Shape Aligner(ISA)和Conditional Image-to-video Generator(CIG),确保编辑内容与原始视频动作和深度信息一致,生成自然流畅的编辑视频。
 StableV2V的主要功能基于多种输入的视频编辑:支持文本、草图、图片等多种输入方式,实现视频中物体的编辑和替换。形状一致性保持:确保编辑后的视频内容在形状和运动上与原始视频保持一致性,即使在物体形状发生显著变化时。灵活的用户提示处理:灵活处理不同类型的用户提示,提供更广泛的创意空间。高质量的视频输出:生成高质量的编辑视频,具备出色的视觉效果。StableV2V的技术原理Prompted First-frame Editor (PFE):作为编辑流程的起点,PFE负责将用户的提示(文本、图像、草图等)转化为视频的第一帧编辑内容。Iterative Shape Aligner (ISA):ISA基于假设编辑内容与原始内容共享相同的运动和深度信息,用深度图作为传递运动的桥梁。基于运动模拟和深度模拟过程,ISA能计算和传播平均运动、形状和深度信息。用形状引导的深度细化网络对深度图进行优化,确保物体与周围环境的交互看起来自然合理。Conditional Image-to-video Generator (CIG):CIG负责将编辑后的第一帧和优化后的深度图转化为完整的编辑视频。用Ctrl-Adapter作为控制器,将深度图信息注入生成过程。借助I2VGen-XL将编辑内容从首帧扩展到整个视频序列,生成高质量的编辑视频。深度信息的运用:深度图扮演着关键角色,传递运动信息和指导视频生成,确保编辑内容的深度和运动与原始视频一致。组件协同工作:PFE、ISA和CIG三个组件协同工作,确保从第一帧编辑到视频生成的整个过程都保持高度的一致性和自然性。StableV2V的项目地址项目官网:alonzoleeeooo.github.io/StableV2VGitHub仓库:https://github.com/AlonzoLeeeooo/StableV2VHuggingFace模型库:https://huggingface.co/AlonzoLeeeooo/StableV2VarXiv技术论文:https://arxiv.org/pdf/2411.11045StableV2V的应用场景电影和视频制作:用在特效制作、场景变换和角色替换,无需重新拍摄即可实现创意视觉效果。社交媒体内容创作:内容创作者快速编辑视频内容,增加视频的吸引力和创意,如将普通场景变成艺术风格的作品。教育和培训:制作教学视频,将抽象概念形象化,如历史场景重现或科学现象模拟,及安全演练和技术操作示范。新闻和报道:对现场视频进行编辑和增强,提供更清晰、更具体的视觉报道,如模拟自然灾害发生过程。广告和营销:创造更具吸引力的广告视频,将产品融入创意场景中,提高广告的吸引力和记忆度。
StableV2V的主要功能基于多种输入的视频编辑:支持文本、草图、图片等多种输入方式,实现视频中物体的编辑和替换。形状一致性保持:确保编辑后的视频内容在形状和运动上与原始视频保持一致性,即使在物体形状发生显著变化时。灵活的用户提示处理:灵活处理不同类型的用户提示,提供更广泛的创意空间。高质量的视频输出:生成高质量的编辑视频,具备出色的视觉效果。StableV2V的技术原理Prompted First-frame Editor (PFE):作为编辑流程的起点,PFE负责将用户的提示(文本、图像、草图等)转化为视频的第一帧编辑内容。Iterative Shape Aligner (ISA):ISA基于假设编辑内容与原始内容共享相同的运动和深度信息,用深度图作为传递运动的桥梁。基于运动模拟和深度模拟过程,ISA能计算和传播平均运动、形状和深度信息。用形状引导的深度细化网络对深度图进行优化,确保物体与周围环境的交互看起来自然合理。Conditional Image-to-video Generator (CIG):CIG负责将编辑后的第一帧和优化后的深度图转化为完整的编辑视频。用Ctrl-Adapter作为控制器,将深度图信息注入生成过程。借助I2VGen-XL将编辑内容从首帧扩展到整个视频序列,生成高质量的编辑视频。深度信息的运用:深度图扮演着关键角色,传递运动信息和指导视频生成,确保编辑内容的深度和运动与原始视频一致。组件协同工作:PFE、ISA和CIG三个组件协同工作,确保从第一帧编辑到视频生成的整个过程都保持高度的一致性和自然性。StableV2V的项目地址项目官网:alonzoleeeooo.github.io/StableV2VGitHub仓库:https://github.com/AlonzoLeeeooo/StableV2VHuggingFace模型库:https://huggingface.co/AlonzoLeeeooo/StableV2VarXiv技术论文:https://arxiv.org/pdf/2411.11045StableV2V的应用场景电影和视频制作:用在特效制作、场景变换和角色替换,无需重新拍摄即可实现创意视觉效果。社交媒体内容创作:内容创作者快速编辑视频内容,增加视频的吸引力和创意,如将普通场景变成艺术风格的作品。教育和培训:制作教学视频,将抽象概念形象化,如历史场景重现或科学现象模拟,及安全演练和技术操作示范。新闻和报道:对现场视频进行编辑和增强,提供更清晰、更具体的视觉报道,如模拟自然灾害发生过程。广告和营销:创造更具吸引力的广告视频,将产品融入创意场景中,提高广告的吸引力和记忆度。