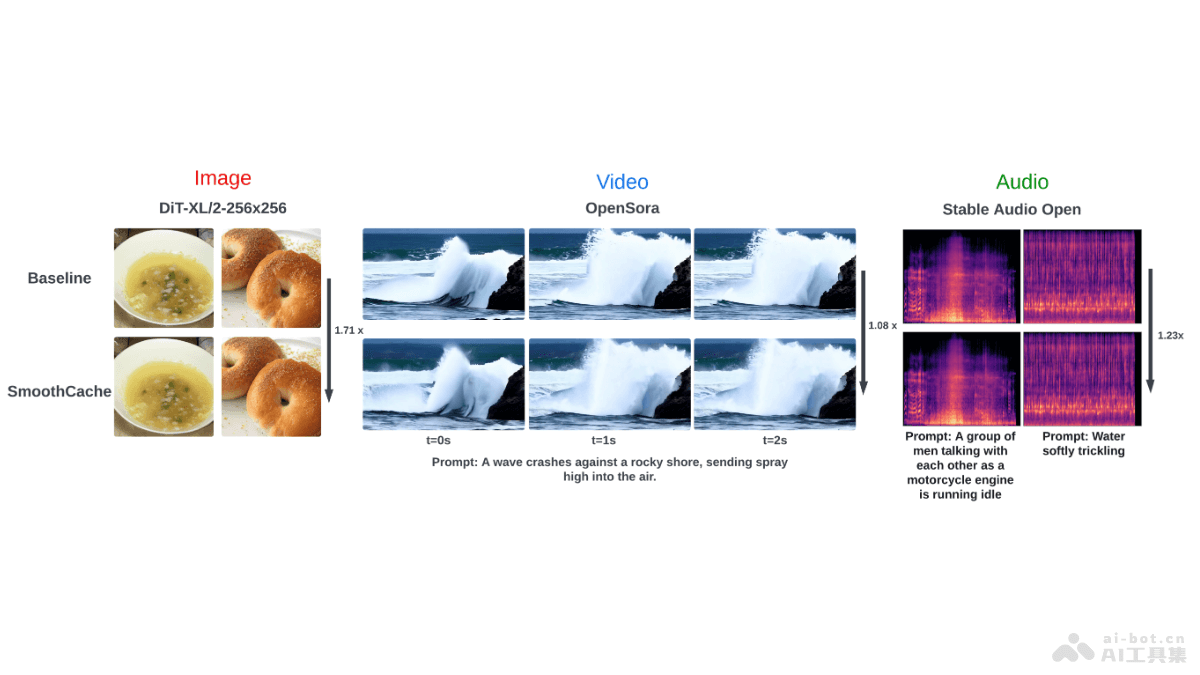
LaTRO(Latent Reasoning Optimization)是先进的框架,提升大型语言模型(LLMs)在复杂推理任务中的表现。基于将推理过程类比为从潜在分布中采样,用变分推断方法进行优化,LaTRO让模型自我改进,增强生成和评估推理路径的能力。这一方法无需依赖外部反馈或奖励机制,有效解锁并进一步激发预训练语言模型内在的推理潜能,推动构建更智能、更自主的问题解决系统。
 LaTRO的主要功能优化推理能力:基于自奖励机制,帮助大型语言模型(LLMs)在无需外部反馈的情况下提高复杂推理任务的处理能力。并行改进:LLMs能同时改进推理过程和评估推理质量的能力。解锁潜在能力:解锁预训练LLMs中潜在的推理能力,使之得到增强。变分推断:基于变分推断方法,将推理过程视为从潜在分布中采样,并优化这一分布。LaTRO的技术原理推理作为采样:LaTRO将推理过程视为从潜在分布中采样,推理路径被视为影响最终答案的随机变量。自奖励机制:用模型自身的概率估计评估生成的推理路径的质量。变分优化:基于变分方法,优化潜在分布,让生成高质量推理路径的概率最大化。联合学习:基于联合学习单一的大型语言模型,能生成好的推理路径,也能在给定问题和推理路径的情况下提供正确答案。梯度估计:用REINFORCE Leave-One-Out (RLOO) 方法估计梯度,基于过采样多个推理路径来低梯度估计的方差。蒙特卡洛采样:用蒙特卡洛采样生成多个推理路径,基于推理路径更新模型参数。对抗过拟合:基于限制推理路径的最大长度和引入截断策略来控制过拟合,确保模型生成的推理路径既简洁又有效。LaTRO的项目地址GitHub仓库:https://github.com/SalesforceAIResearch/LaTROarXiv技术论文:https://arxiv.org/pdf/2411.04282LaTRO的应用场景数学问题求解:应用于解决需要多步逻辑推理的数学问题,如代数、几何和微积分问题。科学问题解答:在科学领域,帮助模型解决需要推理和解释科学现象或实验结果的问题。编程任务:辅助编程语言模型,能够更好地理解和生成代码,解决编程挑战和调试任务。逻辑推理:在逻辑推理任务中,提升模型的推理能力,如解决逻辑谜题、推理游戏或法律案例分析。自然语言理解:增强模型对自然语言的理解,特别是在需要深层次推理和解释语言含义的场景中。
LaTRO的主要功能优化推理能力:基于自奖励机制,帮助大型语言模型(LLMs)在无需外部反馈的情况下提高复杂推理任务的处理能力。并行改进:LLMs能同时改进推理过程和评估推理质量的能力。解锁潜在能力:解锁预训练LLMs中潜在的推理能力,使之得到增强。变分推断:基于变分推断方法,将推理过程视为从潜在分布中采样,并优化这一分布。LaTRO的技术原理推理作为采样:LaTRO将推理过程视为从潜在分布中采样,推理路径被视为影响最终答案的随机变量。自奖励机制:用模型自身的概率估计评估生成的推理路径的质量。变分优化:基于变分方法,优化潜在分布,让生成高质量推理路径的概率最大化。联合学习:基于联合学习单一的大型语言模型,能生成好的推理路径,也能在给定问题和推理路径的情况下提供正确答案。梯度估计:用REINFORCE Leave-One-Out (RLOO) 方法估计梯度,基于过采样多个推理路径来低梯度估计的方差。蒙特卡洛采样:用蒙特卡洛采样生成多个推理路径,基于推理路径更新模型参数。对抗过拟合:基于限制推理路径的最大长度和引入截断策略来控制过拟合,确保模型生成的推理路径既简洁又有效。LaTRO的项目地址GitHub仓库:https://github.com/SalesforceAIResearch/LaTROarXiv技术论文:https://arxiv.org/pdf/2411.04282LaTRO的应用场景数学问题求解:应用于解决需要多步逻辑推理的数学问题,如代数、几何和微积分问题。科学问题解答:在科学领域,帮助模型解决需要推理和解释科学现象或实验结果的问题。编程任务:辅助编程语言模型,能够更好地理解和生成代码,解决编程挑战和调试任务。逻辑推理:在逻辑推理任务中,提升模型的推理能力,如解决逻辑谜题、推理游戏或法律案例分析。自然语言理解:增强模型对自然语言的理解,特别是在需要深层次推理和解释语言含义的场景中。