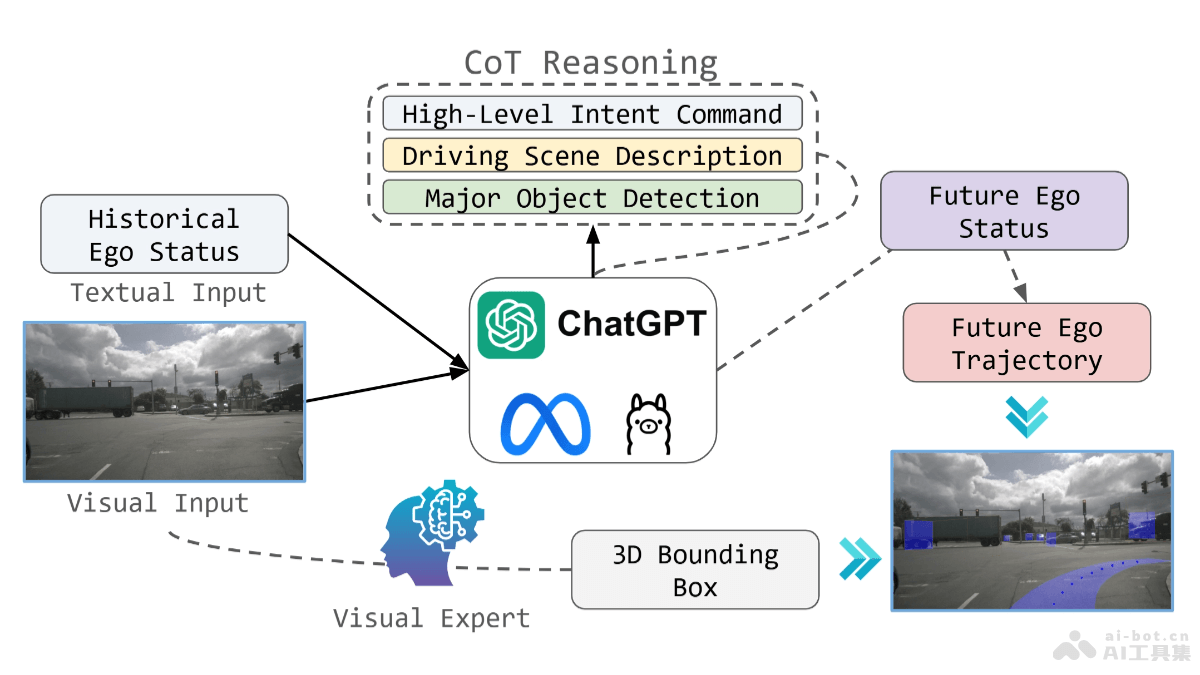
EchoMimicV2是蚂蚁集团推出的半身人体动画(数字人)生成方法,基于参考图片、音频剪辑和手部姿势序列生成高质量动画视频,确保音频内容与半身动作的一致性。EchoMimicV2在前代 EchoMimicV1 生成逼真人头动画的基础上,进一步发展,现在能生成完整的数字人半身动画,实现从中英文语音到动作的无缝转换。该方法用音频-姿势动态协调策略,包括姿势采样和音频扩散,增强细节表现力并减少条件冗余。EchoMimicV2用头部局部注意力技术整合头部数据,设计特定阶段去噪损失优化动画质量。
 EchoMimicV2的主要功能音频驱动的动画生成:用音频剪辑驱动人物的面部表情和身体动作,实现音频与动画的同步。半身动画制作:从仅生成头部动画扩展到生成包括上半身的动画。简化的控制条件:减少动画生成过程中所需的复杂条件,让动画制作更为简便。手势和表情同步:基于手部姿势序列与音频的结合,生成自然且同步的手势和面部表情。多语言支持:支持中文和英文驱动,根据语言内容生成相应的动画。EchoMimicV2的技术原理音频-姿势动态协调(APDH):姿势采样(Pose Sampling):逐步减少姿势条件的依赖,让音频条件在动画中扮演更重要的角色。音频扩散(Audio Diffusion):将音频条件的影响从嘴唇扩散到整个面部,再到全身,增强音频与动画的同步性。头部局部注意力(Head Partial Attention, HPA):在训练中整合头部数据,增强面部表情的细节,无需额外的插件或模块。特定阶段去噪损失(Phase-specific Denoising Loss, PhD Loss):将去噪过程分为三个阶段:姿势主导、细节主导和质量主导,每个阶段都有特定的优化目标。Latent Diffusion Model(LDM):用变分自编码器(VAE)将图像映射到潜在空间,在训练过程中逐步添加噪声,估计并去除每个时间步的噪声。ReferenceNet-based Backbone:用ReferenceNet从参考图像中提取特征,将其注入到去噪U-Net中,保持生成图像与参考图像之间的外观一致性。EchoMimicV2的生成效果展示效果一:中文音频驱动效果二:英文音频驱动效果三:FLUX生成的参考图像
EchoMimicV2的主要功能音频驱动的动画生成:用音频剪辑驱动人物的面部表情和身体动作,实现音频与动画的同步。半身动画制作:从仅生成头部动画扩展到生成包括上半身的动画。简化的控制条件:减少动画生成过程中所需的复杂条件,让动画制作更为简便。手势和表情同步:基于手部姿势序列与音频的结合,生成自然且同步的手势和面部表情。多语言支持:支持中文和英文驱动,根据语言内容生成相应的动画。EchoMimicV2的技术原理音频-姿势动态协调(APDH):姿势采样(Pose Sampling):逐步减少姿势条件的依赖,让音频条件在动画中扮演更重要的角色。音频扩散(Audio Diffusion):将音频条件的影响从嘴唇扩散到整个面部,再到全身,增强音频与动画的同步性。头部局部注意力(Head Partial Attention, HPA):在训练中整合头部数据,增强面部表情的细节,无需额外的插件或模块。特定阶段去噪损失(Phase-specific Denoising Loss, PhD Loss):将去噪过程分为三个阶段:姿势主导、细节主导和质量主导,每个阶段都有特定的优化目标。Latent Diffusion Model(LDM):用变分自编码器(VAE)将图像映射到潜在空间,在训练过程中逐步添加噪声,估计并去除每个时间步的噪声。ReferenceNet-based Backbone:用ReferenceNet从参考图像中提取特征,将其注入到去噪U-Net中,保持生成图像与参考图像之间的外观一致性。EchoMimicV2的生成效果展示效果一:中文音频驱动效果二:英文音频驱动效果三:FLUX生成的参考图像 EchoMimicV2的项目地址项目官网:antgroup.github.io/ai/echomimic_v2GitHub仓库:https://github.com/antgroup/echomimic_v2HuggingFace模型库:https://huggingface.co/BadToBest/EchoMimicV2arXiv技术论文:https://arxiv.org/pdf/2411.10061EchoMimicV2的应用场景虚拟主播:创建虚拟新闻主播或直播主播,用中文或英文进行直播,提高内容生产的效率和多样性。在线教育:制作虚拟教师或讲师,提供在线课程和培训,让教育资源更加丰富和可访问。娱乐和游戏:在游戏中创建逼真的非玩家角色(NPC),提供更加自然和流畅的交互体验。电影和视频制作:用在动作捕捉和后期制作,减少实际拍摄的成本和复杂性,提高制作效率。客户服务:作为虚拟客服代表,提供多语言的客户支持,提高服务质量和响应速度。
EchoMimicV2的项目地址项目官网:antgroup.github.io/ai/echomimic_v2GitHub仓库:https://github.com/antgroup/echomimic_v2HuggingFace模型库:https://huggingface.co/BadToBest/EchoMimicV2arXiv技术论文:https://arxiv.org/pdf/2411.10061EchoMimicV2的应用场景虚拟主播:创建虚拟新闻主播或直播主播,用中文或英文进行直播,提高内容生产的效率和多样性。在线教育:制作虚拟教师或讲师,提供在线课程和培训,让教育资源更加丰富和可访问。娱乐和游戏:在游戏中创建逼真的非玩家角色(NPC),提供更加自然和流畅的交互体验。电影和视频制作:用在动作捕捉和后期制作,减少实际拍摄的成本和复杂性,提高制作效率。客户服务:作为虚拟客服代表,提供多语言的客户支持,提高服务质量和响应速度。