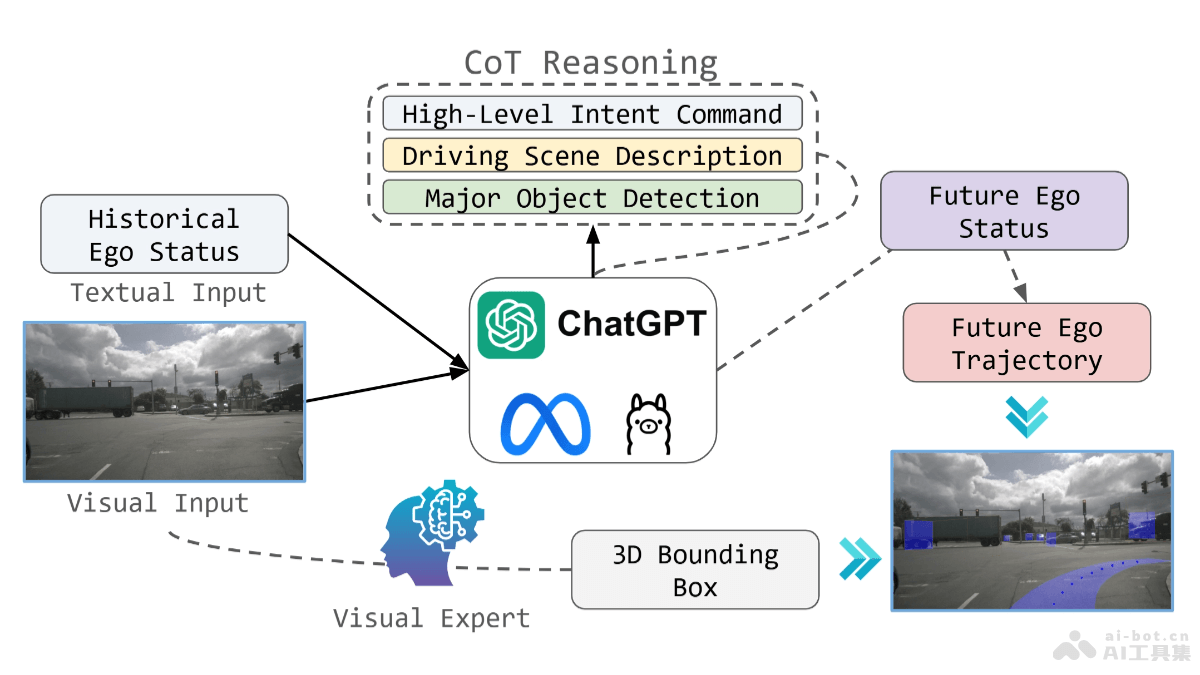
TÜLU 3是艾伦人工智能研究所(Ai2)推出的一系列开源指令遵循模型,包括8B和70B两个版本,未来计划推出405B版本。模型在性能上超越Llama 3.1 Instruct版本,提供了详细的后训练技术报告,公开数据、评估代码和训练算法。TÜLU 3基于强化学习、直接偏好优化等先进技术,显著提升模型在数学、编程和指令遵循等核心技能上的表现,推动开源模型在多目标、多阶段训练框架内的研究进展。
 TÜLU 3的主要功能提升语言模型性能:TÜLU 3用后训练技术显著提高语言模型在多种任务上的表现,包括知识回忆、推理、数学问题解决、编程和指令遵循等。多任务处理能力:作为多技能的语言模型,能处理广泛的任务,从基础的问答到复杂的逻辑推理和编程问题。后训练方法的创新:引入新的后训练方法,如直接偏好优化(DPO)和可验证奖励的强化学习(RLVR),进一步提升模型性能。数据集和评估工具:提供大量的训练数据集和评估工具,帮助研究人员评估和优化模型在特定任务上的表现。模型微调:基于监督微调(SFT)和偏好微调,让模型更好地适应特定的任务和指令。TÜLU 3的技术原理后训练(Post-Training):TÜLU 3在预训练模型的基础上进行后训练,包括监督微调、偏好微调和强化学习等阶段,提升模型在特定任务上的表现。监督微调(SFT):用精心挑选的数据集对模型进行微调,增强模型在特定技能上的表现,如数学和编程。直接偏好优化(DPO):基于偏好反馈的优化方法,直接从偏好数据中学习,无需额外的奖励模型,提高模型对用户偏好的适应性。可验证奖励的强化学习(RLVR):在可验证的任务(如数学问题解决)上,只有当模型的输出被验证为正确时,才给予奖励,提高模型在任务上的性能。数据质量和规模:基于合成数据和公开数据集的整合,确保训练数据的多样性和质量,对于提升模型的泛化能力至关重要。TÜLU 3的项目地址GitHub仓库:https://github.com/allenai/open-instruct/blob/main/docs/tulu3.mdHuggingFace模型库:https://huggingface.co/collections/allenai/tulu-3-datasets-673b8df14442393f7213f372技术论文:https://allenai.org/papers/tulu-3-report.pdf在线体验Demo:https://playground.allenai.org/TÜLU 3的应用场景自然语言处理(NLP)研究:作为研究工具,帮助研究人员在各种NLP任务上进行实验和创新,如文本分类、情感分析、机器翻译等。教育和学术:在教育领域,作为教学辅助工具,帮助学生学习和理解复杂的概念。学术研究中,用于文献综述、数据分析和学术写作的辅助。软件开发:在编程和软件开发中,帮助开发者自动生成代码、修复代码错误及提供编程语言的学习。聊天机器人和虚拟助手:集成到聊天机器人和虚拟助手中,提供更加智能和自然的对话体验。内容创作和媒体:在内容创作领域,帮助生成文章、故事和其他创意文本,辅助编辑和写作。
TÜLU 3的主要功能提升语言模型性能:TÜLU 3用后训练技术显著提高语言模型在多种任务上的表现,包括知识回忆、推理、数学问题解决、编程和指令遵循等。多任务处理能力:作为多技能的语言模型,能处理广泛的任务,从基础的问答到复杂的逻辑推理和编程问题。后训练方法的创新:引入新的后训练方法,如直接偏好优化(DPO)和可验证奖励的强化学习(RLVR),进一步提升模型性能。数据集和评估工具:提供大量的训练数据集和评估工具,帮助研究人员评估和优化模型在特定任务上的表现。模型微调:基于监督微调(SFT)和偏好微调,让模型更好地适应特定的任务和指令。TÜLU 3的技术原理后训练(Post-Training):TÜLU 3在预训练模型的基础上进行后训练,包括监督微调、偏好微调和强化学习等阶段,提升模型在特定任务上的表现。监督微调(SFT):用精心挑选的数据集对模型进行微调,增强模型在特定技能上的表现,如数学和编程。直接偏好优化(DPO):基于偏好反馈的优化方法,直接从偏好数据中学习,无需额外的奖励模型,提高模型对用户偏好的适应性。可验证奖励的强化学习(RLVR):在可验证的任务(如数学问题解决)上,只有当模型的输出被验证为正确时,才给予奖励,提高模型在任务上的性能。数据质量和规模:基于合成数据和公开数据集的整合,确保训练数据的多样性和质量,对于提升模型的泛化能力至关重要。TÜLU 3的项目地址GitHub仓库:https://github.com/allenai/open-instruct/blob/main/docs/tulu3.mdHuggingFace模型库:https://huggingface.co/collections/allenai/tulu-3-datasets-673b8df14442393f7213f372技术论文:https://allenai.org/papers/tulu-3-report.pdf在线体验Demo:https://playground.allenai.org/TÜLU 3的应用场景自然语言处理(NLP)研究:作为研究工具,帮助研究人员在各种NLP任务上进行实验和创新,如文本分类、情感分析、机器翻译等。教育和学术:在教育领域,作为教学辅助工具,帮助学生学习和理解复杂的概念。学术研究中,用于文献综述、数据分析和学术写作的辅助。软件开发:在编程和软件开发中,帮助开发者自动生成代码、修复代码错误及提供编程语言的学习。聊天机器人和虚拟助手:集成到聊天机器人和虚拟助手中,提供更加智能和自然的对话体验。内容创作和媒体:在内容创作领域,帮助生成文章、故事和其他创意文本,辅助编辑和写作。