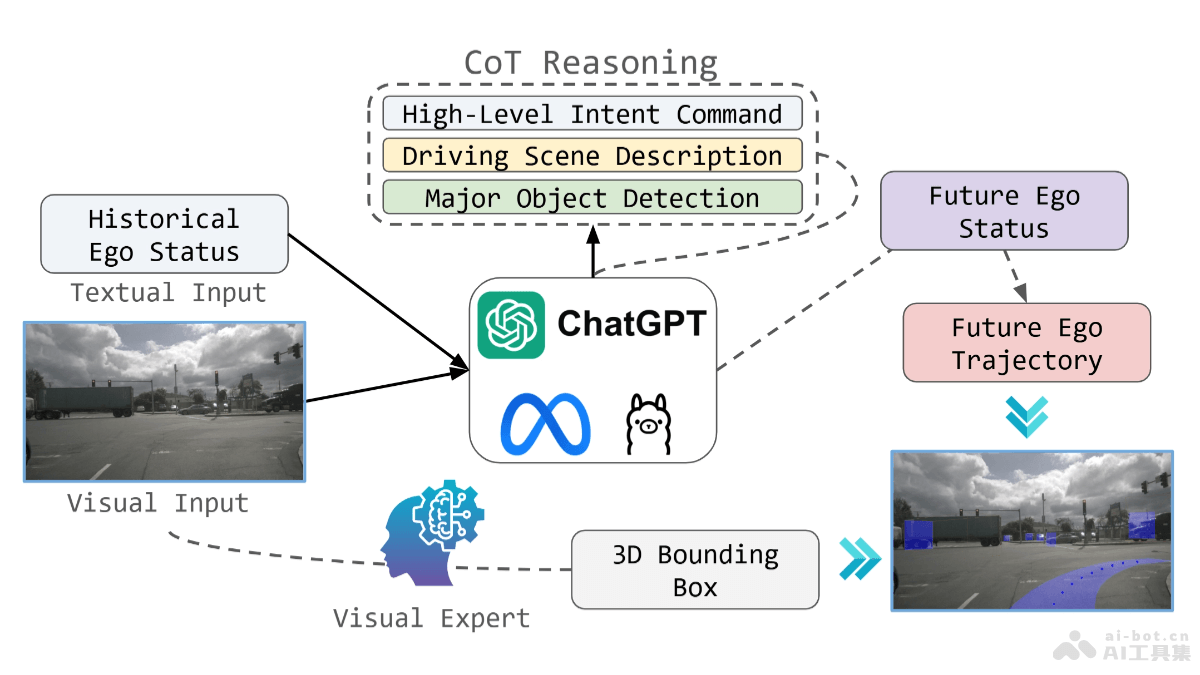
DELIFT(Data Efficient Language model Instruction Fine-Tuning)是基于高效数据优化语言模型指令微调,一种新颖的算法,用在优化大型语言模型(LLMs)在指令调优、任务特定微调和持续微调三个关键阶段的数据选择。基于成对效用度量和次模优化技术,高效选择多样化和最优的数据子集,减少计算资源消耗,同时保持或提升模型性能。实验显示,DELIFT能将微调数据量减少70%,显著节省计算资源,且效果优于现有方法。
 DELIFT的主要功能数据选择优化: 基于系统地优化数据选择,减少大型语言模型(LLMs)在微调过程中所需的数据量,同时保持或提升模型性能。跨阶段适用: 适用于微调的三个关键阶段:指令调优、任务特定微调和持续微调,为每个阶段提供定制化的数据选择策略。计算效率提升: 避免资源密集型的计算,如全量梯度计算,让算法高效地应用于大型数据集和模型。超越现有方法: 相比现有的数据选择方法,在效率和效能上都有显著提升,效果提升高达26%。DELIFT的技术原理成对效用度量: 核心是成对效用度量(pairwise utility metric),评估数据样本对于模型响应其他样本的改善程度,有效衡量数据样本相对于模型当前能力的信息价值。次模优化: 基于次模函数(submodular functions)选择数据子集,函数具有边际收益递减的特性,适合于选择多样化、信息丰富且非冗余的数据子集。定制化次模函数: 根据不同的微调阶段,应用不同的次模函数,如设施位置(FL)、设施位置互信息(FLMI)和设施位置条件增益(FLCG),适应指令调优、任务特定微调和持续微调的特定需求。贪婪算法: 用贪婪算法迭代构建数据子集,每次选择都能在所选的次模函数中提供最大边际增益的数据点。模型反馈集成: 将成对效用度量与次模优化相结合,根据模型的当前能力和弱点选择最有益的数据点,增强模型在目标任务上的性能。DELIFT的项目地址arXiv技术论文:https://arxiv.org/pdf/2411.04425DELIFT的应用场景数据科学家和机器学习工程师:负责优化和调整大型语言模型,适应特定的业务需求。研究人员和学术界:在自然语言处理、人工智能和机器学习领域进行研究,需要高效地微调模型进行实验和验证假设。软件开发者:开发智能应用,如聊天机器人、虚拟助手、内容推荐系统等,需要集成高效的语言模型。企业决策者:需要基于最新的人工智能技术提升业务流程和决策支持系统。教育工作者:开发个性化学习平台和教育工具,定制教育内容推荐。
DELIFT的主要功能数据选择优化: 基于系统地优化数据选择,减少大型语言模型(LLMs)在微调过程中所需的数据量,同时保持或提升模型性能。跨阶段适用: 适用于微调的三个关键阶段:指令调优、任务特定微调和持续微调,为每个阶段提供定制化的数据选择策略。计算效率提升: 避免资源密集型的计算,如全量梯度计算,让算法高效地应用于大型数据集和模型。超越现有方法: 相比现有的数据选择方法,在效率和效能上都有显著提升,效果提升高达26%。DELIFT的技术原理成对效用度量: 核心是成对效用度量(pairwise utility metric),评估数据样本对于模型响应其他样本的改善程度,有效衡量数据样本相对于模型当前能力的信息价值。次模优化: 基于次模函数(submodular functions)选择数据子集,函数具有边际收益递减的特性,适合于选择多样化、信息丰富且非冗余的数据子集。定制化次模函数: 根据不同的微调阶段,应用不同的次模函数,如设施位置(FL)、设施位置互信息(FLMI)和设施位置条件增益(FLCG),适应指令调优、任务特定微调和持续微调的特定需求。贪婪算法: 用贪婪算法迭代构建数据子集,每次选择都能在所选的次模函数中提供最大边际增益的数据点。模型反馈集成: 将成对效用度量与次模优化相结合,根据模型的当前能力和弱点选择最有益的数据点,增强模型在目标任务上的性能。DELIFT的项目地址arXiv技术论文:https://arxiv.org/pdf/2411.04425DELIFT的应用场景数据科学家和机器学习工程师:负责优化和调整大型语言模型,适应特定的业务需求。研究人员和学术界:在自然语言处理、人工智能和机器学习领域进行研究,需要高效地微调模型进行实验和验证假设。软件开发者:开发智能应用,如聊天机器人、虚拟助手、内容推荐系统等,需要集成高效的语言模型。企业决策者:需要基于最新的人工智能技术提升业务流程和决策支持系统。教育工作者:开发个性化学习平台和教育工具,定制教育内容推荐。