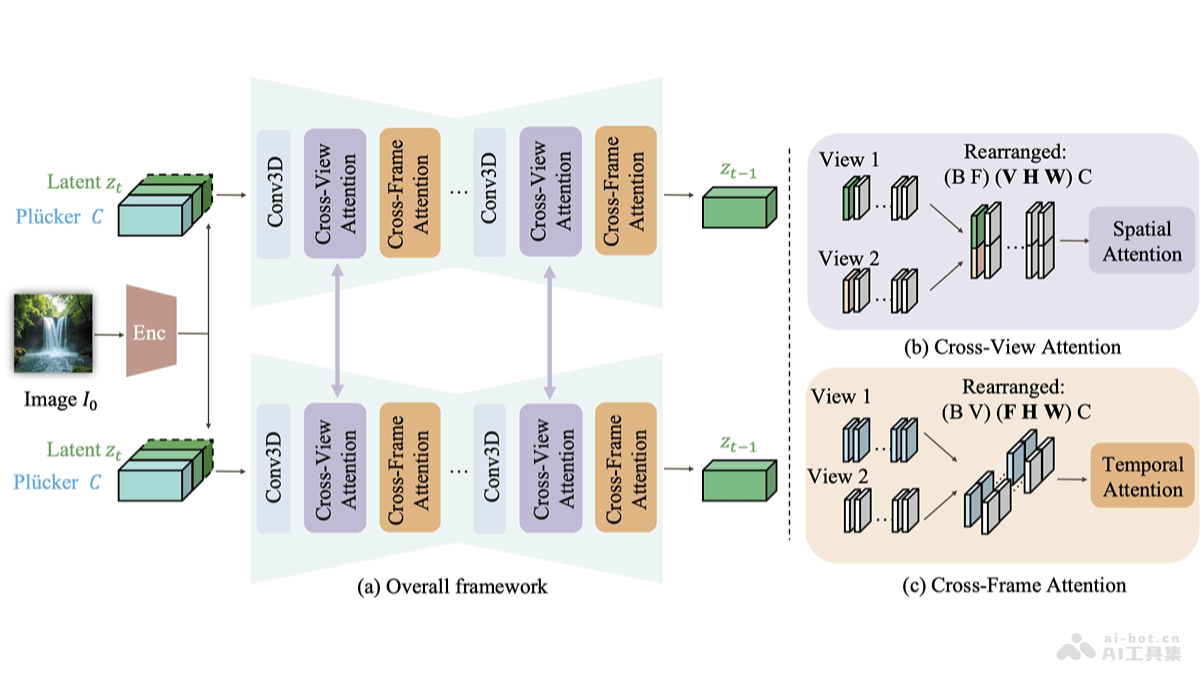
Kandinsky-3是基于潜在扩散模型的文本到图像(T2I)生成框架,支持高质量和逼真度在图像合成。Kandinsky-3能适应多种图像生成任务,包括文本引导的修复/扩展、图像融合、文本-图像融合及视频生成等。研究者们推出一个简化版本的T2I模型版本,该版本在保持图像质量的同时,将推理速度提高3倍,仅需4步逆向过程即可完成。Kandinsky-3的显著特点在于架构的简洁性和高效性,能适应多种图像生成任务。
 Kandinsky-3的主要功能文本到图像生成:根据用户提供的文本提示生成相应的图像。图像修复(Inpainting/Outpainting):智能填补图像中缺失或指定区域的内容,与周围视觉内容无缝融合。图像融合:将多个图像或图像与文本提示融合,创造出新的视觉效果。文本-图像融合:结合文本描述和图像内容生成新的图像。图像变化生成:基于原始图像生成风格或内容上的变化。视频生成:包括图像到视频(I2V)和文本到视频(T2V)的生成。模型蒸馏:提供简化版本的模型,提高推理速度,同时保持图像质量。Kandinsky-3的技术原理潜在扩散模型:基于潜在扩散模型,这种模型用在潜在空间中逐步去除噪声生成图像。文本编码器:用Flan-UL2 20B模型的文本编码器处理用户输入的文本提示,将其转换为被模型理解的潜在表示。U-Net网络:U-Net结构的网络能预测去噪过程中的噪声,逐步构建出清晰的图像。图像解码器:用Sber-MoVQGAN的图像解码器从潜在表示重建图像。全局交互:在U-Net的早期阶段仅用卷积块处理潜在表示,后期阶段引入变换层,确保图像元素之间的全局交互。Kandinsky-3的项目地址项目官网:ai-forever.github.io/Kandinsky-3GitHub仓库:https://github.com/ai-forever/Kandinsky-3HuggingFace模型库:https://huggingface.co/kandinsky-community/kandinsky-3arXiv技术论文:https://arxiv.org/pdf/2410.21061Kandinsky-3的应用场景艺术创作:艺术家创作数字艺术作品,快速将创意转化为视觉图像。媒体与娱乐:在电影制作中,生成或增强概念艺术,帮助导演和美术指导预览场景。广告行业:设计个性化的广告图像,吸引目标受众提高广告效果。教育:作为教学辅助工具,帮助学生更直观地理解历史事件或科学概念。新闻与出版:为在线新闻网站和杂志创造吸引人的插图和信息图表。
Kandinsky-3的主要功能文本到图像生成:根据用户提供的文本提示生成相应的图像。图像修复(Inpainting/Outpainting):智能填补图像中缺失或指定区域的内容,与周围视觉内容无缝融合。图像融合:将多个图像或图像与文本提示融合,创造出新的视觉效果。文本-图像融合:结合文本描述和图像内容生成新的图像。图像变化生成:基于原始图像生成风格或内容上的变化。视频生成:包括图像到视频(I2V)和文本到视频(T2V)的生成。模型蒸馏:提供简化版本的模型,提高推理速度,同时保持图像质量。Kandinsky-3的技术原理潜在扩散模型:基于潜在扩散模型,这种模型用在潜在空间中逐步去除噪声生成图像。文本编码器:用Flan-UL2 20B模型的文本编码器处理用户输入的文本提示,将其转换为被模型理解的潜在表示。U-Net网络:U-Net结构的网络能预测去噪过程中的噪声,逐步构建出清晰的图像。图像解码器:用Sber-MoVQGAN的图像解码器从潜在表示重建图像。全局交互:在U-Net的早期阶段仅用卷积块处理潜在表示,后期阶段引入变换层,确保图像元素之间的全局交互。Kandinsky-3的项目地址项目官网:ai-forever.github.io/Kandinsky-3GitHub仓库:https://github.com/ai-forever/Kandinsky-3HuggingFace模型库:https://huggingface.co/kandinsky-community/kandinsky-3arXiv技术论文:https://arxiv.org/pdf/2410.21061Kandinsky-3的应用场景艺术创作:艺术家创作数字艺术作品,快速将创意转化为视觉图像。媒体与娱乐:在电影制作中,生成或增强概念艺术,帮助导演和美术指导预览场景。广告行业:设计个性化的广告图像,吸引目标受众提高广告效果。教育:作为教学辅助工具,帮助学生更直观地理解历史事件或科学概念。新闻与出版:为在线新闻网站和杂志创造吸引人的插图和信息图表。