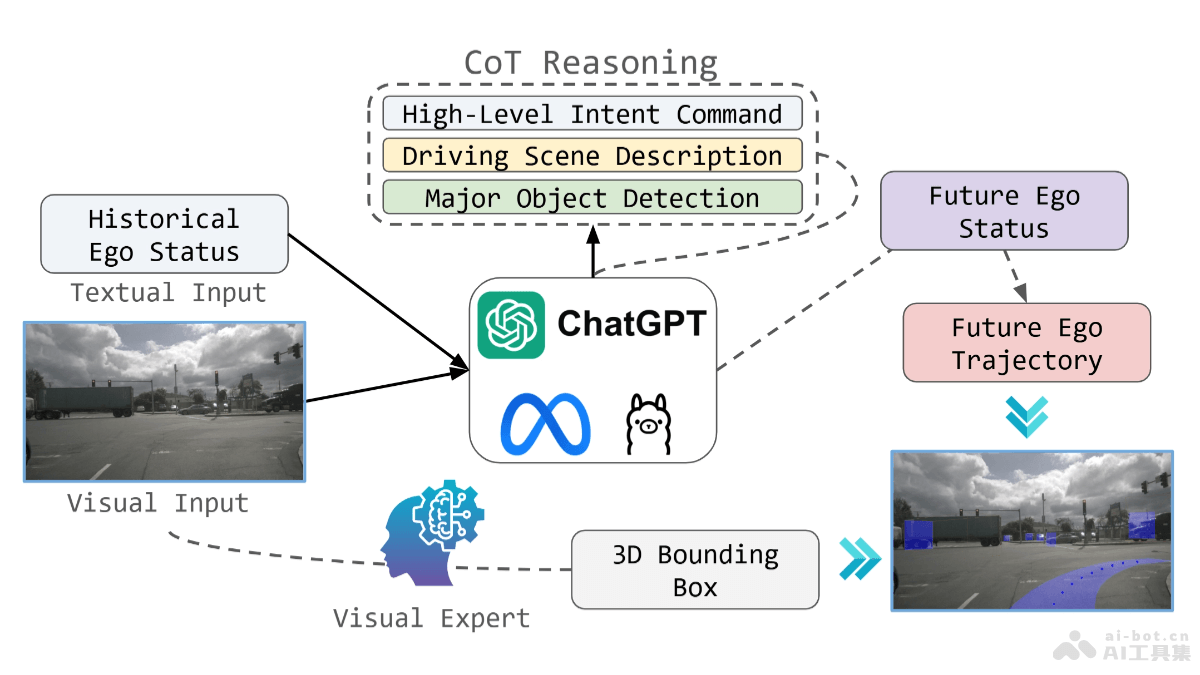
StoryTeller是字节跳动、上海交通大学和北京大学共同推出的系统,能基于音频视觉角色识别技术改善长视频描述的质量和一致性。系统结合低级视觉概念和高级剧情信息,生成详细且连贯的视频描述。StoryTeller由视频分割、音频视觉角色识别和描述生成三个主要模块组成,能有效处理数分钟长的视频,在MovieQA任务中展现出比现有模型更高的准确率,比最强基线Gemini-1.5-pro高9.5%的准确率。
 StoryTeller的主要功能视频分割:将长视频切割成多个短片段,保持每个片段的独立性和完整性。音频视觉角色识别:结合音频和视觉信息,识别视频中对话对应的角色。描述生成:为每个视频片段生成详细的描述,整合成整个长视频的连贯叙述。数据集构建:创建并使用MovieStory101数据集,提供长视频描述的训练和测试数据。自动评估:基于MovieQA,用GPT-4自动评估视频描述的准确性和质量。模型训练与微调:训练多模态大型语言模型,提高角色识别和视频描述的准确性。全局解码:确保同一角色在不同视频片段中保持一致的识别结果。StoryTeller的技术原理多模态融合:整合视觉(视频帧)、音频(对话)和文本(字幕和描述)信息,全面理解视频内容。音频分离和角色ID分配:用音频嵌入模型对每个对话进行嵌入,基于聚类算法分配全局ID,将相似的音频嵌入分配相同的ID,表示同一角色。音频视觉角色识别模型:用大型语言模型(如Tarsier-7B)结合OpenAI的Whisper-large-v2音频编码器,将每个音频ID映射到特定的角色。全局解码算法:在推理时,确保不同片段中相同角色的全局ID映射到一致的角色名称,提高角色识别的准确性。视频描述生成:用识别结果作为输入,基于大型语言模型生成每个片段的详细描述,并整合成完整的视频描述。StoryTeller的项目地址GitHub仓库:https://github.com/hyc2026/StoryTellerarXiv技术论文:https://arxiv.org/pdf/2411.07076StoryTeller的应用场景电影和视频内容制作:自动生成电影预告片或电影片段的描述,帮助导演和编剧快速理解视频内容。辅助视频编辑工作,基于视频描述快速定位视频中的关键片段。视频内容分析:在视频分析领域,提取视频内容的关键信息,如角色、情节和动作,进行深入的内容分析。辅助视障人士:为视障人士提供视频内容的音频描述,更好地理解视频内容和故事情节。教育和培训:在教育领域,为学生提供视频教材的详细描述,增强学习体验。在职业培训中,生成视频教程的详细步骤描述,提高培训效率。视频搜索和索引:提高视频搜索的准确性,基于视频描述快速检索视频中的相关片段。
StoryTeller的主要功能视频分割:将长视频切割成多个短片段,保持每个片段的独立性和完整性。音频视觉角色识别:结合音频和视觉信息,识别视频中对话对应的角色。描述生成:为每个视频片段生成详细的描述,整合成整个长视频的连贯叙述。数据集构建:创建并使用MovieStory101数据集,提供长视频描述的训练和测试数据。自动评估:基于MovieQA,用GPT-4自动评估视频描述的准确性和质量。模型训练与微调:训练多模态大型语言模型,提高角色识别和视频描述的准确性。全局解码:确保同一角色在不同视频片段中保持一致的识别结果。StoryTeller的技术原理多模态融合:整合视觉(视频帧)、音频(对话)和文本(字幕和描述)信息,全面理解视频内容。音频分离和角色ID分配:用音频嵌入模型对每个对话进行嵌入,基于聚类算法分配全局ID,将相似的音频嵌入分配相同的ID,表示同一角色。音频视觉角色识别模型:用大型语言模型(如Tarsier-7B)结合OpenAI的Whisper-large-v2音频编码器,将每个音频ID映射到特定的角色。全局解码算法:在推理时,确保不同片段中相同角色的全局ID映射到一致的角色名称,提高角色识别的准确性。视频描述生成:用识别结果作为输入,基于大型语言模型生成每个片段的详细描述,并整合成完整的视频描述。StoryTeller的项目地址GitHub仓库:https://github.com/hyc2026/StoryTellerarXiv技术论文:https://arxiv.org/pdf/2411.07076StoryTeller的应用场景电影和视频内容制作:自动生成电影预告片或电影片段的描述,帮助导演和编剧快速理解视频内容。辅助视频编辑工作,基于视频描述快速定位视频中的关键片段。视频内容分析:在视频分析领域,提取视频内容的关键信息,如角色、情节和动作,进行深入的内容分析。辅助视障人士:为视障人士提供视频内容的音频描述,更好地理解视频内容和故事情节。教育和培训:在教育领域,为学生提供视频教材的详细描述,增强学习体验。在职业培训中,生成视频教程的详细步骤描述,提高培训效率。视频搜索和索引:提高视频搜索的准确性,基于视频描述快速检索视频中的相关片段。