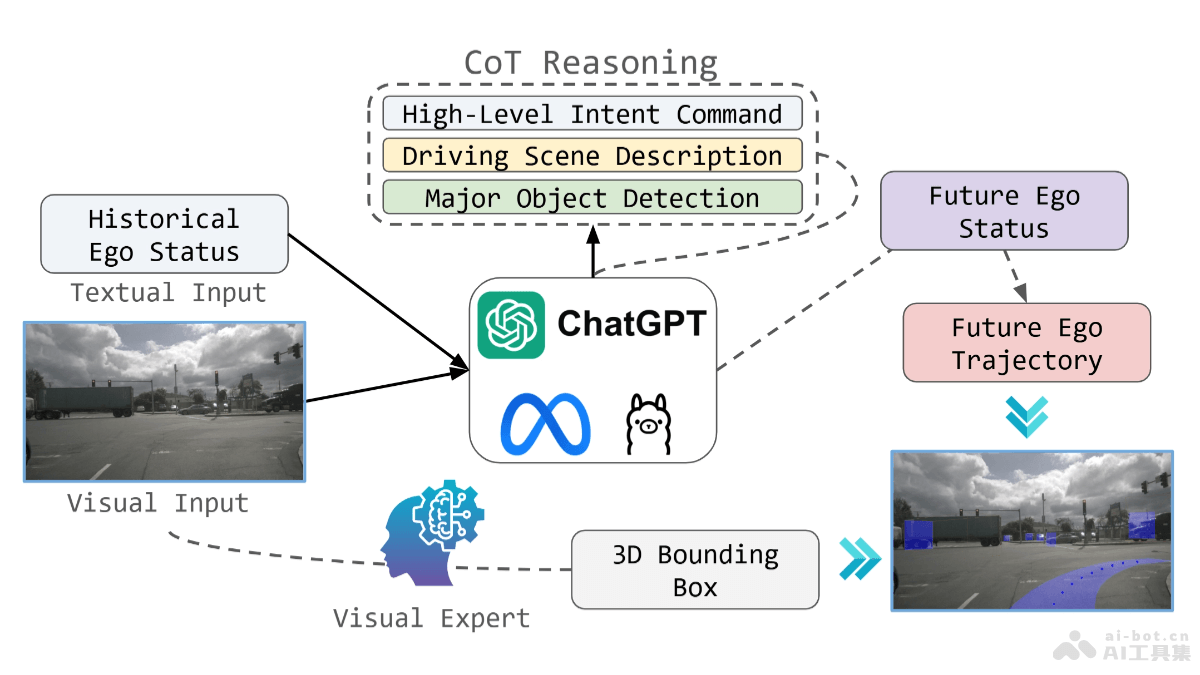
ACE(All-round Creator and Editor)是阿里巴巴集团Tongyi Lab推出的基于扩散变换器的全能图像生成和编辑模型。ACE引入长上下文条件单元(LCU)和统一条件格式,能理解和执行自然语言指令,实现广泛的视觉生成任务。ACE模型支持多模态输入,能处理包括图像生成、编辑和多轮交互在内的复杂任务,提供一个统一的解决方案,提高视觉内容创作的效率和灵活性。
 ACE的主要功能多模态视觉生成:A根据文本指令生成图像,支持多种视觉生成任务,如风格转换、对象添加或删除等。图像编辑:模型对现有图像进行编辑,包括语义编辑、元素编辑(如文本和对象的添加或移除)及重绘(inpainting)。长上下文处理:基于长上下文条件单元(LCU),理解和执行多轮对话中的图像编辑任务,保持对话历史的连贯性。数据收集与处理:采用高效的数据收集方法,基于合成或聚类流水线获取成对图像,用微调的大型多模态语言模型生成准确的文本指令。单模型多任务处理:避免视觉代理中使用的繁琐流程,用单一模型后端响应任何图像创建请求,提高效率。ACE的技术原理长上下文条件单元(LCU):引入LCU,一种统一的条件格式,能将历史信息和当前的文本指令结合起来,更好地理解用户的请求并生成期望的图像。基于Transformer的扩散模型:构建基于Transformer的扩散模型,模型用LCU作为输入,联合训练各种生成和编辑任务,提高模型的多任务处理能力。条件标记化(Condition Tokenizing):模型将文本指令和视觉信息(如图像和掩码)分别编码成序列,并合并处理,实现多模态信息的对齐。图像指示嵌入(Image Indicator Embedding):为确保文本指令中提到的图像顺序与CU中的图像序列相匹配,用预定义的文本标记指示图像顺序。长上下文注意力块(Long-context Attention Block):模块基于时间步嵌入(T-Emb)和3D旋转位置编码(RoPE)区分不同的空间和帧级图像嵌入,确保在自注意力和交叉注意力层中,文本嵌入和图像嵌入能逐帧对齐。ACE的项目地址项目官网:ali-vilab.github.io/ace-pageGitHub仓库:https://github.com/ali-vilab/ACE/arXiv技术论文:https://arxiv.org/pdf/2410.00086ACE的应用场景艺术创作与设计:艺术家和设计师生成或编辑图像,实现创意构想,提高创作效率。媒体与娱乐:在电影制作中,生成关键帧或辅助视觉效果的制作。在游戏开发中,快速原型设计和生成游戏资产。广告与营销:营销人员快速生成吸引人的广告图像和营销材料。教育与培训:教育工作者创建定制的教材和视觉辅助工具,增强学生的学习体验。电子商务:电商平台生成产品图像,或根据客户需求进行个性化的产品展示。
ACE的主要功能多模态视觉生成:A根据文本指令生成图像,支持多种视觉生成任务,如风格转换、对象添加或删除等。图像编辑:模型对现有图像进行编辑,包括语义编辑、元素编辑(如文本和对象的添加或移除)及重绘(inpainting)。长上下文处理:基于长上下文条件单元(LCU),理解和执行多轮对话中的图像编辑任务,保持对话历史的连贯性。数据收集与处理:采用高效的数据收集方法,基于合成或聚类流水线获取成对图像,用微调的大型多模态语言模型生成准确的文本指令。单模型多任务处理:避免视觉代理中使用的繁琐流程,用单一模型后端响应任何图像创建请求,提高效率。ACE的技术原理长上下文条件单元(LCU):引入LCU,一种统一的条件格式,能将历史信息和当前的文本指令结合起来,更好地理解用户的请求并生成期望的图像。基于Transformer的扩散模型:构建基于Transformer的扩散模型,模型用LCU作为输入,联合训练各种生成和编辑任务,提高模型的多任务处理能力。条件标记化(Condition Tokenizing):模型将文本指令和视觉信息(如图像和掩码)分别编码成序列,并合并处理,实现多模态信息的对齐。图像指示嵌入(Image Indicator Embedding):为确保文本指令中提到的图像顺序与CU中的图像序列相匹配,用预定义的文本标记指示图像顺序。长上下文注意力块(Long-context Attention Block):模块基于时间步嵌入(T-Emb)和3D旋转位置编码(RoPE)区分不同的空间和帧级图像嵌入,确保在自注意力和交叉注意力层中,文本嵌入和图像嵌入能逐帧对齐。ACE的项目地址项目官网:ali-vilab.github.io/ace-pageGitHub仓库:https://github.com/ali-vilab/ACE/arXiv技术论文:https://arxiv.org/pdf/2410.00086ACE的应用场景艺术创作与设计:艺术家和设计师生成或编辑图像,实现创意构想,提高创作效率。媒体与娱乐:在电影制作中,生成关键帧或辅助视觉效果的制作。在游戏开发中,快速原型设计和生成游戏资产。广告与营销:营销人员快速生成吸引人的广告图像和营销材料。教育与培训:教育工作者创建定制的教材和视觉辅助工具,增强学生的学习体验。电子商务:电商平台生成产品图像,或根据客户需求进行个性化的产品展示。