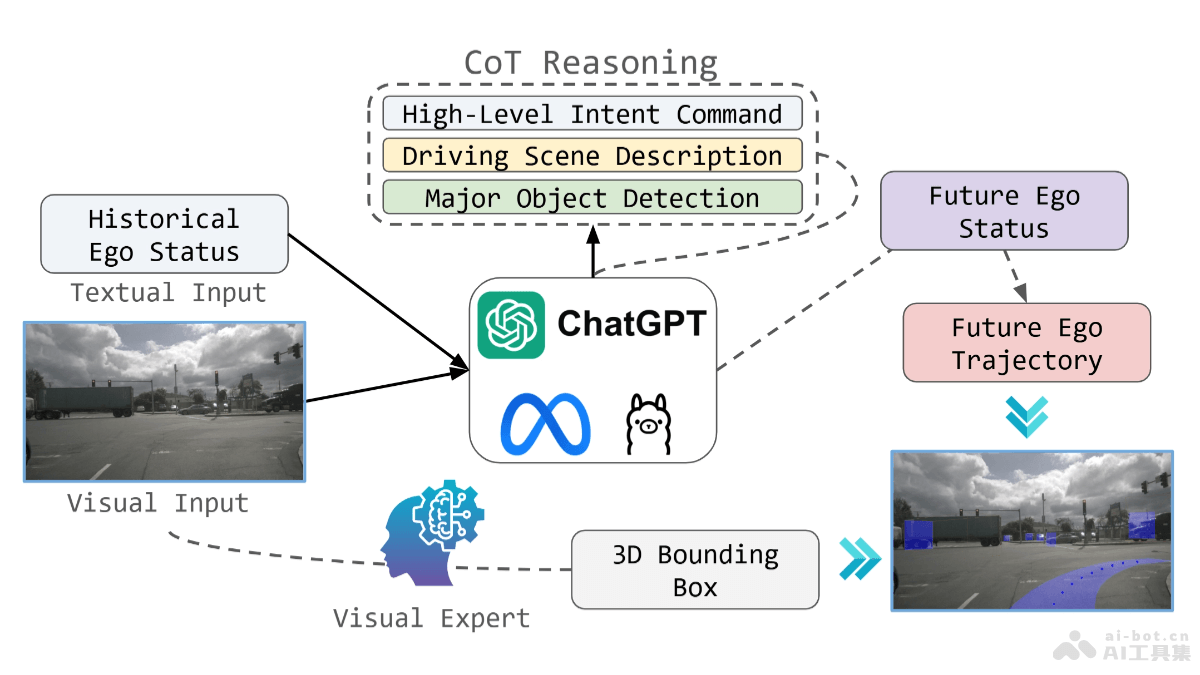
Optima是清华大学推出的优化基于大型语言模型(LLM)的多智能体系统(MAS)的框架。基于一个迭代的生成、排名、选择和训练范式,显著提高通信效率和任务效果。Optima平衡了任务性能、令牌效率和通信可读性,探索了多种强化学习算法,并集成蒙特卡洛树搜索技术生成高质量的训练数据。在多智能体任务中,Optima展示超越单智能体基线和传统MAS的性能,实现了高达2.8倍的性能提升,并减少令牌使用。Optima的效率提升为更有效的推理计算和改进的推理时间扩展法则提供新的可能性。
 Optima的主要功能通信效率提升:O优化多智能体系统(MAS)中的智能体间通信,减少完成任务所需的令牌(token)数量,提高通信效率。任务性能增强:基于迭代训练和奖励函数的平衡,提升智能体在复杂任务中的表现,包括信息不对称问答和复杂推理任务。可扩展性:支持MAS在处理更大规模和更复杂的任务时保持有效性,提高系统的可扩展性。推理时间扩展法则改进:减少令牌使用,为改进推理时间扩展法则提供可能性,有助于在更低的计算成本下实现更好的性能。Optima的技术原理迭代训练范式:基于迭代的生成(generate)、排名(rank)、选择(select)和训练(train)范式,逐步优化智能体的行为。奖励函数:设计奖励函数,平衡任务性能、令牌效率和通信可读性,引导智能体在保持通信效率的同时完成任务。强化学习算法:探索包括监督式微调(SFT)、直接偏好优化(DPO)及混合方法在内的多种强化学习算法,优化智能体的行为。蒙特卡洛树搜索(MCTS):集成MCTS启发式技术,将对话轮次视为树节点,探索多样化的交互路径,生成高质量的DPO训练数据。多目标优化:基于奖励函数同时考虑多个目标,在提升任务性能的同时,注重通信效率和输出的可解释性。Optima的项目地址项目官网:chenweize1998.github.io/optima-project-pageGitHub仓库:https://github.com/thunlp/OptimaarXiv技术论文:https://arxiv.org/pdf/2410.08115Optima的应用场景信息不对称问答:在问答系统中,当问题的答案需要整合多个来源的信息时,优化智能体间的沟通提高答案的准确性和响应速度。复杂推理任务:对于需要多步骤推理的问题,如法律案例分析、科学问题解答等,帮助智能体更有效地协作,得出正确的结论。软件开发:在软件开发中,协调不同功能模块的开发,基于智能体间的有效沟通优化开发流程和提高代码质量。决策支持系统:在商业决策或政策制定中,帮助多个决策者或智能体共享信息、讨论方案,达成共识。多智能体游戏:在需要多个玩家或智能体协作的游戏中,优化玩家间的沟通策略,提高团队合作效率。
Optima的主要功能通信效率提升:O优化多智能体系统(MAS)中的智能体间通信,减少完成任务所需的令牌(token)数量,提高通信效率。任务性能增强:基于迭代训练和奖励函数的平衡,提升智能体在复杂任务中的表现,包括信息不对称问答和复杂推理任务。可扩展性:支持MAS在处理更大规模和更复杂的任务时保持有效性,提高系统的可扩展性。推理时间扩展法则改进:减少令牌使用,为改进推理时间扩展法则提供可能性,有助于在更低的计算成本下实现更好的性能。Optima的技术原理迭代训练范式:基于迭代的生成(generate)、排名(rank)、选择(select)和训练(train)范式,逐步优化智能体的行为。奖励函数:设计奖励函数,平衡任务性能、令牌效率和通信可读性,引导智能体在保持通信效率的同时完成任务。强化学习算法:探索包括监督式微调(SFT)、直接偏好优化(DPO)及混合方法在内的多种强化学习算法,优化智能体的行为。蒙特卡洛树搜索(MCTS):集成MCTS启发式技术,将对话轮次视为树节点,探索多样化的交互路径,生成高质量的DPO训练数据。多目标优化:基于奖励函数同时考虑多个目标,在提升任务性能的同时,注重通信效率和输出的可解释性。Optima的项目地址项目官网:chenweize1998.github.io/optima-project-pageGitHub仓库:https://github.com/thunlp/OptimaarXiv技术论文:https://arxiv.org/pdf/2410.08115Optima的应用场景信息不对称问答:在问答系统中,当问题的答案需要整合多个来源的信息时,优化智能体间的沟通提高答案的准确性和响应速度。复杂推理任务:对于需要多步骤推理的问题,如法律案例分析、科学问题解答等,帮助智能体更有效地协作,得出正确的结论。软件开发:在软件开发中,协调不同功能模块的开发,基于智能体间的有效沟通优化开发流程和提高代码质量。决策支持系统:在商业决策或政策制定中,帮助多个决策者或智能体共享信息、讨论方案,达成共识。多智能体游戏:在需要多个玩家或智能体协作的游戏中,优化玩家间的沟通策略,提高团队合作效率。