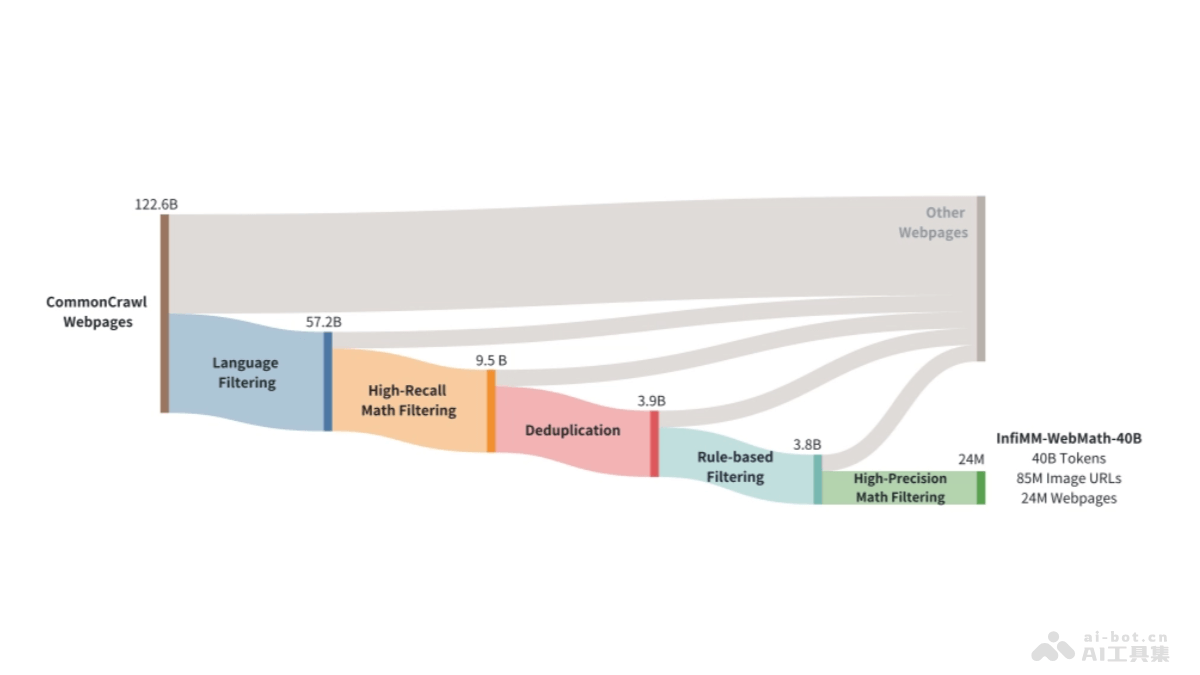
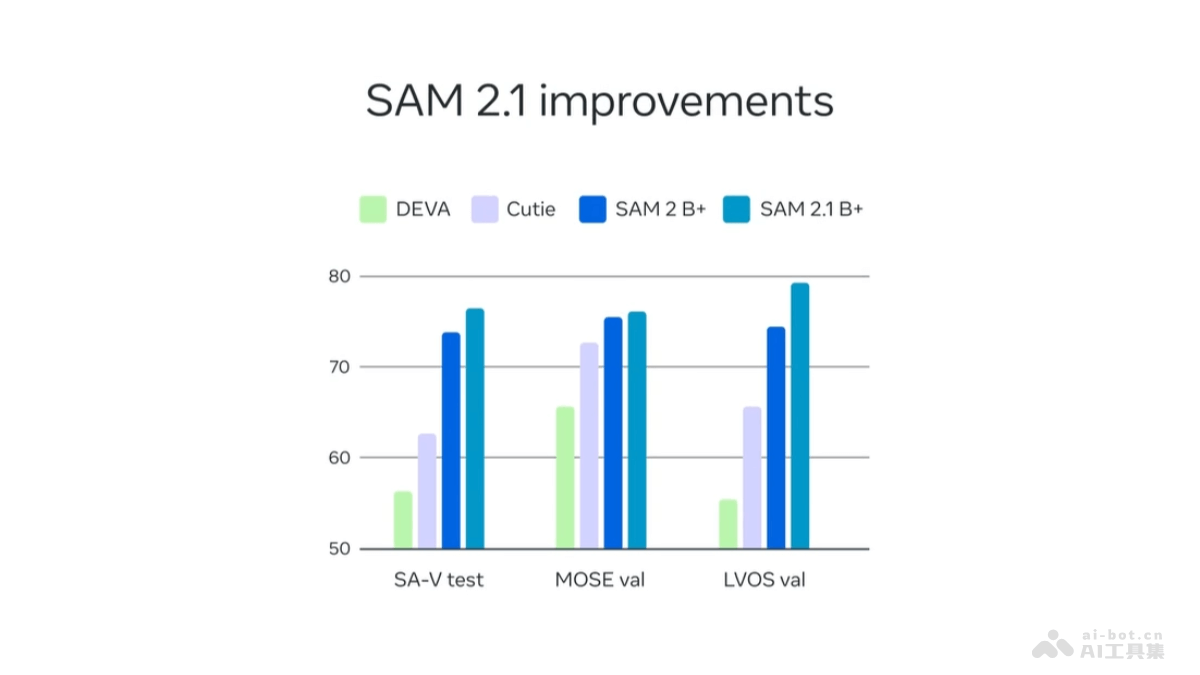
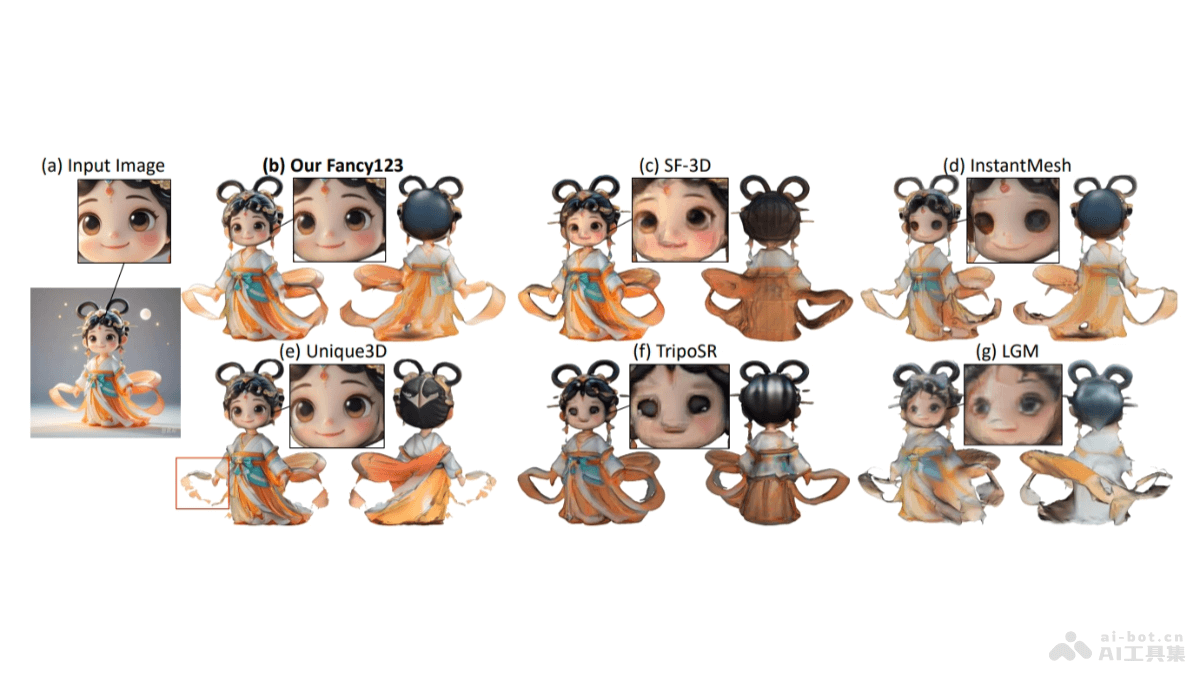
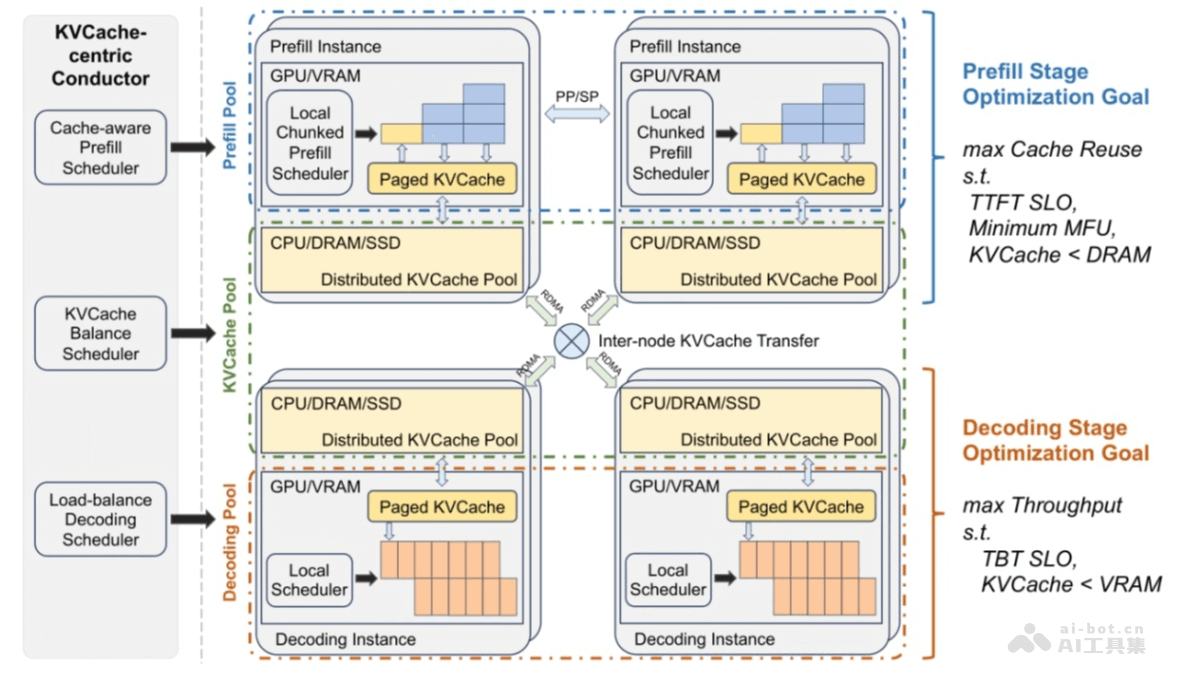
Find3D是加州理工学院推出的3D部件分割模型,能根据任意文本查询分割任意对象的任何部分。Find3D用一个强大的数据引擎自动从互联网上的3D资产生成训练数据,并用对比训练方法训练一个可扩展的3D模型。Find3D在包括Objaverse-General、ShapeNet-Part和PartNet-E在内的多个数据集上展现出色性能,实现高达3倍于次佳方法的平均交并比(mIoU)提升,能处理来自iPhone照片和AI生成图像的野外3D构建。
 Find3D的主要功能开放世界3D部分分割:识别和分割任何物体的任何部分,只需用文本查询即可,不受预定义部分集的限制。无需人工注释:用数据引擎自动从互联网上的3D资产生成训练数据,无需人工注释。高性能与泛化能力:在多个数据集上表现出色,与次佳方法相比,平均交并比(mIoU)提高3倍。快速推理:比现有基线快6到300倍,显著提高推理速度。鲁棒性:在不同的物体姿态和查询条件下保持稳定的分割效果。查询灵活性:支持不同类型的文本查询,包括不同粒度和描述风格的部分查询。Find3D的技术原理数据引擎:用2D基础模型(如SAM和Gemini)自动注释3D对象。将3D资产渲染成多个视图,每个视图传递给SAM进行分割。对于SAM返回的每个掩码,查询Gemini以获取相应的部分名称,形成(掩码,文本)对。将部分名称嵌入到视觉和语言基础模型(如SigLIP)的潜在嵌入空间中。基于投影几何将掩码反投影到3D点云中,形成(点,文本嵌入)对。模型训练:基于Transformer的点云模型,该模型将点云视为序列,并执行块注意力。模型返回的点特征与文本嵌入的余弦相似度进行任何自由形式文本的查询。用对比学习目标处理标签的多义性和部分可见性问题,支持在数据引擎生成的数据上进行可扩展训练。对比学习目标:解决每个点具有多个标签的问题,及由于每个掩码只覆盖部分视图而导致的未标记点问题。基于对比学习目标,让模型能学习到鲁棒的特征表示,在开放世界中实现准确的部分分割。Find3D的项目地址项目官网:ziqi-ma.github.io/find3dsiteGitHub仓库:https://github.com/ziqi-ma/Find3DarXiv技术论文:https://arxiv.org/pdf/2411.13550v1在线体验Demo:https://huggingface.co/spaces/ziqima/Find3DFind3D的应用场景机器人视觉与操作:在机器人领域,帮助机器人识别和定位物体的特定部分,进行精确的抓取、操作或交互。虚拟现实(VR)和增强现实(AR):在VR/AR应用中,提供对虚拟物体的更深层次理解,增强用户与虚拟环境的交互体验。计算机辅助设计(CAD):在CAD软件中,帮助设计师快速识别和编辑3D模型的特定部分,提高设计效率。游戏开发:在游戏开发中,创建更复杂的3D物体交互,如角色装备的更换或物体的破坏效果。建筑和工程:在建筑和工程领域,帮助分析和理解复杂的3D结构,如建筑模型或机械部件。
Find3D的主要功能开放世界3D部分分割:识别和分割任何物体的任何部分,只需用文本查询即可,不受预定义部分集的限制。无需人工注释:用数据引擎自动从互联网上的3D资产生成训练数据,无需人工注释。高性能与泛化能力:在多个数据集上表现出色,与次佳方法相比,平均交并比(mIoU)提高3倍。快速推理:比现有基线快6到300倍,显著提高推理速度。鲁棒性:在不同的物体姿态和查询条件下保持稳定的分割效果。查询灵活性:支持不同类型的文本查询,包括不同粒度和描述风格的部分查询。Find3D的技术原理数据引擎:用2D基础模型(如SAM和Gemini)自动注释3D对象。将3D资产渲染成多个视图,每个视图传递给SAM进行分割。对于SAM返回的每个掩码,查询Gemini以获取相应的部分名称,形成(掩码,文本)对。将部分名称嵌入到视觉和语言基础模型(如SigLIP)的潜在嵌入空间中。基于投影几何将掩码反投影到3D点云中,形成(点,文本嵌入)对。模型训练:基于Transformer的点云模型,该模型将点云视为序列,并执行块注意力。模型返回的点特征与文本嵌入的余弦相似度进行任何自由形式文本的查询。用对比学习目标处理标签的多义性和部分可见性问题,支持在数据引擎生成的数据上进行可扩展训练。对比学习目标:解决每个点具有多个标签的问题,及由于每个掩码只覆盖部分视图而导致的未标记点问题。基于对比学习目标,让模型能学习到鲁棒的特征表示,在开放世界中实现准确的部分分割。Find3D的项目地址项目官网:ziqi-ma.github.io/find3dsiteGitHub仓库:https://github.com/ziqi-ma/Find3DarXiv技术论文:https://arxiv.org/pdf/2411.13550v1在线体验Demo:https://huggingface.co/spaces/ziqima/Find3DFind3D的应用场景机器人视觉与操作:在机器人领域,帮助机器人识别和定位物体的特定部分,进行精确的抓取、操作或交互。虚拟现实(VR)和增强现实(AR):在VR/AR应用中,提供对虚拟物体的更深层次理解,增强用户与虚拟环境的交互体验。计算机辅助设计(CAD):在CAD软件中,帮助设计师快速识别和编辑3D模型的特定部分,提高设计效率。游戏开发:在游戏开发中,创建更复杂的3D物体交互,如角色装备的更换或物体的破坏效果。建筑和工程:在建筑和工程领域,帮助分析和理解复杂的3D结构,如建筑模型或机械部件。